初めに
今回の記事に関しては、あくまで思いついた考察をある程度理論を踏まえて説明するものです。そのため、もしかすると間違っているかもしれないし、すでに論文として出ているかもしれない。それらを踏まえて読む人には読んでほしく、意見や間違っている箇所があればコメントで教えてほしいと思います。
今回の考察は、生成AIが生成したものに対してなぜ違和感を感じることがあるのか、「これAIが作ったものじゃないと」と思うことがあるのはなぜかを考察したものです。AIだからという理由で済ませられてしまうことが多いため、なぜAIだと違和感を感じるのかを少し深く考えてみたものになります。ただ、証明する方法を思いつかなかったので考察にとどめているものです。
AI、機械学習の簡単な仕組み
簡単に
まず初めに考察に関して説明する前にAI、機械学習の簡単な仕組みを自分の理解の範囲で説明していきたいと思う。(間違ってたらごめんなさい)
一言で表すと「観測データ集合Dの事後分布から、そのデータのもととなる母集団の事前分布を予測する」ことと考えられます。
どういうことかというと、我々がよく使う売り上げ予測(需要予測)や貸し倒れ先予測、退職予測などでは基本的にすでに集まっているデータを使用してAIモデルを学習させて、将来得られる未知のデータに対して予測を行います。つまり、すでに得られているデータ集合から背後にある母集団の事前分布を予測できるようなモデルを構築して、それを使用することで同じ母集団から生成されているであろう将来のデータを予測するというアプローチになっています。
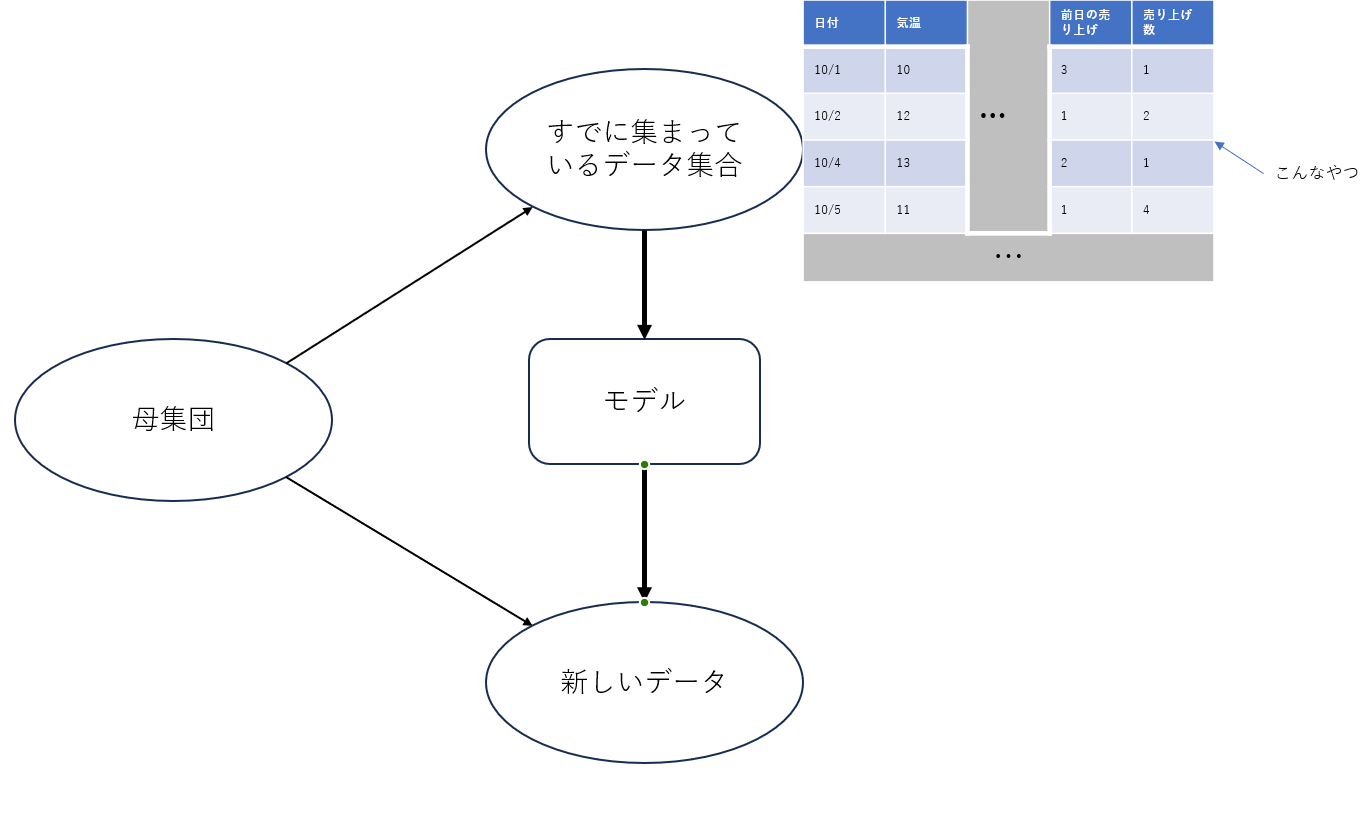
しかしながら、我々が予測をしたいと思う対象(例えば、売り上げや退職者、貸し倒れ先e.t.c)は基本的に母集団の部分がとてつもなく大きいためすべてのデータを集めることは不可能であることが多い。そのため、機械学習のモデルを構築する際にはいろいろなアプローチによって精度を高めようとするのである。
この辺りをさらにしっかり学びたいのではPRMLなんかを読むといいと思います
少し確率論ぽく
少し確率論ぽく説明(あくまでぽく)すると、以下の確率分布に従う母集団があるとする。
p(x)
AIで機械学習モデルを作ることを考えると、${x}$の生成に関わっているいろいろなデータ${D}$を考えると以下のようにも書ける。
p(x|D)
このデータから生成された${x}$の観測データと、それに関連していると思われる各種データ集合$\mathbf{D}_{know}^{'}$を持っているとする。そのデータは以下のような条件付確率分布に従っていると考えることができる
p(x|\mathbf{D}_{know}^{'})
ここでデータ集合を${`}$としているのは、ある${x}$に関わるパラメータのデータ集合をすべて観測することは現実的に不可能だからである。
ここである、未知の観測データ集合である$\mathbf{D}_{unknown}^{'}$が得られたとする。この時の対応する${x}$を予測したいと考える。母集団の分布がわかっていれば、それを当てはめて正確に${x}$がとりうる値の範囲を予測することができるが、我々が予測したいと思う事柄に関しては母集団の規模がとてつもなく多い(つまり、母集団のサイズ${N}$が限りなく${∞}$に近い)ことが多くこの方法をとることができない。そのため我々は、観測されているデータをいろいろな機械学習モデルに学習させることによって母集団の分布に近い予測をしてくれるモデルを作成している。
生成AIに対して考えてみる
生成AIも同じアプローチで説明することを考えてみようと思う。
LLMではどうなってる?
まずは広く使われていて、人間との比較も考えやすいLLMで考えてみる。
LLMが文章を生成する過程を見てみると、まずモデルに対してプロンプトを使用してどのような文章を出力してほしいか指示を出します。その指示を踏まえて文章を出力しているわけです。この動きを、確率分布的に考えてみたいと思います。ここで、自然言語処理を触ったことがある方やLLMのファインチューニングを実施したことがある方ならわかると思うが、基本的に機械学習の文脈において文章を学習させる際には単語ごとに分割(分かち書き)して保持することになる。そのため、出力した文章も単語のつながりであると考えられる。
今、あるLLMから生成された${N}$個の単語で構成された文章の${n}$番目の単語を以下のように置く
{x}_{n}\:(0<n \leq N)
この${x}_{n}$がとりうる単語の確率分布は以下のような条件付確率で表すことが可能であると考えられる。
p({x}_{n}|Input,\,{x}_{n+1},\,{x}_{n-1})
まず${Input}$に関しては、入力されたもの全般を表している。これは、モデルのどの部分を見るかによって変わってくるが、基本的なモデルを考えると文章を分かち書きしてエンコードしたものや、Transformerによるattentionの結果などが考えられる。
また、その後ろに${n-1}$番目と${n+1}$番目の${x}$が条件として入っているが、これはモデルによって変わってくる。例えばOpenAI社のGPTであれば前から後ろへしか考慮しないため${n-1}$のみになるだろうし、Google社のBertのように前後だけでなく文章全体を考慮するのであれば自分の位置${n}$を除く${1\sim N}$が入ってくることになると考えられる。
これを踏まえて、出力されている文章が出力される確率は以下で考えることができる。(これあってるのか?)
p({x}_{1}|Input,\,{x}_{2})p({x}_{N}|Input,\,{x}_{N-1})\prod_{n=2}^{N-1} p({x}_{n}|Input,\,{x}_{n+1},\,{x}_{n-1})
これは、ある意味AIが文章を書く時の言葉選びとしてとらえることができると考えられる。
また、${x}_{n}$がとりうる単語は無限ではないはずなので離散型の分布になるはずである。(多分ね)
画像についても考えてみよう
画像についても同じように考えることができる。
RGBで画像を生成することを考える。
あるサイズ${W×H}$の画像の${w}, {h}$の部分の画素のRGBそれぞれの要素がとる値を以下のように考える
\displaylines{
{r}_{w\,h},\;{g}_{w\,h},\;{b}_{w\,h} \\
(0<w\leq W,\,0<h\leq W, \,0\leq r,g,b\leq 255)
}
今回はRGBで考えているのでそれぞれの要素は0から255までの値しかとらないことに注意。
この時に、ある生成された画像の${w}, {h}$の部分画素における各要素がとりうる値の確率は以下のようにあらわすことができると考える。
p({r}_{w,h}\;{g}_{w,h}\;{b}_{w,h}|Input,\,r,g,b)
ここで${Input}$に関してはプロンプトや入力に使用した画像などがあげられる。
また、${r},{g},{b}$とまとめた部分に関しては${w}, {h}$の画素以外のすべての画素の各要素と考える。
このことから、先ほどのLLMの時のようにある画像が生成される確率は以下で表されると考えられる。
\prod_{w=1}^W\prod_{h=1}^Hp({r}_{w,h}\;{g}_{w,h}\;{b}_{w,h}|Input,\,r,g,b)
本題
ここから、実際にどういう考察を考えたかを述べていきたいと考える。
違和感の正体は何なのか
先ほどの文章が生成される確率は、人が文章を作る場合にも同じことが考えられる。つまり、人が文章を作る際の言葉選びはそれまでの経験や話題、何を話したいのか、どこまで話したかによる確率分布と考えることができる。
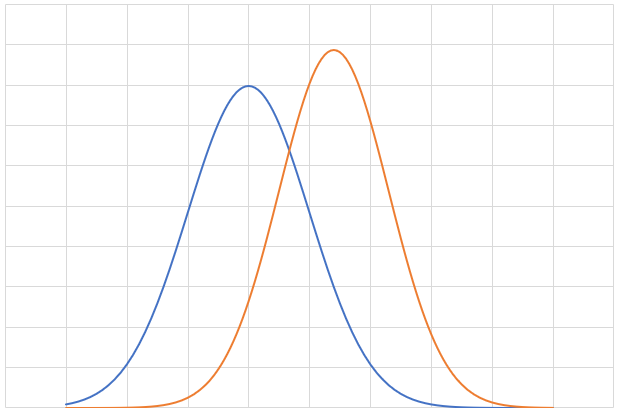
そのため、AIが生成したものに対して違和感を感じることがあるのは読んだ人が持っている確率分布とAIが生成した文章の確率分布にずれが生じている結果発生していると考えられる。(下はイメージ図、実際の分布はこんなきれいにはならないと考えられる。)
これは、画像生成などでは特に顕著に出ていることがある。画像を生成させた際に、人の指が6本あるとか足が3本あるといったことが発生することがある。これは、先ほどの考察に合わせて考える場合、見ている人からするとその部分に指や足が来る確率は${0}$であるが、AIからするとその部分はその色になる確率が高い結果、指が6本あったり足が3本あったりすることがあるわけである。
実際、人を書いてる絵や写真などでは足や指は重なっていることが多いためそうなってしまうのも無理はないと考えられる。
前回の検証に対して
今回の考察から前回の検証の結果と対策に対しても理由付けをすることができる。
前回の検証では、文章のカテゴリーを絞った検証に対してはAIの生成した文章と人の作成した文章をうまく分類することができたが、カテゴリーを絞らずにデータを増やすと上手く分類できなくなってしまうといった結果であった。また、この結果の対策に関して文章をカテゴリーに分けてvalidationを分けていけば改善すると考えた。これに関しては、以下のように今回の考察をもとに考えられる。
例えば、動物に関する人の作成した文章の確率分布と植物に関するAIの生成した文章の確率分布が似ているといったことがいくつかのカテゴリーにおいて発生していた場合に、それらを学習させてしまうと上手く分類できなくなることが考えられるのである。
最後に
今回の考察は、PRMLを読みながら思いついたものである。実際この分野に関して研究をしているわけではないので、この考察に関しても抜け多いとは思うが自分でこの考え方がしっくり来たので、今回まとめておくことにした。
これらを踏まえて、生成AIをすべての人間が違和感を感じないものを生成する形にできるのかを考えたとき、人類が70億人いてこれまでに人が作成してきた膨大な文章があり、Facebookやtwitter、などいろいろな発信ツール(Qiitaしかり)がある以上それは不可能に近いんだろうなと思いつつ、だからこそこういったAIを作ったりチューニングして社会実装していく仕事はなくならないんだろうなと思う。
これらの考察は、あくまで個人が思いついただけのものであるので、これの論文や間違っている部分などがあればコメントなどで教えてほしい。