PythonでVIF確認出来て超便利!
PythonでVIF(Variance Inflation Factor)を調べることができ、この結果を見ながら説明変数間の多重共線性を確認することができます。
一般的にVIF>10の場合は多重共線性が強いと判断できるとの事。
from statsmodels.stats.outliers_influence import variance_inflation_factor
df_all = pd.read_excel('train.xlsx',sheet_name="Sheet1")
cols = df_all.select_dtypes(include=[np.number]).columns
cols_x = cols[1:]
data_x = df_all[cols_x]
# vifを計算する
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(data_x.values, i) for i in range(data_x.shape[1])]
# vif["features"] = data_x.columns
# vifを計算結果を出力する
print(vif)
# vifをグラフ化する
plt.plot(vif["VIF Factor"])
こんな感じで結果が出ます。便利ですよね!
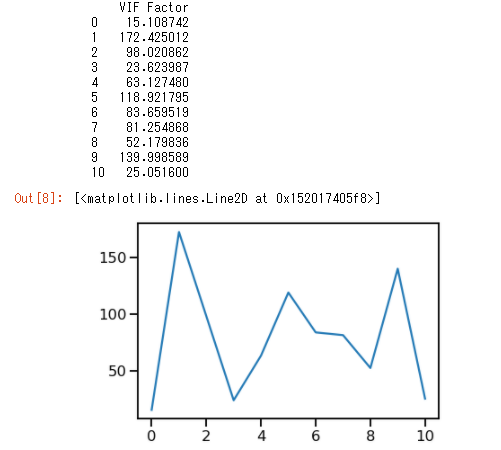
ところが、、Excelで算出したVIFと比較すると..
VIFが異なる結果で出てくることが発覚しました('Д')..!!
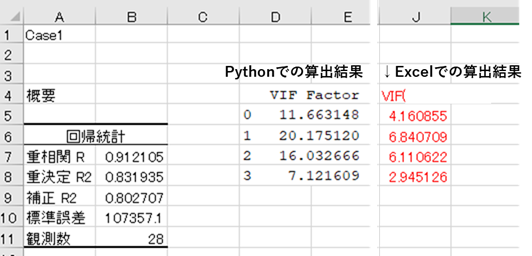
そもそもVIFは以下の式で求められます。
VIF = 1/(1-R2) # R2:決定係数
説明変数の1つを目的変数と見立てたときに、残りの説明変数で重回帰分析した際に得られる決定係数R2を使用します。
感覚的に言えば、「残りの説明変数である1つの変数を上手に表現できるなら、その変数はいらなくない?」って事だと理解しています。
VIFが違うという事は、PythonとExcelでこのR2が異なるということになるので、一瞬パニックになりました。
違いの原因は、切片を含むか否か..でした。
何故異なるか、その原因は説明変数に切片を含めるか否か、という事が判明しました。
Python側では、切片=0として処理
Excelで検討した際は、切片を特に指定しませんでした。
Excelでも切片=0とするように設定したところVIFが一致することを確認できました。
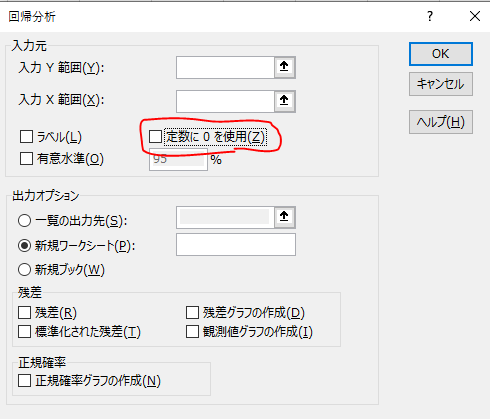
↑ここにチェックを入れるかどうか
皆さんに聞きたい..結局どっちが正しいのでしょうか?
- Pythonのstatsmodel使っておけば問題ないのでは?
- 切片は特に指定するべきではない?
- とにかくR2が最大になる組み合わせでVIFを評価するべきで、切片が0か否かは重要ではない?
- VIFはあくまで目安なので、特に気にする必要はない?
上記のようなことを考えているのですが、皆さんいかがでしょうか?
そもそもstatsmodelのVIF算出アルゴリズムがどうなっているのかも気になります..。