この記事はElastic Stack (Elasticsearch) Advent Calendar 2019の12日目の記事です。
普段使っているスマホはAndroid、ブラウザはChromeなのでGoogleアカウントに色々データがたまっています。
このデータはダウンロード可能なので、マイアクティビティにあるGoogle検索履歴をElasticsearch + Kibanaで可視化することで1年を振り返ってみようと思います。
Googleアカウントデータのダウンロード
Googleアカウント管理画面の「データとカスタマイズ」から、「データをダウンロード」を選択します。

ダウンロードするデータを選択する画面が出てきますので、適宜必要なデータをダウンロードします。
Elastic Cloudの準備
次にElastic Cloudの準備をします。
メールアドレスの登録だけで14日間のフリートライアル期間があるので、こちらをありがたく使います。
登録したらメールアドレスにリンクが送られてきますので、そこへアクセスするとElastic Cloudが利用できます。
Elastic Stackの準備
さっそく「Create deployment」ボタンを押してElastic Stackを準備してみましょう。
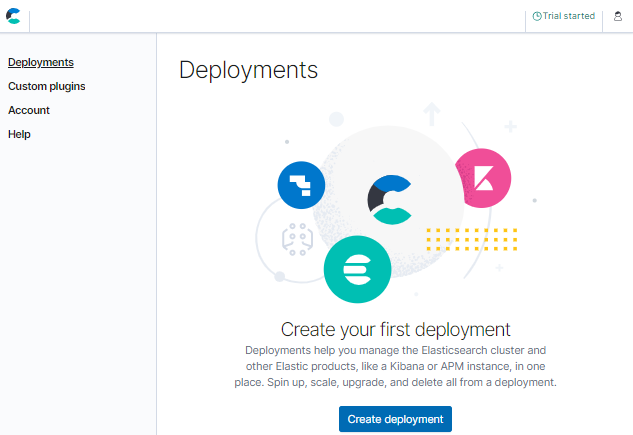
まずは適当に名前を決めて利用するクラウドプラットフォームとリージョンを選択します。
利用したいクラウドプラットフォームのアカウントを別途持っている必要はありませんので、好きなものを選べます。
特にこだわりはありませんが、今回はGoogleアカウントのデータを可視化するのでGoogle繋がりでGCPを選びました。
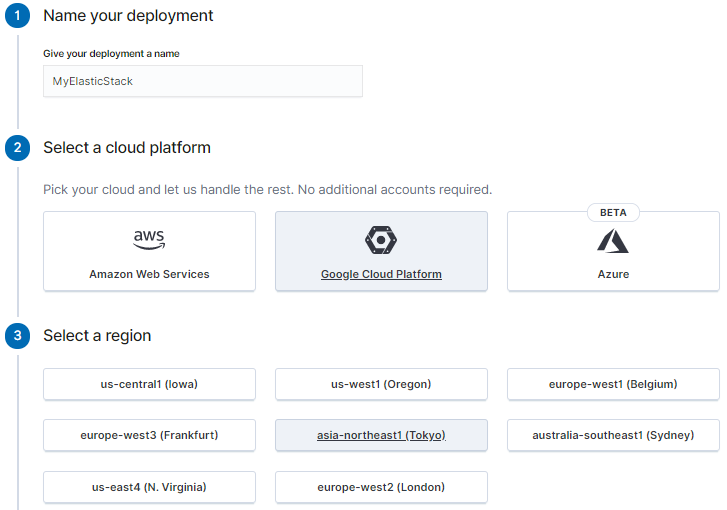
次にバージョンとインスタンスのタイプを選択します。
バージョンは執筆時点で最新の7.5.0を選びました。
インスタンスのタイプは利用用途に合わせてCPUやメモリが強いものが選べるようですが、今回は何でも良いのでRecommendedの「I/O Optimized」を選びます。
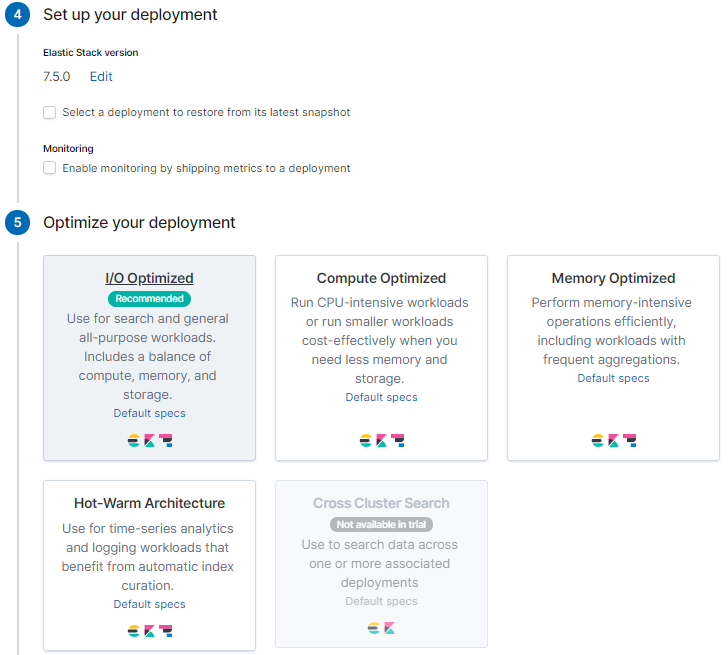
RAM等の各種設定がデフォルトのままで良ければこれだけでOKです。簡単ですね!
カスタマイズ可能な項目
このまま環境を作ってしまっても良いのですが、「Customize deployment」ボタンを押すことでもう少し詳細な設定が出来ます。
せっかくなので何がカスタマイズ可能なのかざっくり見ていきます。ちなみにこれらの項目はデプロイ後も変更可能です。
Elasticsearch
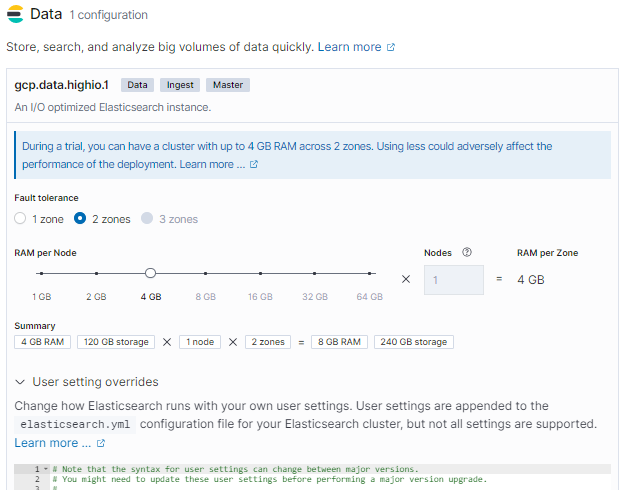
RAMやフォールトトレランスのための設定ができます。(トライアルだと2つのゾーンで4GB RAMまで設定できるよー的な説明が出てますね)
さらに「User setting overrides」の部分からelasticsearch.ymlの設定追加が可能なようです。
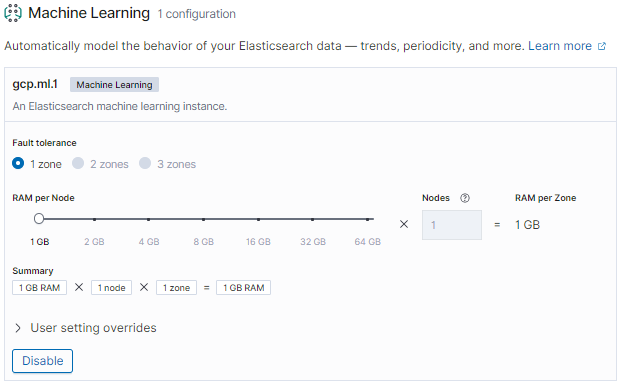
Machine Learning
MLが出た当初はElastic Cloudだと使えなかった気がしますが、ずいぶん前にElastic Cloudでも使えるようになったと記憶しています。ただ今回は使わないのでDisableにしちゃいます。
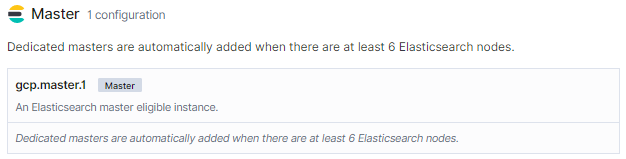
Master専用ノード
Elasticsearchのノード数が6以上になるとマスター専用ノードが追加されるようですね。今は特に何か出来る様子はありません。
Elasticsearchのプラグイン
全文検索をしたいときにおなじみのanalysis-icuやanalysis-kuromojiなどはここで追加できるようです。

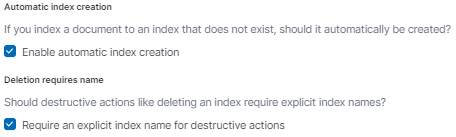
インデックス関係の設定
以下の2つが設定できるようです。この辺はelasticsearch.ymlで指定していたと思いますが、比較的よく指定する項目なのでチェックボックスで簡単に設定できるのは良いですね。
- 存在しないインデックスに対してドキュメントが追加されたときに自動的にインデックスを作成するか
- 削除系の操作をする際にインデックス名を厳密に指定する必要があるか
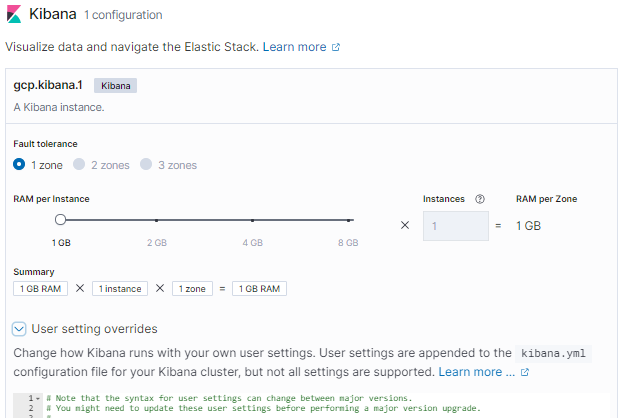
Kibana
設定できる項目やkibana.ymlの設定追加ができるところなどElasticsearchと同じですね。
APM
ElasticsearchやKibanaと同じような項目をAPMでも設定できます。これも今回は使わないのでDisableにしちゃいます。
設定が完了したら、いざデプロイ!今回の設定だと大体2, 3分ほど待ったら環境が立ち上がりました。お手軽ですね~!
Elasticsearchへのデータ追加
Elastic Cloudの準備は出来たので、まずはダウンロードしたGoogleアカウントのデータをElasticsearchに入れます。
データ追加にはKibanaのData Visualizerの機能を使います。
Data VisualizerはCSVやJSONのファイルをアップロードするだけで自動的にデータ型の判定やマッピングの設定を作ってデータをインポートしてくれる機能です。
KibanaのMachine learning > Data Visualizer > Import data からファイルをアップロードします。
今回使うGoogleアカウントのデータはJSONなのですが、JSONの場合はドキュメントにしたい単位で改行区切りになっている形式にする必要があるので、そこだけ手で編集しました。(と言っても空白と改行を正規表現で当てて消した程度ですが)
アップロードすると以下のような感じでフィールドと型を自動的に検出してくれます。

「import」ボタンを押すとインデックス名やマッピングなどを設定できる画面に遷移しますので、適宜変更します。
再び「import」ボタンを押すとデータがアップロードされて自動的にインデックスが作成されます。
データの整形
とりあえずデータは入りましたが、そのままだと可視化向きのデータにはなっていませんので整形します。
ETLツールにはLogstashを使い、Elasticsearch -> Logstash -> Elasticsearch の流れでデータ整形を行います。
Logstashをローカルに立てて動かしますが、セットアップは公式ドキュメントのインストール手順を元に必要最低限の設定だけを行いましたので手順は割愛します。
pipelineの設定
Elasticsearchからの入出力はElasticsearch input pluginとElasticsearch output pluginを使います。
プラグインでぱぱっとElasticsearchと連携できるのはさすがLogstashですね。
Elasticsearch input pluginを使うと自動的にScroll APIを使ってくれるのも地味に嬉しいポイントです。
これにより1回のリクエストで取得するドキュメント数を簡単に調整することが出来ます。
さて、肝心のデータ整形ですが、元データは以下のようになっています。
{
"@timestamp" : "2019-11-20T09:12:02.734Z",
"header" : "検索",
"time" : "2019-11-20T09:12:02.734Z",
"title" : "「 elasticsearch 勉強会 」を検索しました",
"titleUrl" : "https://www.google.com/search?q=elasticsearch+%E5%8B%89%E5%BC%B7%E4%BC%9A",
"products" : [ "検索" ],
"locationInfos" : [ {} ]
}
検索したキーワードがtitle、日付がtimeに入っています。ですので、このデータを以下のような流れで整形し、スペースで分割した検索キーワードの配列と検索日付のみのデータを作ります。
- 使うフィールドを
titleとtimeだけにする -
titleに含まれる「「」を検索しました」の文字列を削る - 全角スペースを半角スペースに変換
-
titleを半角スペースで分割
これを行うLogstashの設定ファイルは以下のような感じにしました。
input {
elasticsearch {
hosts => ['ELASTICSEARCH_URL']
index => 'raw-search-history'
query => '{ "query": { "match_all": {} } }'
size => 250
}
}
filter {
mutate {
remove_field => [ "@timestamp", "header", "titleUrl", "products", "locationInfos" ]
}
mutate {
gsub => [
"title", "「 ", "",
"title", " 」を検索しました", "",
"title", " ", " "
]
}
mutate {
split => { "title" => " " }
}
}
output {
elasticsearch {
hosts => ['ELASTICSEARCH_URL']
index => 'mutated-search-history''
}
}
これで以下のようなドキュメントが作れました。
{
"title" : [
"elasticsearch",
"勉強会"
],
"time" : "2019-11-20T09:12:02.734Z"
}
検索履歴の可視化
データは準備できたので、いよいよ検索履歴をKibanaで可視化します。
グラフはKibanaの魅力の一つでもあるタグ クラウドを利用します。
というわけで、今年の検索回数トップ30を可視化してみた結果がこちら!

今年一番検索したキーワードは「go」でした。
確かに今年の初めぐらいからGo言語に入門したので、一番調べたような気がします。
それ以外にも英語の意味を調べたりワールドカップがあったのでラグビーも良く調べていたみたいです。
elasticsearch, logstash, kibanaは全部ランキング入りしてます。(何ならelasticも)
こうやって見ると思ったよりも1年を振り返れましたね。
まとめ
データ投入から整形、可視化までの全てをElastic Stackで実現しました。この辺のツールが一式全部揃って簡単に連携できるのはElastic Stackの魅力ですね!
環境もElastic Cloudを利用してかなりお手軽に用意できました!
Elastic Stackはかなり幅広い用途で利用できますので、色々なシーンで生かしていけると良いなと思います!
明日は@takashi1029さんです!