Overview
IEEE International Conference on Data Mining (ICDM) は、IEEEが主催するデータマイニングに関連した国際会議です。2019年度は、11月に中国の北京で開催されました。

私はそのworkshopでの発表でしたが、他のセッションも聴講してきたので印象に残っている発表を備忘録も兼ねていくつか紹介させていただきます。執筆開始時点(2019年末)ではproceedingsが公開されていないので、論文のリンクはarXivのものを貼ってあります。
参加セッション
私が参加したセッションは主に以下のものです。
- Mining and Link Analysis in Networked Settings
- Sequences & Time Series
- Anomalies & Outliers
- Industrial Talk
- Banquet(おまけ)
Mining and Link Analysis in Networked Settings
最初に紹介するのは、ネットワーク解析やSNSのようなlinkを持った構造のデータ解析に関するセッションです。
-
Interpretable Feature Learning of Graphs using Tensor Decomposition
CP分解(テンソル因子分解手法のひとつ)を利用した様々なタイプのグラフに適応可能なネットワーク埋め込み手法を提案しています。
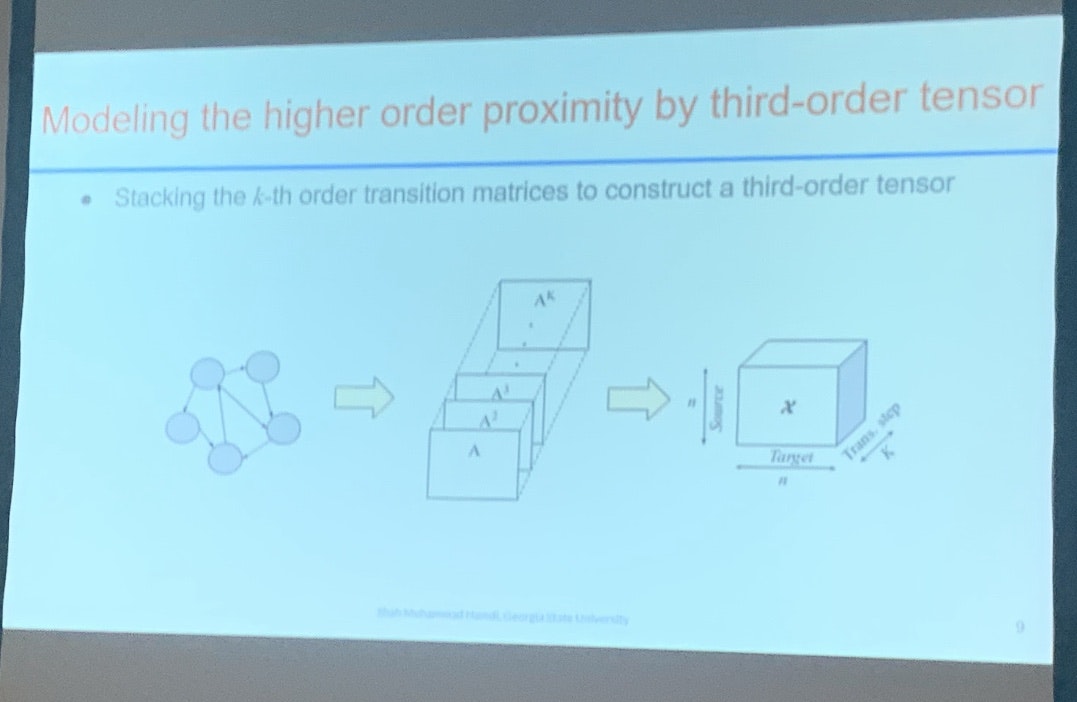 kステップ遷移確率行列を利用してネットワークからテンソルを構築後、CP分解を適用することによって解釈性に優れた埋め込み表現の学習を行っています。ネットワーク再構築、リンク予測、ノード分類、およびグラフ分類でのパフォーマンス向上や解釈可能性向上の観点から手法の有効性を示していました。
kステップ遷移確率行列を利用してネットワークからテンソルを構築後、CP分解を適用することによって解釈性に優れた埋め込み表現の学習を行っています。ネットワーク再構築、リンク予測、ノード分類、およびグラフ分類でのパフォーマンス向上や解釈可能性向上の観点から手法の有効性を示していました。
ソーシャルメディアにおいて、感情情報を考慮した人気トピック推定をするSENTI2POPを提案しています。主に次の三つの構成要素により、図のような機構のモデルを構築しています。
①TF-SW: 直近で話題になった新しいトピックの人気を測る指標
②Tree-Net: Bi-LSTMとCNNを組み合わせた感情予測モデル
③Dual-ARIMA: DTWとARIMAモデルを用いた人気トピックの推定モデル

特に従来では、いいね、リツイート、コメント数を用いてトピックのpopulalityを測ることが一般的でしたが、これには「Real-time stramが考慮できていない」「ノイズと曖昧性(apple社について調べたいのに林檎関連のツイートもごちゃ混ぜに)」といった問題点があります。その課題に対処するためにTF-SWが用いられているようです。
ネットワーク内における role に関する潜在表現を学習できると、ネットワークに関する理解が促され、情報伝達にも役立てることができます。この論文では RiWalk という、柔軟にノード構造表現を学習するための手法が紹介されています。
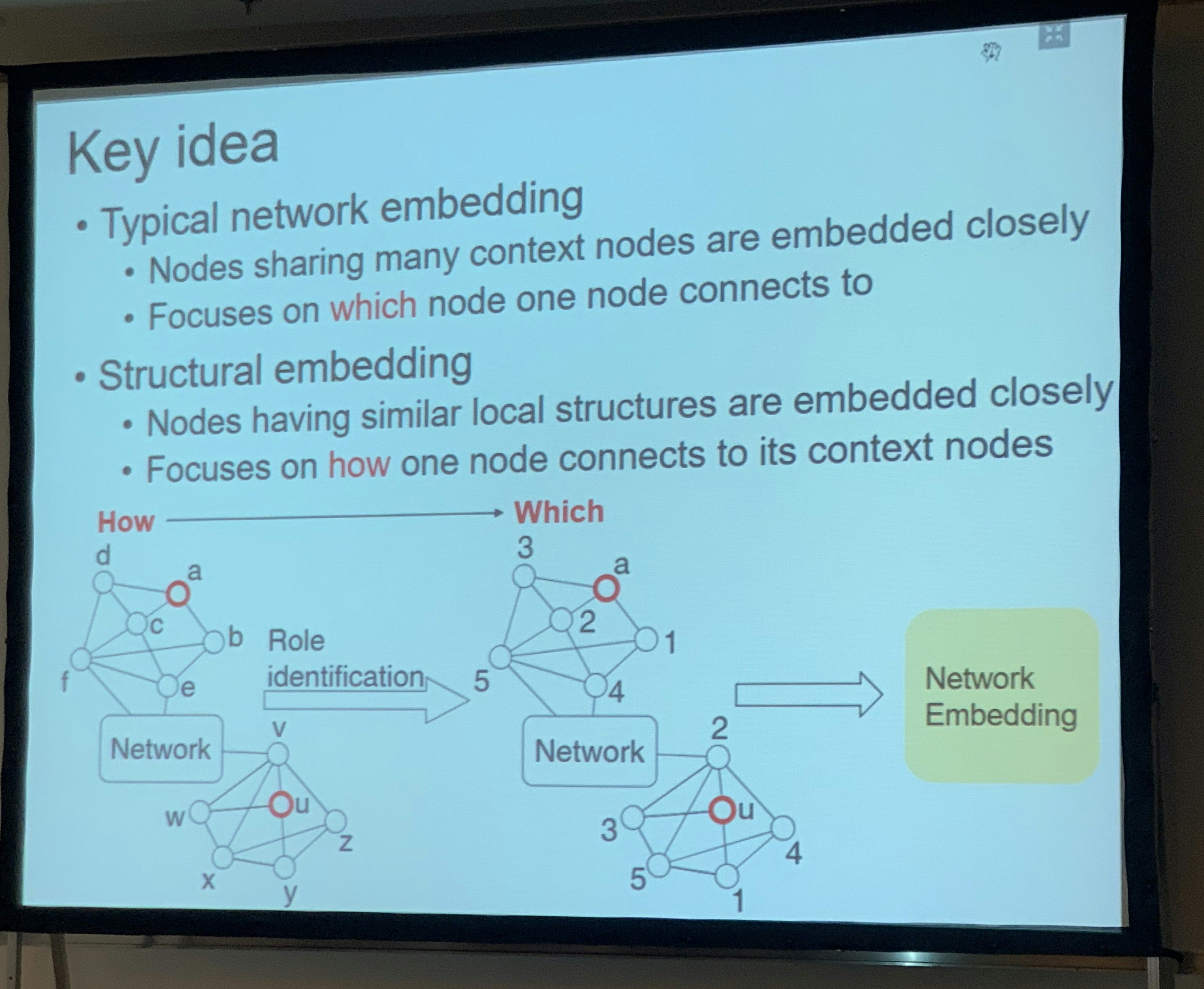
アンカーノードのローカルトポロジにおける 構造的な roles によって relabeling することでサブグラフを生成した後、典型的なネットワーク埋め込み手法を適用して構造埋め込みを学習しています。この工夫により、同じような周辺構造を持つノード群が近くに埋め込まれるようになります。また、既存手法よりもスケーラブルであることが言及されており、大きなグラフでも効果を期待できるようです。
Code: github.com/maxuewei2/RiWalk
Sequences & Time Series
こちらでは時系列におけるモチーフ検出の研究を中心に紹介します。ちなみに、ここでのモチーフとは時系列データの中で頻出するパターンのことを指します。
-
Multi-Aspect Mining of Complex Sensor Sequences
センサー、ユーザ情報、タイムスタンプといった複数の属性で構成される複雑なセンサーデータにおいて、Multi-aspect patternsを自動的に素早く検知する手段として、CUBEMARKERという手法を提案しています。
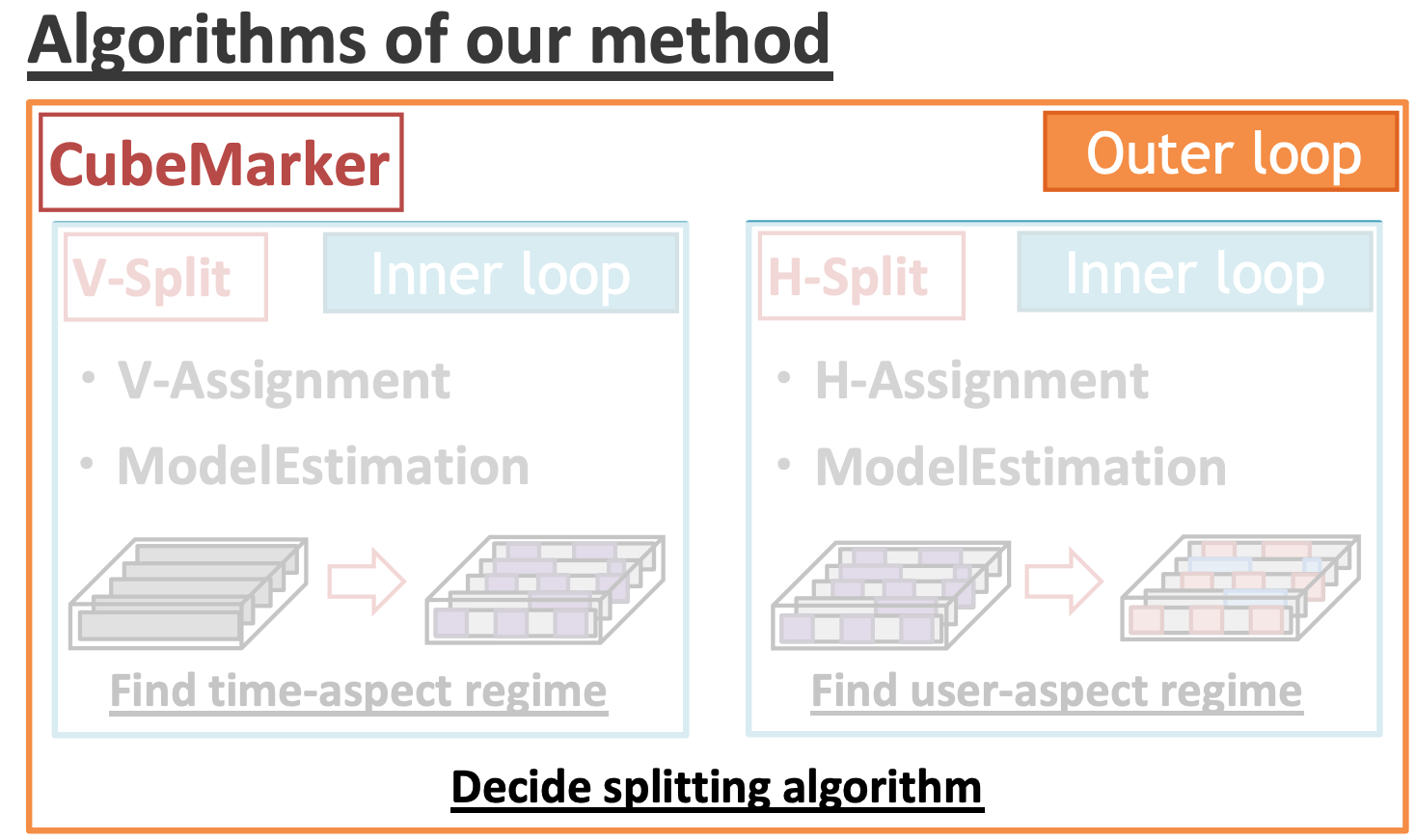 隠れマルコフモデルを応用しつつテンソル形式で表現したデータに関して、V-Split(time-aspect)/H-Split(user-aspect)という別サイドからの分割を各々行い、各状態で算出されたコスト関数の値が小さい方を採用する、ということを繰り返していくことで最終的なsegmentを探索していくようです。事前学習やパラメータチューニングが要らず、スケーラブルでありながらも、上記の目標を達成している点において有用性が示されています。
[Slide: https://takatohonda.github.io/slide/slide-icdm19.pdf](https://takatohonda.github.io/slide/slide-icdm19.pdf)
隠れマルコフモデルを応用しつつテンソル形式で表現したデータに関して、V-Split(time-aspect)/H-Split(user-aspect)という別サイドからの分割を各々行い、各状態で算出されたコスト関数の値が小さい方を採用する、ということを繰り返していくことで最終的なsegmentを探索していくようです。事前学習やパラメータチューニングが要らず、スケーラブルでありながらも、上記の目標を達成している点において有用性が示されています。
[Slide: https://takatohonda.github.io/slide/slide-icdm19.pdf](https://takatohonda.github.io/slide/slide-icdm19.pdf)
-
Discovering Subdimensional Motifs of Different Lengths in Large-Scale Multivariate Time Series
多変量時系列における、可変長のapproximate sub dimensional motifsを効率的に識別する為のスケーラビリティな手法として、Collaborative HIerarchy based Motif Enumeration (CHIME)を提案しています。
 総当たり列挙法(brute-force)では、一次元の時系列であっても非常に時間がかかり、また、既存のrandom projectionなどでは、メモリ上の限界から固定長のモチーフしか検出できていません。それに対して、大規模な多変量時系列の可変長モチーフ検知でも対応可能な点において提案手法の優位性があるようです。
総当たり列挙法(brute-force)では、一次元の時系列であっても非常に時間がかかり、また、既存のrandom projectionなどでは、メモリ上の限界から固定長のモチーフしか検出できていません。それに対して、大規模な多変量時系列の可変長モチーフ検知でも対応可能な点において提案手法の優位性があるようです。
-
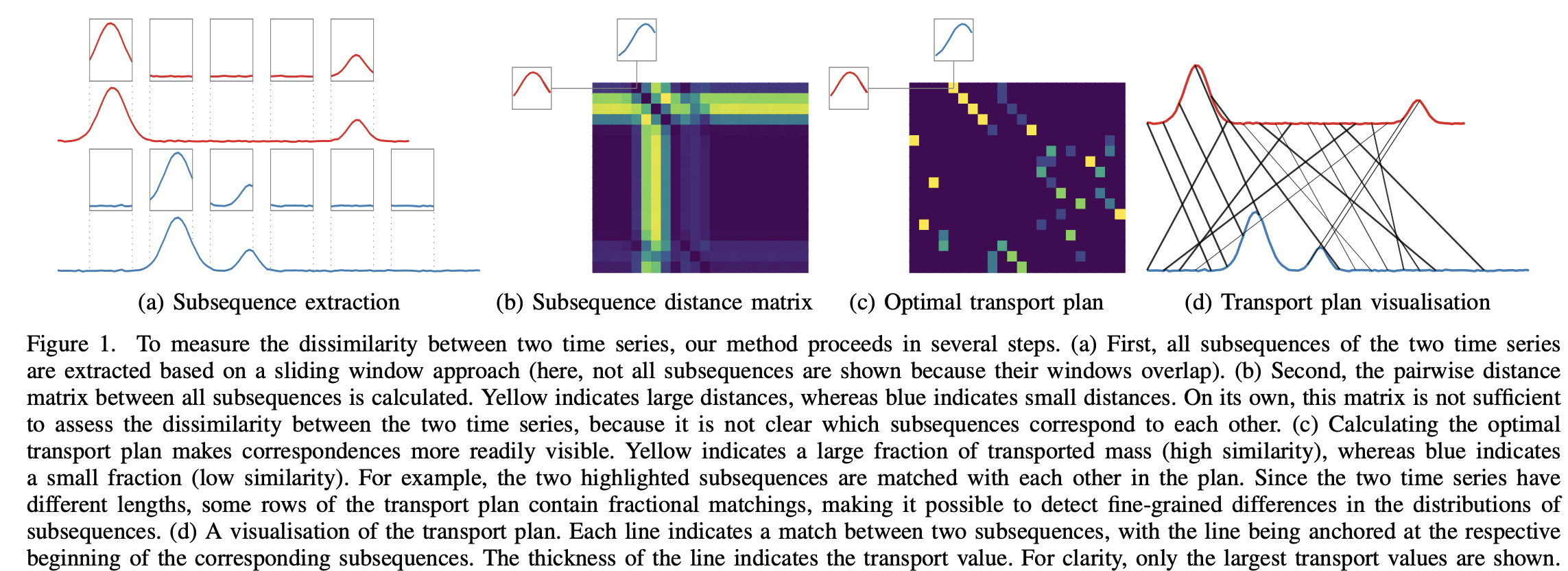
A Wasserstein Subsequence Kernel for Time Series
構造化データを学習するための強力なアプローチであるカーネル法に関連した発表です。時系列分類のための類似性尺度としてWasserstein距離に基づいた新しいsubsequence-based kernelを開発しています。
 [Code: github.com/BorgwardtLab/WTK](https://github.com/BorgwardtLab/WTK)
[Code: github.com/BorgwardtLab/WTK](https://github.com/BorgwardtLab/WTK)
-
Matrix Profile XV: Exploiting Time Series Consensus Motifs to Find Structure in Time Series Sets
time series consensus motifs というものの紹介と、大規模で複数時系列を持ったデータ集合内においてそれらを発見するための手法を提案しています。
 既存手法が単一時系列や時系列のペアにおけるモチーフ検知を対象にしていることが一般的だったことに対して、複数の時系列の集合において繰り返されている構造を検知することに焦点を当てているようです。
既存手法が単一時系列や時系列のペアにおけるモチーフ検知を対象にしていることが一般的だったことに対して、複数の時系列の集合において繰り返されている構造を検知することに焦点を当てているようです。
Anomalies & Outliers
次に紹介するのは、異常検知&外れ値検知に関するセッションです。
-
Jointly embedding the local and global relations of heterogeneous graph for rumor detection
ソーシャルメディアにおける既存の噂検知(rumor detection)手法がテキストのコンテンツ、ユーザプロフィール、伝達パターンに焦点を当てていたのに対し、メッセージの伝達グラフにおける local semantic relation と global structural information は活用されていませんでした。そこで、この研究では global-local attention network (GLAN) という、それらを組み込んだ新規手法を提案しています。
 提案手法では、①CNNベースのモデルによる単語埋め込みでマイクロブログを意味空間へマッピングし、②Multi-head Attention を活用した local relation encoding において、対応するリツイートとソースツイートのローカルな繋がりの表現を学習、③global relation encodingではより広範囲のグラフ構造をエンコーディングして、④得られた local representation と global representation を元にクロスエントロピーを誤差関数とした噂分類モデルを学習しています。提案手法を用いた実験では、噂の分類と早期発見タスクの両方で他の最先端のモデルを大幅に上回る結果が示されたようです。
提案手法では、①CNNベースのモデルによる単語埋め込みでマイクロブログを意味空間へマッピングし、②Multi-head Attention を活用した local relation encoding において、対応するリツイートとソースツイートのローカルな繋がりの表現を学習、③global relation encodingではより広範囲のグラフ構造をエンコーディングして、④得られた local representation と global representation を元にクロスエントロピーを誤差関数とした噂分類モデルを学習しています。提案手法を用いた実験では、噂の分類と早期発見タスクの両方で他の最先端のモデルを大幅に上回る結果が示されたようです。
-
Learning review representations from user and product level information for spam detection
ソーシャルメディアにおける Opinion spam の排除を目指した研究です。既存研究では主に個別のテキストやサービスの利用行動に着目されていましたが、これだけでは複雑なセマンティクスを捉えきれないという問題がありました。
 そこで、この研究では Hierarchical Fusion Attention Network (HFAN) という、ユーザ情報、レビュー文、製品情報の関係性をエンコードすることによって、ユーザ及び製品レベルからセマンティクス表現を学習できるモデルを提案しています。モデルの機構は図に示した通りです。
そこで、この研究では Hierarchical Fusion Attention Network (HFAN) という、ユーザ情報、レビュー文、製品情報の関係性をエンコードすることによって、ユーザ及び製品レベルからセマンティクス表現を学習できるモデルを提案しています。モデルの機構は図に示した通りです。
Industrial Talk
学会のスポンサーであるBaiduやDiDi、LinkedIn(领英中国)といった、中国企業の方々によるセッションもありました。

例えば配車アプリDiDiでは、上図に示したような大量なデータやりとりに対応しつつ、機械学習技術などを応用したサービスの向上に取り組んでいるそうです。
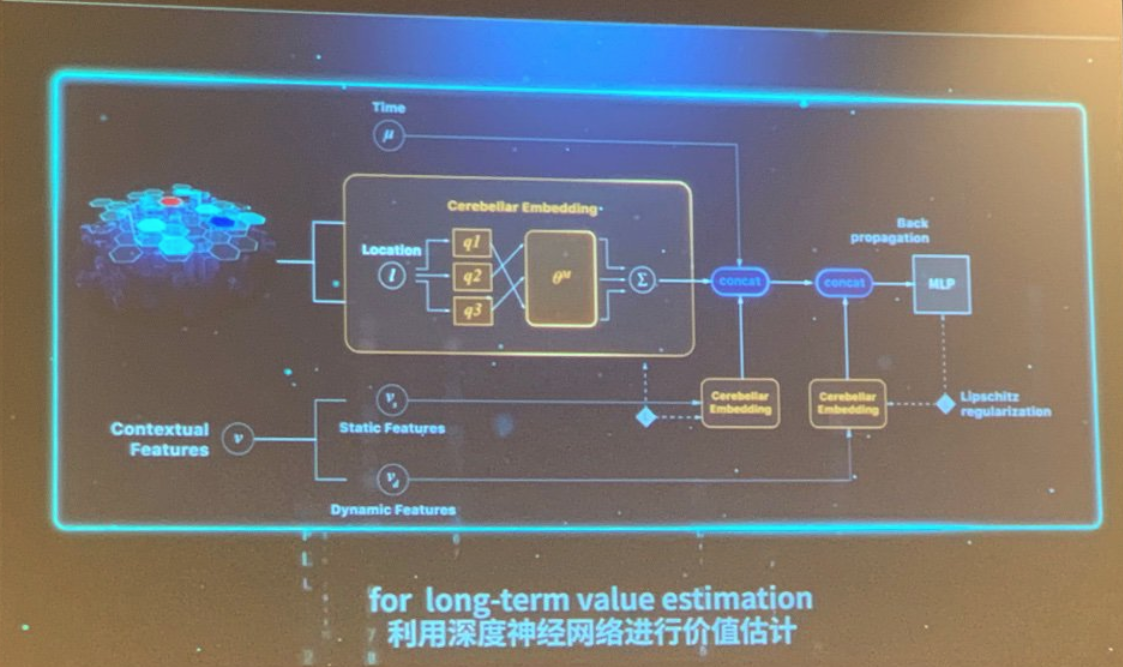
発表の中では、以下のような事例が紹介されていました。論文もいくつか出ているので、興味のある方は覗かれてみると面白いかもしれません。
- Travel time estimation
- Maximize drivers’ collective income through optimized dispatching
- Reinforcement learning which focus on long-term reward
 各社版AutoMLのようなものの紹介もいくつかあり、機械学習の民主化/手軽に利用するための技術はホットトピックなのだろうと感じました。
各社版AutoMLのようなものの紹介もいくつかあり、機械学習の民主化/手軽に利用するための技術はホットトピックなのだろうと感じました。
Banquet(おまけ)
中日に晩餐会が開催されました。普段お会いできないような海外の研究者の方々とも交流できて楽しかったです。出し物も中国らしいものが多くて見入ってしまいました。

↑龍の舞に合わせた踊り。隣の席に居合わせた中国人研究者の方が教えてくださったのですが、どうやらspring festival(春節?)等でよく行われる出し物のようです。私の記憶違いでなければ。

↑エクストリーム皿回し

↑会場入り口での演奏も素敵な音色でした
感想
純粋な執筆経験/発表経験のみならず、最新の研究に関する発表を聴講でき、他の研究者の方々ともやりとりできたので大変貴重で有意義な数日間となりました。これからも精力的にサーベイに取り組みつつ、日々の研究活動や勉強を頑張ります。