昔からやりたいなーと思ってたことを最近始めたので、備忘録としてやってきたことと今後やっていくことをメモがてら書いていく。
生活アシスタントを作る
前々から、せっかくエンジニアになったから何か使えるものを作りたいなぁーと思っていた。ただ、何を作るのかが思いつかず、結局何も作らないまま1年半ほどが過ぎた頃に「なんか、その日の天気とかそういった情報をパソコンつけたときに喋ってくれるものが欲しいなぁ」と思った。Alexaとかでもいい(実際、話をした会社の同僚なんかには言われた)かもしれないが、せっかく喋ってもらうなら前々から気になってたCeVIO AIを使って作ろうと思い。小春六花のトークスターターパックを買い作成を開始。将来的には、センサーなんかで起きたかどうかや帰宅なんかを検知して動くようにしていきたいが、いったんはPCの起動時とかで作っていこうと思う。
PythonからCeVIO AIを叩く
最初にPythonからCeVIO AIを叩くための関数から作っていく。
GUIでの実行とPythonからの実行の違い
関数を作るに当たって、どのようにCeVIO AIを実行する際に各パラメーターを渡す必要があるのか、GUIからの実行とPythonから実行で違う部分が何かを色々調べてみた。結果としては、以下の部分がおそらく違うと思われる。
- GUI上で分けて入力した文章は、文章と文章の間をいい感じに調整してくれるが、Pythonから実行した場合は間が開かず、連続実行されてるっぽい。
- パラメータを数値として渡さなくてもデフォルト値で実行されるが、設定の違う文章を複数渡すとき、後の文章にパラメーターを設定しなかった場合、1つ前のパラメーターが引き継がれる。
- 音素に関しては、要素は取得できるがおそらく調整できないのでGUIで行えるような細かい調整はできない。
- パラメーターの設定値がGUIとは違い、すべて0~100で設定するため同じパラメータで実行できるように計算する必要がある。
以上のことがわかった。これを踏まえて、全体的なシステムの構成をどうしていくかを考える。
全体の構成
とりあえず、全体的なシステムの構成は以下の感じ
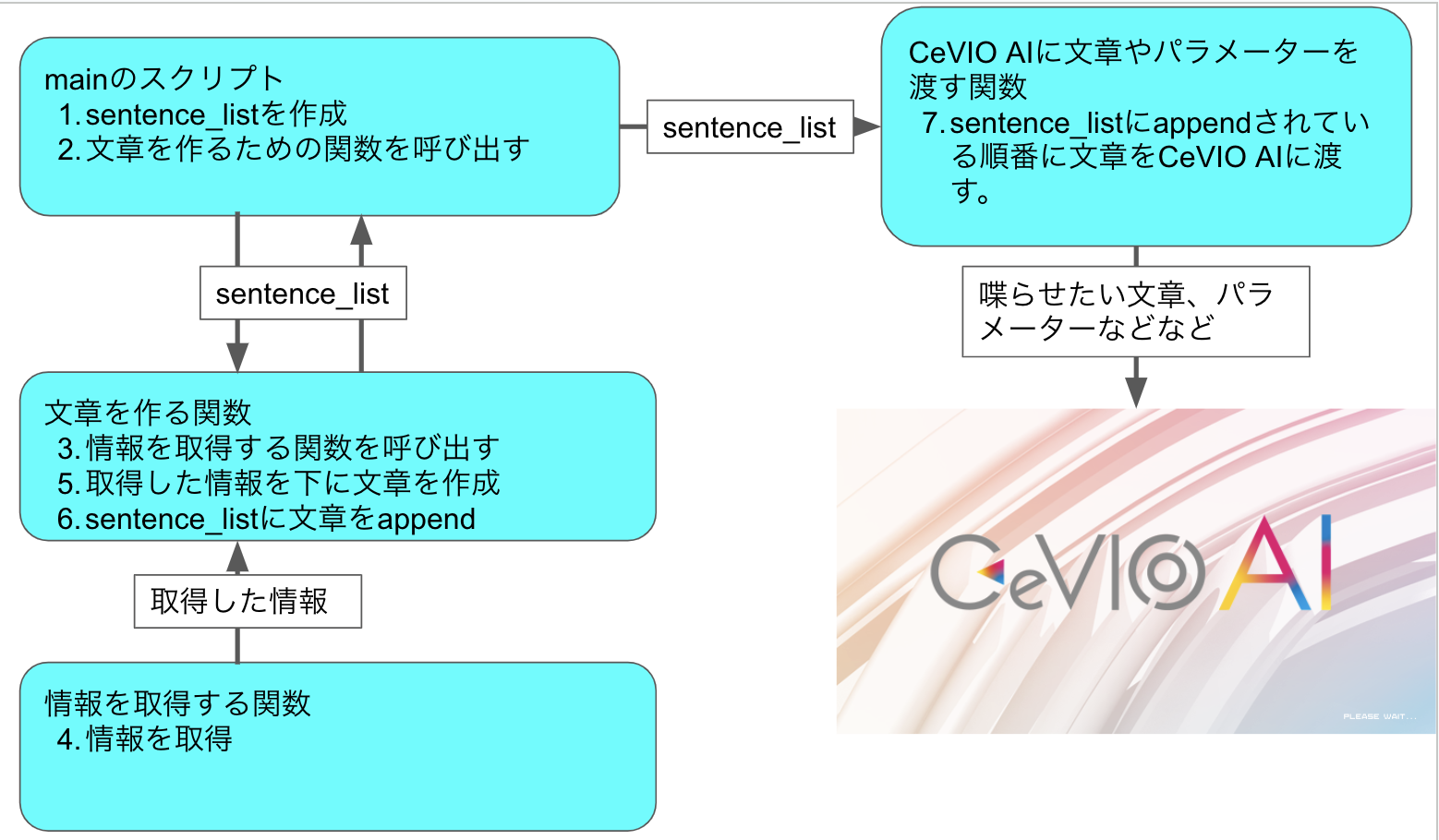
mainのスクリプトを、batファイルを使ってwindowsのstart upやタイムスケジューラーなんかを使って実行させることでPC起動時と指定時間に欲しい情報を喋ってくれるシステムを構築していく。
実際の関数
ここからは、実際に作ったコードを表示して説明していく。
Pythonを使ってCeVIO AIを喋らせる方法は、調べれば色々出てくるので詳しくは省略するがwin32comというモジュールを使用して実行する。コードをいかに記述する。
import win32com.client
import time
import sounddevice as sd
import soundfile as sf
def play_sound(path):
sig, sr = sf.read(path, always_2d=True)
sd.play(sig, sr)
sd.wait()
def cevio_talk(sentence_list):
# 接続設定
cevio = win32com.client.Dispatch("CeVIO.Talk.RemoteService2.ServiceControl2")
cevio.StartHost(False)
talker = win32com.client.Dispatch("CeVIO.Talk.RemoteService2.Talker2V40")
for sentence in sentence_list:
# dictの最初がsentenceの場合は文章を喋らせる
if list(sentence.keys())[0]=='sentence':
# キャストを設定
talker.Cast = sentence['talker']
# talk_parameterを設定
for param, value in sentence['talk_param_dict'].items():
if param == "Volume":
talker.Volume = value
elif param == "Speed":
talker.Speed = value
elif param == "Tone":
talker.Tone = value
elif param == "ToneScale":
talker.ToneScale = value
elif param == "Alpha":
talker.Alpha = value
# 感情設定
component_array = talker.Components
emotion_list = [component_array.At(i).Name for i in range(component_array.Length)]
for emotion in emotion_list:
component_array.ByName(emotion).Value = sentence['emotion_dict'][emotion]
# 文章を喋らせる
talker.Speak(sentence['sentence']).Wait()
elif list(sentence.keys())[0]=='time':
time.sleep(sentence['time'])
elif list(sentence.keys())[0]=='sound':
play_sound(sentence['sound'])
cevio.CloseHost(0)
sentence_listを渡すことで、sentence_listに入ってる順に実行していく。time.sleepは、Pythonから実行する場合には文章と文章の間が開いていないように感じたため、自然にしゃべれるように作成。また、パックについてきたvoiceの中で使いたいものが何個かあったものの、再現できなかったため音声再生のための処理も追加した。
sentence_listに追加するdictの例をいかに示す。
# CeVIO AIに文章を喋らせる場合
{'sentence':'こんにちは、小春六花です。',
'talker':'小春六花',
'talk_param_dict':{"Volume":50 , "Speed":50 , "Tone":50 , "ToneScale":50 , "Alpha":50 },
'emotion_dict':{'嬉しい':0, '普通':100, '怒り':0, '哀しみ':0, '落ち着き':0}}
# 文章と文章のあいだに間を開けたい場合
{'time':3}
# 音楽ファイルを再生したい場合
{'sound':'再生ファイルのパス'}
talk_param_dictのそれぞれのパラメーターはGUI上では以下に該当
- Volume:大きさ
- Speed:速さ
- Tone:高さ
- ToneScale:抑揚
- Alpha:声質
このリストを関数に渡すことでCeVIO AIが起動され実行されます。
sentence_list = []
sentence_list.append({'sentence':'こんにちは、小春六花です。',
'talker':'小春六花',
'talk_param_dict':{"Volume":50 , "Speed":50 , "Tone":50 , "ToneScale":50 , "Alpha":50 },
'emotion_dict':{'嬉しい':0, '普通':100, '怒り':0, '哀しみ':0, '落ち着き':0}})
sentence_list.append({'time':3})
sentence_list.append({'sound':'再生ファイルのパス'})
cevio_talk(sentence_list)
次にやること
次回は、実際にmainの部分を作り実際に設定して動かしていくところまでをやっていきたい。