はじめに
もっといい方法はないだろうか..と模索しつつも、ひとまずこの方法でまとめておく。~~(もっといい方法ご存知の方、教えてください!!)~~→教えて頂いた皆様、本当にありがとうございました!改良版をページ下部に追記しました。
やりたいこと
①基本
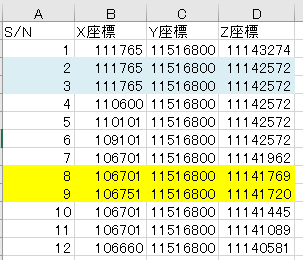
下図のように3次元の座標点が格納されているエクセルがあり、同じ座標を持つ番号をリンクさせたい。下図の例ではS/N-2の座標とS/N-3の座標(水色でハイライトした箇所)は完全一致しているので、これらは「同じ座標です!」と判定させる。
②応用
私が今回取り組んでいる対象の仕様として、完全に座標が一致することはなかなか起こらない。そのため、ある程度のMarginをもって一致していると判定したい。例えば、S/N-8の座標とS/N-9の座標(黄色でハイライトした箇所)は概ね一致しているので、これらも「同じ座標です」と判定して欲しい。
今回、この”応用”のグッドアイデアが今一つ思い浮かばなかった。。
完全一致のみを抽出する場合はX座標、Y座標、Z座標を文字列として結合して、一致するか判断していけばいいのかなと思いました。
できたコードがこのような感じ
まずはmarginを含んで判定できるような関数を作成。以下の場合誤差±100は無視され、3つの座標がmargin込みで一致した場合、Trueが返ります。
def coordinates_check(ax,ay,az,bx,by,bz):
margin=100
flag = 0
result=False
if ax-margin < bx < ax+margin:
flag = flag +1
if ay-margin < by < ay+margin:
flag = flag +1
if az-margin < bz < az+margin:
flag = flag +1
if flag >2:
result = True
return result
この関数を使用して、エクセルファイルの行を上から読み取っていきます。
読み取りが重複しないように、2つ目のfor文の開始番号を工夫しています。
df_test = pd.read_excel('sample.xlsx')
for i in range(len(df_test)):
ax= df_test.loc[i,"X座標"]
ay= df_test.loc[i,"Y座標"]
az= df_test.loc[i,"Z座標"]
k = i+1
for j in range(k,len(df_test)):
bx = df_test.loc[j,"X座標"]
by = df_test.loc[j,"Y座標"]
bz = df_test.loc[j,"Z座標"]
if coordinates_check(ax,ay,az,bx,by,bz):
print("一致しました:",df_test.loc[i,"S/N"],"-->",df_test.loc[j,"S/N"])
結果、うまくできている。

少ないデータならいいのだけど..
私が今回使いたいデータは1万行超えで、上記のコードを実行すると3時間くらいかかってしまったんですよね..。もっといい方法があるはずだよなぁと思った今日この頃でした。いい方法をご存知の方、助けてください!
(2020/7/16追記)助言をもとにアップデート
コメント欄にて協力頂いた皆様、誠にありがとうございました!!
numpyに変換し、ismatchを使って処理したところおよそ2秒で完了しました。
恐るべし..numpy..
(↓参考に頂いたコードのほぼコピペです。本当にありがとうございました。)
import time
import numpy as np
margin = 100
data = df_all.loc[:, ["X座標", "Y座標", "Z座標"]].values
margin = 100
match_dict = {}
start = time.time()
for i in range(data.shape[0]):
# Broadcast用にshapeを拡大する
compared = np.expand_dims(data[i], 0) # shape = (1, 3)
# np.abs(data[i+1:] - compared) < margin で各要素がmargin内に入っているか判定
# np.all(axis=1)でx,y,z軸の論理積を取っている
# 最終的なismatchはi+1番目からのshape=(10000 - i - 1)のBoolean型になる
ismatch = np.all(np.abs(data[i+1:] - compared) < margin, axis=1) # shape = (10000 - i - 1,)
# True=1,False=0と捉えられるので,nonzeroでTrueのIndexを取得
# ismatchのIndexはi+1番目からなので + (i + 1)する
match_dict[i] = np.nonzero(ismatch)[0] + i + 1
#print(np.nonzero(ismatch)[0])
print(time.time() - start) # 2s
良い感じ!(Index=2はIndex3,4とマッチしている)
numpy.nonzeroがこのような振舞いをするとは、知らなかったですね..。
