Section1 : 再帰型ニューラルネットワークの概念
要点
RNNとは時系列データに対応可能なニューラルネットワークである.例えば,音声データ,テキストデータなどである.初期の状態と以前の状態から以後の時間での$t$を再帰的に求める再帰構造が必要である.
BPTTは,RNNのおいてのパラメータ調整方法の一種である.
実装演習
2進数の加算を予測するRNNモデルを計算する.
ベースモデル
縦軸は誤差である.こちらをベースモデルとして,パラメータと手法を変更して,誤差の変化を考察する.
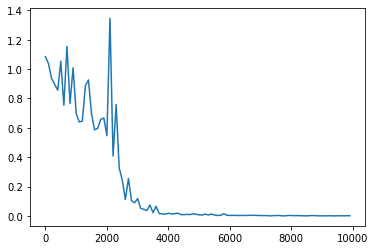
ベースモデルに対して学習率を0.1から0.01に変更した.誤差が収束していないことが確認できる.学習率が小さい場合は学習のスピードが遅くなるだけでなく,誤差が収束しない場合もあることが分かった.
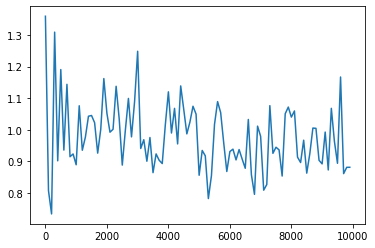
ベースモデルに対して重みの初期化方法をXavierに変更した.誤差は収束しているが,ベースモデルに対しては収束のスピードが遅い.学習に関するテクニックがどのモデルに対しても必ず改善するわけではないことが分かった.
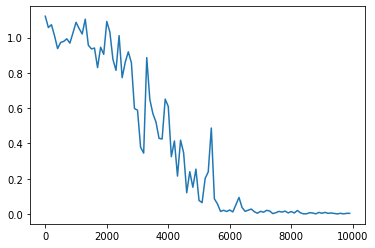
ベースモデルに対して活性化関数をシグモイド関数からReLU関数に変更したところ,勾配発散が起こってしまった.

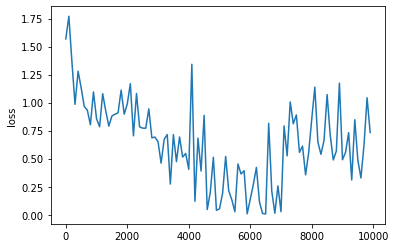
ベースモデルに対して活性化関数をシグモイド関数からtanh関数に変更したところ,勾配消失・勾配発散はないものの誤差の振動が収束していない.
「確認テスト」について自身の考察結果
サイズ5x5の入力画像をサイズ3x3のフィルタで畳み込んだ時の出力画像のサイズを求める.ここで,ストライドは2,パディングは1である.
次式から出力サイズ$(OH,OW)$を計算する.
$$OH=\frac{H+2P-FH}{S}+1$$
$$OW=\frac{W+2P-FW}{S}+1$$
$$OH=OW=\frac{5+2\cdot 1-3}{2}+1=3$$
したがって出力サイズは7x7である.
RNNの重みは大きく分けて,入力~中間層,中間層~中間層,中間層~出力の3つである.
連鎖律を用いて以下の式における$dz/dx$を求める.
$$z=t^2,t=x+y$$
$$\frac{dz}{dx}=\frac{\partial z}{\partial t}\frac{\partial t}{\partial x}=2t\cdot 1=2(x+y)$$
下図の$y_1$を$x_1,x_0,x_1,W_{(in)},W,W_{(out)}$を用いて数式で表す.
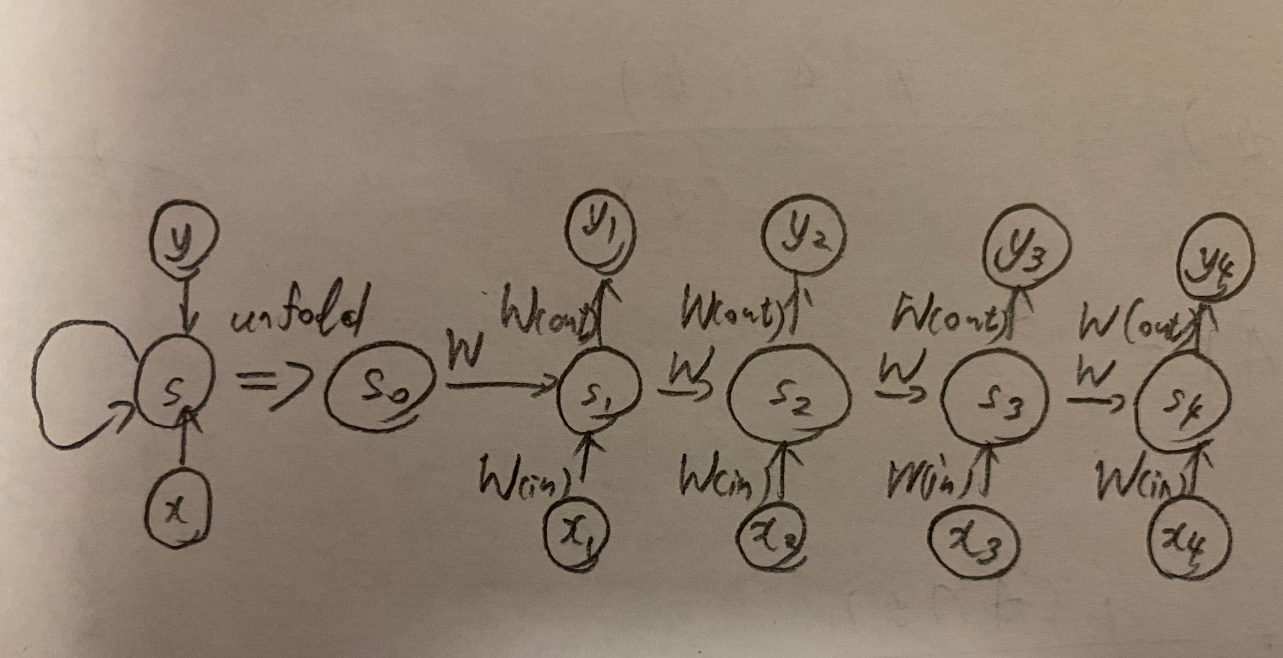
$$z_1=g(s_0W+x_1W_{(in)}+b)$$
$$y_1=g(z_1W_{(out)}+c)$$
参考
$\tanh x$の導関数を導出する.
$$(\tanh x)'=\Big( \frac{e^x-e^{-x}}{e^x+e^{-x}} \Big)'=\frac{(e^x+e^{-2})^2-(e^x-e^{-x})^2}{(e^x+e^{-x})^2}=1-\tanh^2 x$$
Section2 : LSTM
要点
RNNの問題として,逆伝播時に時系列データを遡るにしたがって勾配が消失していく.これは勾配消失問題と呼ばれ,例えばシグモイド関数では入力の大きさが大きいほど起こりやすい.この問題を解決するためのネットワーク構成の代表格がLSTMである.
勾配消失とは別に勾配爆発も起こりうる.CECはこれらの問題を解決する方法である.以下に説明する.
CEC
勾配を1にすることで,勾配消失および勾配爆発を防ぐ方法である.しかし,入力データについて,時間によらず重みが一律になり,学習特性を失ってしまうという問題がある.この問題を解決するために,入出力ゲートを設ける.これらはそれぞれのゲートへの入力値の重みを重み行列$W,U$によって可変可能にさせる.
ここで,LSTMのさらなる問題として,CECは過去の情報がすべて保管されており,不要な記憶が存在する.
CECの保存されている過去の情報は任意のタイミングで他のノードに伝播させたり,任意のタイミングで忘却させたい.覗き穴結合はCEC自身の値に重み行列を介して伝播可能にした構造である.
「確認テスト」について自身の考察結果
シグモイド関数の微分は以下のようになる.
$$f(x)=\frac{1}{1+\exp {(-x)}}$$
$$f'(x)=f(x)(1-f(x))$$
シグモイド関数を微分したとき,入力値が0の時に最大値をとる.その値を求める.
まず,$f(0)=0.5$である.それを用いると,次式からシグモイド関数の微分の最大値は$0.25$となる.
$$f'(0)=0.5\cdot(1-0.5)=0.25$$
LSTMの忘却ゲートは例えば以下の文章の空欄を予測するとき,文中の「とても」という言葉に対して作用される.
「映画おもしろかったね.ところで,とてもお腹が空いたから何か____.」
Section3 : GRU
要点
LSTMでは,パラメータ数が多いため計算負荷が高くなる問題がある.これに対する解決策がGRUである.GRUは,LSTMのゲートを使用するというコンセプトはそのままで,パラメータを大幅に削減し,さらに精度が同等以上となる構造である.LSTMとの大きな違いは,LSTMがhiden stateと記憶セルの2つのラインを使用するのに対して,GRUはhiden stateのみ使用することである.
実装演習
これまではライブラリnumpyを使用していた.今回はより高度なライブラリTensor Flowを使用する.
以下のようにTensor FlowではRNNなどのモデルはライブラリとして備わっており,簡単に実装できる.
# RNN のセルを定義する。RNN Cell の他に LSTM のセルや GRU のセルなどが利用できる。
cell = tf.nn.rnn_cell.BasicRNNCell(self.hidden_layer_size)
outputs, states = tf.nn.static_rnn(cell, input_data, initial_state=initial_state)
保存したモデルを使って単語の予測をする.
ln.predict("some of them looks like")
実行結果(一部抜粋)
ischemia : 1.4152389e-14
miracl : 1.510721e-14
atorvastatin : 1.3983241e-14
mgdl : 1.5000311e-14
rehospitalization : 1.456842e-14
worsening : 1.3476926e-14
endpoints : 1.4479218e-14
lipid : 1.5310498e-14
lipoprotein : 1.3668963e-14
ldl : 1.4424475e-14
statin : 1.3786473e-14
a--z : 1.3740822e-14
simvastatin : 1.4133777e-14
bmi : 3.1721086e-07
covariates : 2.834505e-06
yhl : 2.2330451e-07
yol : 9.9930106e-11
obesity : 1.3501609e-09
evgfp : 6.1830234e-09
unintended : 4.67851e-09
sizes : 2.5699424e-07
obese : 1.9368164e-07
<???> : 2.919565e-05
Prediction: some of them looks like et
「確認テスト」について自身の考察結果
CECとLSTMの課題を整理する.
LSTM : パラメータ数が多いため計算負荷が高い.課題は計算負荷削減である.
CEC : 勾配消失・爆発の抑制のために勾配を1にしたことで,重みが一律になってしまう.課題は学習の促進である.
LSTMとGRUの大きな違いはパラメータの数である.GRUはLSTMのパラメータが多いことによる計算負荷の問題を解消するネットワーク構成である.
Section4 : 双方向RNN
要点
これまでのネットワーク構成は現在と過去の情報から順伝播を行っていた.双方向RNNは過去の情報に未来の情報を加味することで,精度向上を狙ったモデルである.例えば,文章の推敲や機械翻訳に応用される.双方向から処理することで,各単語に対応する隠れ状態ベクトルは,左と右の両方向からの情報を集約することができ,バランスのとれた情報がエンコードされる.
Section5 : Seq2Seq
要点
Seq2seqはEncoder-Decoderモデルの一種である.機械対話や機械翻訳に応用される.ここでまず,Encorder RNN,Decorder RNNについて説明する.
Encorder RNN
ユーザーがインプットしたテキストデータを単語等のトークンに区切って渡す構造である.手順はTaking,Embedding,Encorder RNNの順で行い,分散表現ベクトルをRNNに入力してDecoder RNNに引き継ぐ.
Decoder RNN
アウトプットデータをトークンごとに生成する構造である.Sampling,Embeddingで得られたトークンを文字列に起こす.
HRED
Seq2seqは入力に対する応答が一問一答しかできず,文脈を考慮した応答ができない.HREDは過去n-1個の発話から次の発話を生成するモデルであり,より人間らしい文章を生成できる.HREDはSeq2seqにContext RNNを加えたモデルである.しかしながら,HREDは確率的な多様性が字面にしかなく,会話の「流れ」のような多様性がない.
VHRED
HREDの課題をVAEの潜在変数の概念を追加することで解決した構造である.
VAE (variational autoencorder)
オートエンコーダーは入力データを潜在変数$z$に変換する構造が見えない.VAEはこの$z$に確率分布$z\sim N(0,1)$を仮定した構造とするモデルである.
「確認テスト」について自身の考察結果
Seq2seqはRNNを用いたEncoder-Decorderモデルの一種である.機械翻訳などに応用される.
Seq2seqとHREDの違い : Seq2seqは一問一答式の出力しかできないのに対して,HREDはn-1個の発話から文脈を考慮したより人間らしい文章を生成できる.
HREDとVHREDの違い : HREDは文脈に即した出力ができるが,一律である.VHREDはこれに対して,VAEの潜在変数の概念を追加することで,文脈に即してかつランダムに人間らしい応答ができる.
VAEは自己符号化器の潜在変数に確率分布を導入したものである.
Section6 : word2vec
要点
RNNは,単語のような可変長の文字列をニューラルネットワークに与えることができない.したがって,固定長形式で単語を表す必要がある.
word2vecは学習データからボキャブラリを作成する.このモデルはデータ量がボキャブラリ数x任意の単語ベクトルの次元数の重み行列とするため,現実的な計算量とメモリ量を実現可能にした.
Section7 : Attention Mechanism
要点
Seq2seqの問題は長い文章への対応が難しいのが問題であり,どの単語量に対しても固定次元ベクトルの中に入力しなければならない.Attention Mechanismは文章が長くなるほどそのシーケンスの内部表現の次元も大きくする仕組みを用いてこの問題を解決した.その仕組みとは,入力と出力のどの単語が関連しているのかの関連度を学習することである.
「確認テスト」について自身の考察結果
RNNとword2vecの違い : RNNはボキャブラリ数xボキャブラリ数だけの重みのデータ量であったことに対し,word2vecはボキャブラリ数x任意の単語ベクトルの重みとすることで,現実的な計算量とメモリ量を実現可能にする.
seq2seqとseq2seq+Attentionの違い : seq2seqが固定次元ベクトルしか学習できないのに対して,seq2seq+Attentionは入力と出力の関連度を導入することで,長い文章への対応が可能になる.
参考文献
斎藤 康毅 (2018) : ゼロから作るDeep Learning 2 自然言語編 オライリージャパン