序論
- Webサイトのサイトマップやメニューなどにおいて、情報を見つけやすく、理解しやすくする規律を 情報基本設計 information architecture (IA)といいます(Rosenfeld et al. 2015=2016: 1)。
- 情報基本設計で、利用者の心中にある情報の構造(メンタルモデル)を調査する方法として、カードソーティング があります(Rosenfeld et al. 2015=2016: 374; 樽本 2014: 121)。
- カードソーティングでは、情報を書いたカードを利用者に近い協力者に分類してもらい、その分類を分析します。
- カードソーティングの結果を分析する方法には、質的なものと、協力者ごとの分類の結果を統計的に統合する量的なものとがあります。
- 質的な分析の重要性については多くの実務者・研究者が合意するものの、量的な方法については文献でも「データを統計分析ソフトウェアに詰め込んで、自動的に図を作成すればよいでしょう」(Rosenfeld et al. 2015=2016: 377)、「統計解析ソフトが必要です」(樽本 2014: 125)と、具体的な情報が乏しい状況でした。
- 本記事では、計量文字列分析ソフトウェアのKH Coderを用いて、カードソーティングの結果を分析した記録を報告します。
- 全工程の所要時間の合計は約1時間です。
謝辞
- 本記事は、NTTコミュニケーションズ株式会社の2021年アドベントカレンダー https://adventar.org/calendars/6680 の一部として執筆しています。
- 弊社では、情報通信基盤の開発だけでなく、お客さまのユーザーインターフェイスの使いやすさ向上にも取り組んでいる(まだまだ道半ばですが)ということでご笑納いただければ幸いです。
環境
- Windows 10
- KH Coder Version 3.Alpha.15f(2021年12月13日時点で最新ではありません)
1 KH Coderをインストールする
- KH Coderは、社会学者の樋口耕一氏(立命館大学教授)が開発した計量文字列分析アプリケーションです(“KH” は樋口氏のイニシャル)。
- 樋口氏は基本機能を無料で提供しています。
- 最初に、KH Coderを公式Webサイトの https://khcoder.net/ からダウンロードしてPCにインストールします。
- KH Coderの背後では、日本語形態素解析のChaSen、データベースのMySQL、プログラミング言語のPerl、統計分析のRというアプリケーション群が動作するため、法人・団体が支給するPCを利用する場合には情報セキュリティー要件にご注意ください。
- Macでは上記のアプリケーションを個別にインストールする複雑な操作が必要なため、樋口氏は3980円(税込)の有償版を推奨しています。
2 辞書ファイルを作成する
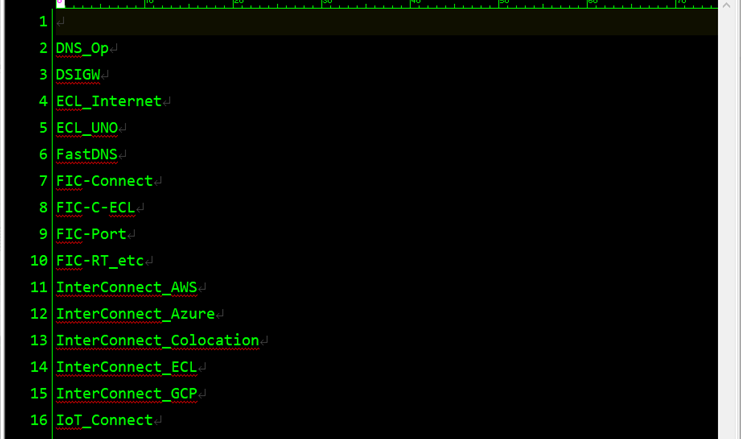
今回、作成した辞書ファイル
- 各カードに固有の名称を割り振った、辞書となるテキスト文書を作成します。
- この辞書ファイルを基に、KH Coderが各カードを判別します。
- 各カードは別々の名称である必要があります。例えば “kitsune_udon”(きつねうどん)と “kitsune_udon_inari-zushi_tsuki” (きつねうどんいなりずし付き)とを区別したい場合に、両方に “kitsune_udon” という名称を付けてしまうと、KH Coderが区別できません。
- 1行1語とします。
- 1行目はコマンド用らしく、空白にしておく必要があるようです(今回、初めて知った)。
3 カードソーティングの結果ファイルを作成する
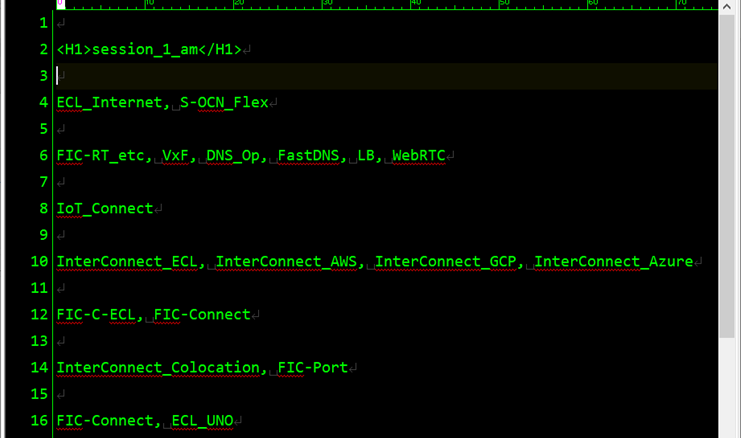
今回、作成したカードソーティング結果ファイル
- 辞書ファイルの名称を基に、段落をカードのグループに見立てたテキスト文書を作成します。
- 語の間はコンマおよび半角空き(, )で区切りました。
- 各協力者チームの結果は、HTMLヘッダータグで囲った見出し
<H1>(協力者コード)</H1>で区別しました。 - ヘッダータグを置くことで、KH Coderで対応分析という別の手法を使ったときに、各語と協力者との影響関係を図示できるようになりますが、今回は使いませんでした。
- 重複して分類されたカードは、両方のグループに集計しました。
- カードのグループの階層構造は方法上、反映できませんので、やむを得ず最も細かい階層でグループ分けしました。
4 KH Coderに結果ファイルを読み込ませる
- KH Coderを起動します。
- メニューバーの「プロジェクト」→「新規」とクリックします。
- ウインドー「新規プロジェクト」で「分析対象ファイル」の「参照」をクリックし、結果ファイルを指定し、「OK」をクリックします。
- 「言語」は初期設定の「日本語」「ChaSen」のままで構いません(今回はChaSenを利用しません)。
5 KH Coderに辞書ファイルを読み込ませる
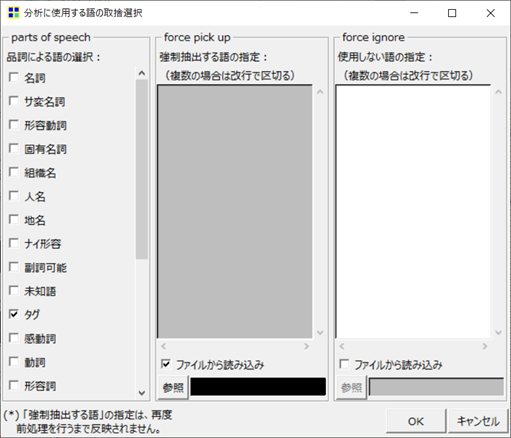
ウインドー「分析に使用する語の取捨選択」(一部加工)
- メニューの「前処理」→「語の取捨選択」をクリックします。
- ウインドー「分析に使用する語の取捨選択」の「品詞による語の選択」で「タグ」(辞書ファイルから読み込ませる語)以外のチェックを外します。
- 「強制抽出する語の指定」の「ファイルから読み込み」にチェックを入れ、「参照」をクリックして辞書ファイルを指定します。
これらの操作をしないと、一般的な語(例えば “DNS”)も結果ファイル中の語として認識されてしまい、辞書ファイルだけを基に前処理された結果が出ません。 - 「OK」をクリックします。
6 前処理を実行し、抽出語を確認する

ウインドー「抽出語リスト」
- 前処理(要は品詞分解)にはPCの処理能力を要するため、不要なアプリケーションを終了します。
- メニューの「前処理」→「前処理の実行」をクリックします。
- 「この処理には時間がかかる場合があります。続行してよろしいですか?」というダイアローグボックスが表示されるので、「OK」をクリックします。
- 「処理が完了しました」というメッセージボックスが表示されたら前処理は完了です。
- 前処理が完了したら、メニューの「ツール」→「抽出語」→「抽出語リスト」をクリックし、ウインドー「抽出語リスト」に辞書ファイルの語だけが表示されていることを確認します。
7 階層的クラスタリングを実行する
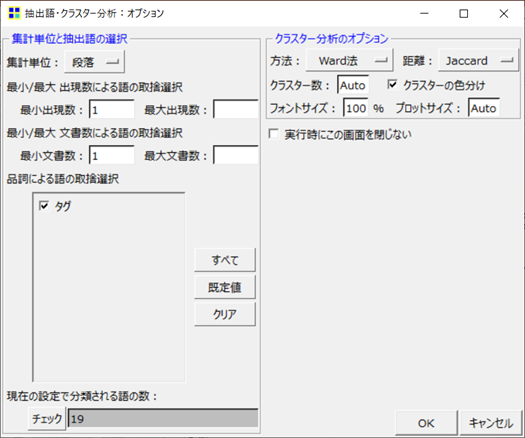
ウインドー「抽出語・クラスター分析:オプション」
- メニューの「ツール」→「抽出語」→「階層的クラスター分析」をクリックします。
- ウインドー「抽出語・クラスター分析:オプション」において、「集計単位と抽出語の選択」で「集計単位」を「段落」(カードのグループ)とします。
- 今回は、全ての語を漏れなく集計するため、「最小/最大出現数による語の取捨選択」の「最小出現数」を “1” に、「最小/最大文書数による語の取捨選択」の「最小文書数」を “1” とします。
- ここでいう「文書」は「集計単位」の「段落」を意味します。
- 「クラスター分析のオプション」は初期設定で構いません。
- 「OK」をクリックします。
8 結果を解釈する
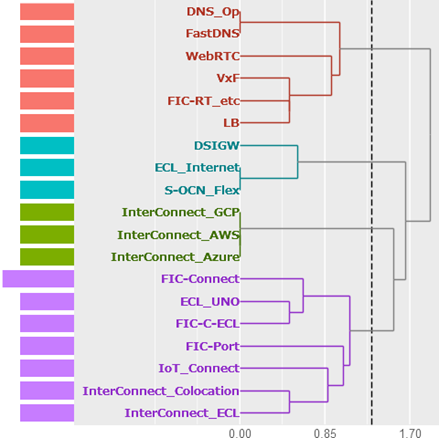
結果として出力される樹形図
- 樹形図は、左の方で縦につながっているほど、同じカードグループに分類されやすかったことを示します。
- 例えば、“DNS_Op” と “FastDNS” とは、三つの協力者チームが同じグループに分類したことを示しています。
- “ECL_Internet” と “S-OCN_Flex” の組み合わせ、“InterConnect_GCP” と “InterConnect_AWS” と “InterConnect_Azure” との組み合わせも同様です。
- 左の横棒は、語の出現回数を示します。
- “FIC-Connect” の出現回数だけが多いのは、二つのカードグループに分類した協力者チームがあったからです。
- 図は「保存」をクリックすることで保存が可能です。
付録 階層的クラスタリング、Jaccard距離、Ward法
-
階層的クラスタリング ( 階層的クラスター分析 )は、語Aと語Bとが同じ集計単位(今回は段落)に含まれるほど語の間の距離が近いと見なし、語の間の距離を可視化する分析方法です。
- 結果は、左の方で縦につながっている語ほど距離が近いことを示す 樹形図 ( デンドログラム dendrogram)として表示します(樋口 2020: 181)。
-
Jaccard距離 ( ジャカード距離 、 ジャッカード距離 )は、1から、語Aおよび語Bの両方を含む文書(集計単位)の数を、語Aまたは語Bの少なくともいずれか一つを含む文書(集計単位)の数で除した数(Jaccard係数)を減じた数です。
- Jaccard距離は、値が大きいほど二つの語の距離が遠くなります(Jaccard係数は逆になります)。
- より詳しくは、KH Coder公式の資料(樋口 2017)をご参照ください。
-
Ward法 ( ウォード法 )は、複数の語を含むグループ間の距離を計算するときに、グループ内の分散(ばらつき)が小さく、かつグループ間の分散が大きい組み合わせで語のグループを形成していく計算方法です。
- 計算量が多い反面、グループ全体の分散を反映させながら計算するため、他の語との距離が極端に大きい語(外れ値)の処理に強いとされています。
- 距離の計算方法は他にもあり、方法によって出力される樹形図も異なるため、階層的クラスター分析だけに頼った考察は望ましくないとされています。
[文献]
- 樋口耕一, 2017,「Jaccard係数の計算式と特徴(2)」, LinkedIn SlideShare,(2021年12月13日取得, https://www.slideshare.net/khcoder/jaccard2 ).
- ――――, 2020,『社会調査のための計量テキスト分析 第2版――内容分析の継承と発展を目指して』ナカニシヤ出版. http://www.nakanishiya.co.jp/book/b506269.html
- Rosenfeld, Louis, Peter Morville and Jorge Arango, 2015, Information Architecture: For the Web and Beyond Fourth Edition , Sebastopol, California: O’Reilly Media.(篠原稔和監訳・岡真由美訳, 2016,『情報アーキテクチャ第4版――見つけやすく理解しやすい情報設計』オライリー・ジャパン.) https://www.oreilly.co.jp/books/9784873117720/
- 樽本徹也, 2014,『ユーザビリティエンジニアリング(第2版)――ユーザエクスペリエンスのための調査、設計、評価手法』オーム社. https://shop.ohmsha.co.jp/shopdetail/000000000532/