「当てはまるものを全て選択してください。」というようなアンケート設問の、Rを用いたクロス集計分析について考えます。
生データや前提条件は以下のような状況を想定します。
- 選択肢毎に列が割り振られ、選んだかどうか0/1のデータとして入っている。
| ID | 性別 | q1-1 | q1-2 | q1-3 | q1-4 | q1-5 |
|---|---|---|---|---|---|---|
| 1 | 1.男 | 1 | 0 | 1 | 1 | 0 |
| 2 | 2.女 | 1 | 0 | 0 | 1 | 1 |
| 3 | 1.男 | 1 | 1 | 1 | 0 | 0 |
#データを模倣して定義したい場合は以下
rawdata <- data.frame(ID = c(1,2,3))
rawdata$`性別` = c("1.男", "2.女", "1.男")
rawdata$`q1-1` = c(1,1,1)
rawdata$`q1-2` = c(0,0,1)
rawdata$`q1-3` = c(1,0,1)
rawdata$`q1-4` = c(1,1,0)
rawdata$`q1-5` = c(0,1,0)
- アンケート取得主体によるが、「-」や日本語のようなRで扱いづらい文字列が列名に含まれることもある。
- クロス集計は2変数まで。
整然データと雑然データ
そもそも最終的なデータの形としては、整然データと雑然データの両方がありえると思います。
それぞれ良いところがあるので、両方作ります。
参考:https://heavywatal.github.io/slides/tmd2021/1-introduction.html#/9
整然データ
- コンピュータによるデータ集計に向いた形
- Rでグラフを作成(ggplot2)するならこの形にしておかないと厳しい
雑然データ
- コンピュータによるデータ集計には向かないが、人の目で見やすい
- Excelでグラフを作るには便利かも
※Rにも優れた作図機能はあるが、意外と重要な観点です。
ただし、雑然データと言えど1セルに複数の情報が入る状況はどうしようもないので、1セル=1情報は徹底します。
ライブラリ
library(dplyr)
library(tidyr)
生データ→雑然データ
group_by + summarise
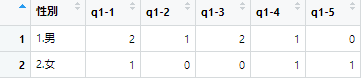
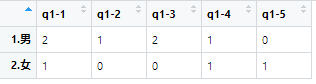
cross <- rawdata %>%
group_by(`性別`) %>%
summarise(`q1-1` = sum(`q1-1`, na.rm = TRUE),
`q1-2` = sum(`q1-2`, na.rm = TRUE),
`q1-3` = sum(`q1-3`, na.rm = TRUE),
`q1-4` = sum(`q1-4`, na.rm = TRUE),
`q1-5` = sum(`q1-5`, na.rm = TRUE))
結果
ポイント
- group_byの前にfilterをかませることで、分析の対象を絞る。
- group_byの中身を変えれば別の列に基づいたクロス集計ができる。
- summarise内でmeanを使えば、割合を出せる。
- 上記例では元と同一にしたが、列名を簡易に指定できる。最終的には、質問番号から選択肢の中身に書き換えたい事が多いと想定されるが、ここで済ませることが可能。
-
合計= n() などを追加することで、(余計な)情報も列に追加できる。計算には邪魔だが、見た目のわかりやすさとしては重要。 - summarise内で効率よく列を選択したい場合はacross関数が有用。※以前はsummarise_eachという関数が用いられていたが、非推奨とのこと。
cross <- rawdata %>%
group_by(`性別`) %>%
summarise(across(starts_with("q1-"), sum, na.rm = TRUE))
※結果は同様。
starts_withの部分を書き替えることで任意の列をパターンで選択できます。
参考:acrossの利用
参考:列の選択方法
欠点はコードが長くなりがちで、summariseの中はある程度手動で書き換える必要がある点です。
コピペ等で大量にさばこうとすると結構大変です。
生データ→整然データ
まず生データを整然な形にして、次に性別および回答の2種類によりグルーピングし、最後に合計を求めます。
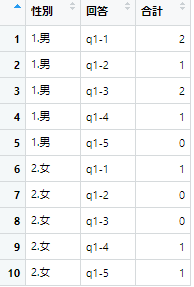
systematic <- rawdata %>%
pivot_longer(c("q1-1","q1-2","q1-3","q1-4","q1-5"),
names_to = "回答",
values_to = "合計") %>% #ここで止めると整然な生データが得られます。
group_by(`性別`, `回答`) %>%
summarise(`合計`=sum(`合計`))
結果
雑然データ→整然データ
2種類やり方を整理しておきます。
pivot_longer(おススメ)
systematic <- cross %>%
pivot_longer(cols = c("q1-1","q1-2","q1-3","q1-4","q1-5"),
names_to = "回答",
values_to = "合計")
結果
生データ→整然データと同様
ポイント
- colsにより、本来値として扱うべき列名を指定する
expand.grid + sapply
expand.gridで全組み合わせをデータフレームに展開し、データを入れていきます。
雑然データはsapplyをかませながらas.integerやas.doubleで型を指定しながら取り出すことで単一のベクトルになり、一つの列として扱えます。
もしくは、もちろん単に値を返す関数でも構いません。
systematic <- expand.grid(`性別` = c("1.男","2.女"),
`回答` = c("q1-1","q1-2","q1-3","q1-4","q1-5")
)
systematic$`合計` <- sapply(cross[,2:6], as.integer) %>% as.integer()
結果
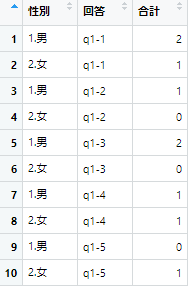
※性別の順番がpivot_longerと異なる。
expand.gridで文字列ベクトルを自分で用意するのはイケてないように見えますが、最終的には選択肢をわかりやすい文字列で示すことも必要なので、案外悪いわけでもありません。
実際にはq1-1ではなく、意味を成す文字列をいれていく使い方をしています。(生データ→雑然データの項で述べたのと同様。)
むしろ厳しいのは雑然データcrossのデータの列を数値で指定(2:6)している点です。
この書き方は、保守性やミスを防ぐことを考えるとできれば避けたいところです。
実際のところ雑然データの形に合わせて変えていくしかありません。雑然データに余計な情報を多く組み込むとしんどくなります。
あえてこちらを使うメリットを挙げるとすれば、pivot_longerの使い方を覚えなくて良いのと、データが複雑になったときに自分で拡張しやすいところでしょうか。
整然データ→雑然データ
自力でやるとしんどいので、素直にpivot_widerを用いるのが良いでしょう。
cross <- systematic %>%
pivot_wider(names_from = `性別`, values_from = `合計`)
結果
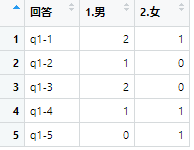
ただし、生データ→雑然データと同じ形にはならず、行列が逆転してしまいます。
ケースバイケースでどちらでもよいのですが、選択肢を列名としたい場合はtで入れ替えて整形するのが良いでしょう。
cross <- systematic %>%
pivot_wider(names_from = `性別`, values_from = `合計`) %>%
t() %>%
as.data.frame()
colnames(cross) <- cross[1,]
cross <- cross[-1,]
結果
※上記の操作だけでは全く同じ形式にはならない。