概要
ニューラルポケットは、正常品と異常品を高精度で判別する画像分析アルゴリズムを開発し、国際学会ACPRにて発表しました。複数のオープンデータセットによる評価で、世界最高の異常画像検出精度を達成しています。
正常品と異常品を画像から識別するアルゴリズムは、工場や農業、インフラ管理などの幅広い領域において活用が進められており、属人的な作業を機械化することによる、見逃し率の低減や作業の効率化などに、大きな期待が寄せられています。
この領域においては、従来、正常品とのパターンマッチングを中心としたアプローチが主流でしたが、近年、深層学習を用いたアプローチが広まり、正常品の中でも形状変化が大きい、食品や柔らかい素材の部品など含め、幅広く活用することが出来るようになってきました。
本手法は、その発展として開発されたものであり、以下のような特徴を持ちます:
- 従来の手法では大量に必要となっていた異常画像を大きく減らし、数枚とごく少量あっても学習モデルの構築が可能
- 特に検出したい異常モードについては、数枚の異常画像を登録することで、感度を上げることが可能。その他、実際の利用に応じたカスタマイズも容易
ニューラルポケットでは、本手法の活用を進め、工場や農業、インフラ管理など、これまで困難だった分野のスマート化を進めて参ります。
以下、論文の概略の紹介になります。技術的な内容に興味のある方はぜひご覧ください。
技術紹介
画像異常検知における課題
例えば、ケーブル被覆のキズの検知を異常の例として取り上げます。
この時、画像による異常検知を行おうとすると、以下のような問題が発生します:
- 正常品の形状が大きく変化するため、パターンマッチによる判定を行うことが困難
- キズなのか、印刷された文字・パターンなのかの判別が困難
- 近年の製造技術の向上により、異常品のデータがそもそも取得しづらい (正常品の数は多い)
同様の問題は、形状が変化するパーツを製造するときには一般的に発生します。また、農業など生産品の形状をコントロールできないような産業でも起こるため、異常検知の自動化の文脈においては、かねてより大きな課題となっていました。
解決のアプローチ
上記の問題を解決するために、我々はGAN(Generative Adversarial Network; 敵対的生成ネットワーク)を異常検知に応用しました。
GANとは、大量のデータの学習から、そのデータ全体の特徴を捉えた新しい画像を生成することができるフレームワークです。
【参考】 GAN 敵対的生成ネットワークの台頭【前編】 | AI専門ニュースメディア ainow.ai › 2019/07/17
https://ainow.ai/2019/07/17/173382/
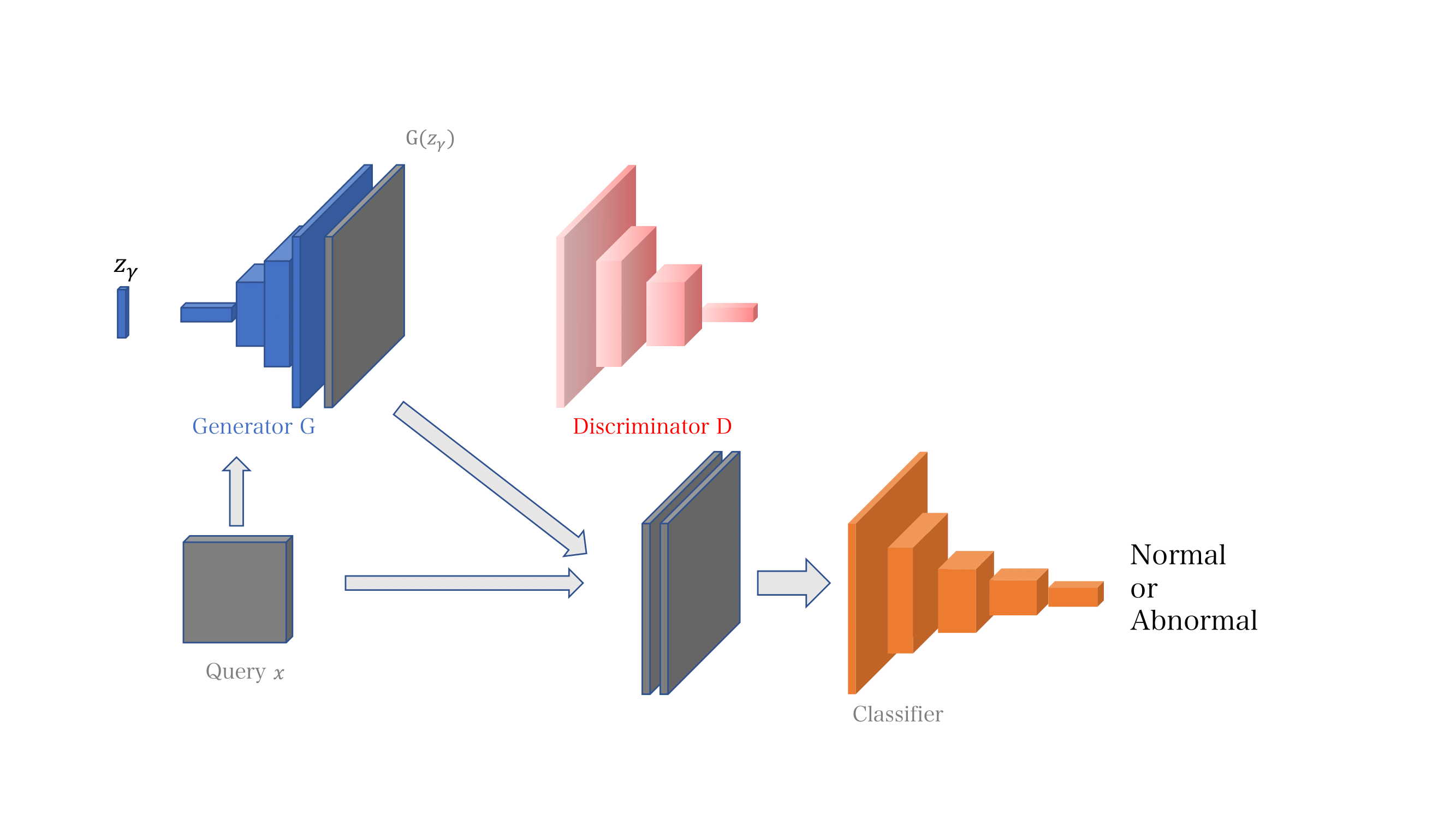
まずGANに正常データを学習させます。これによりニューラルネットは「正常データの画像」を一般的に生成する能力を獲得します。
今、異常画像を入力したときに、このGANを用いて、「異常画像にできるだけ類似した正常画像」を生成させます。ところが、このGANは、正常画像しか生成できないので、異常画像の中に含まれる「キズ」や「欠け」などの箇所は再現できません。つまり、入力された異常画像と、この生成画像を比較することで、「キズ」や「欠け」を逆に浮き立たせることが可能です。
上記までは、これまでも複数の文献にて提案されていた概念ですが、本手法においては、新規性の一つとして、GANが持つ豊かな表現能力の中に、異常画像に似たものが含まれないよう明示的に制約をかける工夫をしています。少数の異常画像を登録しておくと、それに近い画像をGANが生成した場合に罰則を受けるような構造としており、異常検知性能の向上に貢献しています。
入力された異常画像と生成画像の比較を行うアルゴリズムにも工夫があります。
異常画像と生成画像を比較する際、これまでの手法では単純なピクセル輝度差を用いていることが多かったのですが、これは画面全体の輝度差やノイズなどの違いによって大きく影響を受け、異常画像の検知性能の低下を招いていました。
本手法では、異常画像と生成画像を見比べ、画面全体の輝度差やノイズなどとは異なる形状差を明示的にパターン認識させるようなモデルを導入しています。これにより、異常画像と正常画像を精度良く分離することが可能になっています。
論文の中では他の方が検証可能なように、オープンデータセットを用いた評価を行っています。
手書き文字のデータセットを用いた場合の、異常・正常識別結果が以下になります。
上側はベンチマークとした類似手法、上側は本手法によるもので、正常・異常クラスが作る分布の重なり部分が小さくなり、分類精度が向上していることが分かります。

これらの手法の組み合わせにより、過去の複数のベンチマークを更新し、世界最高の異常検知精度を達成しています。