e-Statとは
e-Statとは日本の統計が閲覧できる政府統計ポータルサイトである。各省庁が公表しているデータは基本的にe-Statから入手可能である。e-Statでのデータ入手方法は2通りある。1つ目がポータルサイトをポチポチと押してダウンロードする方法、2つ目がAPI経由でダウンロードする方法だ。本記事では2つ目のAPI経由でのダウンロードする方法を紹介する。
前準備
e-StatのAPIを利用するには事前にユーザー登録を行わなければならない。e-Statで登録した後、マイページ▶API機能(アプリケーションID発行)からアプリケーションIDを発行する。発行する際に必要となるURLには、公開サイトで利用しない場合は、ローカルアドレス(「http://test.localhost/」等)を入力すればいい。
JSON形式のデータをpythonで取得
# モジュールのインポート
import pandas as pd
import numpy as np
import urllib
import requests
import json
appId = "***************************" # 発行したアプリケーションIDを入れる
base_url = "http://api.e-stat.go.jp/rest/3.0/app/json/" #/json/と入れることでjson形式を指定
API用のURLを作成してリクエストする関数を作成する。
def url_request(base_url, api_method, params):
params_str = urllib.parse.urlencode(params)
url = base_url + api_method + "?" + params_str
json = requests.get(url).json()
return json
e-Statではデータセットを指定するためのユニークなidが設けられている。idの検索方法としてgetStatListメソッドを用いた方法を紹介する。今回は検索したいワードとして"生鮮野菜価格動向調査"を入れる。
def get_MetaInfo(search_word):
api_method = "getStatsList"
params = {
"appId": appId,
"searchWord": search_word
}
json = url_request(base_url, api_method, params)
return json
stat_list = get_MetaInfo(search_word = "生鮮野菜価格動向調査") # 検索したいワードを入れる
stat_list_ = stat_list["GET_STATS_LIST"]["DATALIST_INF"]["TABLE_INF"]
stat_df = pd.io.json.json_normalize(stat_list_)
stat_df.head()
| @id | STATISTICS_NAME | CYCLE | SURVEY_DATE | OPEN_DATE | SMALL_AREA | COLLECT_AREA | OVERALL_TOTAL_NUMBER | UPDATED_DATE | DESCRIPTION | ... | MAIN_CATEGORY.@code | MAIN_CATEGORY.$ | SUB_CATEGORY.@code | SUB_CATEGORY.$ | STATISTICS_NAME_SPEC.TABULATION_CATEGORY | STATISTICS_NAME_SPEC.TABULATION_SUB_CATEGORY1 | TITLE_SPEC.TABLE_CATEGORY | TITLE_SPEC.TABLE_NAME | TITLE_SPEC.TABLE_EXPLANATION | TITLE_SPEC.TABLE_SUB_CATEGORY1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0003263853 | 生鮮野菜価格動向調査確報 | 年次 | 201601-201612 | 2019-01-11 | 0 | 該当なし | 2340 | 2019-01-12 | ... | 07 | 企業・家計・経済 | 03 | 物価 | 生鮮野菜価格動向調査 | 確報 | 統計表 | 全国の主要都市の並列販売店舗における生鮮野菜の品目別価格及び価格比国産標準品と国産有機栽培品 | 注:1並列販売店舗とは、同じ品目について、国産有機栽培品、国産特別栽培品又は輸入品のいずれ... | 国産標準品と国産有機栽培品 | |
| 1 | 0003263854 | 生鮮野菜価格動向調査確報 | 年次 | 201601-201612 | 2019-01-11 | 0 | 該当なし | 3276 | 2019-01-12 | ... | 07 | 企業・家計・経済 | 03 | 物価 | 生鮮野菜価格動向調査 | 確報 | 統計表 | 全国の主要都市の並列販売店舗における生鮮野菜の品目別価格及び価格比国産標準品と国産特別栽培品 | 注:1並列販売店舗とは、同じ品目について、国産有機栽培品、国産特別栽培品又は輸入品のいずれ... | 国産標準品と国産特別栽培品 | |
| 2 | 0003263855 | 生鮮野菜価格動向調査確報 | 年次 | 201601-201612 | 2019-01-11 | 0 | 該当なし | 1716 | 2019-01-12 | ... | 07 | 企業・家計・経済 | 03 | 物価 | 生鮮野菜価格動向調査 | 確報 | 統計表 | 全国の主要都市の並列販売店舗における生鮮野菜の品目別価格及び価格比国産標準品と輸入品 | 注:1並列販売店舗とは、同じ品目について、国産有機栽培品、国産特別栽培品又は輸入品のいずれ... | 国産標準品と輸入品 | |
| 3 | 0003269440 | 生鮮野菜価格動向調査確報 | 年次 | 201601-201612 | 2019-01-11 | 0 | 該当なし | 3666 | 2019-01-12 | ... | 07 | 企業・家計・経済 | 03 | 物価 | 生鮮野菜価格動向調査 | 確報 | 統計表 | 全国の主要都市における生鮮野菜の販売区分別品目別価格及び店舗数 | 注:1価格は、各店舗ごとの価格の合計を当該品目を販売した店舗数で除した平均値である。2店... | NaN |
今回使いたいデータテーブルは一番上に出てきたid=0003263853とする。このidに対応したデータを取得する関数を作る。先頭5行を表示すれば以下となる。
def get_Info(statsDataId):
api_method = "getStatsData"
params = {
"appId" : appId,
"statsDataId" : statsDataId
}
json=url_request(base_url, api_method, params)
return json
vege_stat = get_Info(statsDataId = "0003263853")
vege_stat_ = vege_stat["GET_STATS_DATA"]["STATISTICAL_DATA"]["DATA_INF"]["VALUE"]
vege_df = pd.io.json.json_normalize(vege_stat_)
vege_df.head()
| @cat01 | @cat02 | @time | @unit | $ | |
|---|---|---|---|---|---|
| 0 | 100 | 100 | 2016000000 | 円/kg | 204 |
| 1 | 100 | 100 | 2016001212 | 円/kg | 293 |
| 2 | 100 | 100 | 2016001111 | 円/kg | 215 |
| 3 | 100 | 100 | 2016001010 | 円/kg | 214 |
| 4 | 100 | 100 | 2016000909 | 円/kg | 210 |
@cat1はカラム名"$"のデータの種類を表し、@cat2は野菜の種類を表す。
vege_cat01 = vege_stat["GET_STATS_DATA"]["STATISTICAL_DATA"]["CLASS_INF"]["CLASS_OBJ"][0]["CLASS"]
vege_cat01_df = pd.io.json.json_normalize(vege_cat01)
vege_cat01_df.head()
| @code | @name | @level | @unit | |
|---|---|---|---|---|
| 0 | 100 | 価格_国産標準品 | 1 | 円/kg |
| 1 | 110 | 価格_国産有機栽培品 | 1 | 円/kg |
| 2 | 140 | 価格_比率 | 1 | % |
| 3 | 150 | (参考)集計対象店舗数 | 1 | 店 |
vege_cat02 = vege_stat["GET_STATS_DATA"]["STATISTICAL_DATA"]["CLASS_INF"]["CLASS_OBJ"][1]["CLASS"]
vege_cat02_df = pd.io.json.json_normalize(vege_cat02)
vege_cat02_df
| @code | @name | @level | |
|---|---|---|---|
| 0 | 100 | だいこん | 1 |
| 1 | 110 | にんじん | 1 |
| 2 | 120 | ごぼう | 1 |
| 3 | 140 | みずな | 1 |
| 4 | 150 | こまつな | 1 |
| 5 | 160 | キャベツ | 1 |
| 6 | 170 | ほうれんそう | 1 |
| 7 | 180 | ねぎ | 1 |
| 8 | 210 | きゅうり | 1 |
| 9 | 230 | なす | 1 |
| 10 | 240 | トマト | 1 |
| 11 | 250 | ミニトマト | 1 |
| 12 | 260 | ピーマン | 1 |
| 13 | 270 | ばれいしょ | 1 |
| 14 | 290 | たまねぎ | 1 |
前処理
前処理の例として、きゅうりとトマトのデータを抽出し、同じ年月で結合することまで行う。
vege1 = vege_df[(vege_df["@cat01"] == "100") & (vege_df["@cat02"] == "210")] #きゅうり
vege2 = vege_df[(vege_df["@cat01"] == "100") & (vege_df["@cat02"] == "240")] # トマト
vege_ = pd.merge(vege1, vege2, on="@time")
vege_ = vege_.rename(columns={'$_x': 'vege1', '$_y': 'vege2'})
vege_ = vege_[["vege1", "vege2"]]
vege_ = vege_.replace('…', np.nan)
vege_ = vege_.replace('-', np.nan)
vege_ = vege_.dropna()
vege_[["vege1","vege2"]] = vege_[["vege1", "vege2"]].astype(float)
print(vege_)
| vege1 | vege2 | |
|---|---|---|
| 0 | 511.0 | 697.0 |
| 4 | 578.0 | 745.0 |
| 5 | 507.0 | 727.0 |
| 6 | 555.0 | 609.0 |
| 7 | 535.0 | 676.0 |
| 8 | 388.0 | 709.0 |
| 9 | 403.0 | 715.0 |
| 10 | 519.0 | 649.0 |
| 11 | 515.0 | 719.0 |
| 12 | 494.0 | 696.0 |
| 13 | 588.0 | 715.0 |
| 14 | 847.0 | 598.0 |
| 16 | 905.0 | 906.0 |
| 17 | 698.0 | 827.0 |
| 18 | 478.0 | 693.0 |
| 19 | 416.0 | 561.0 |
| 20 | 525.0 | 708.0 |
| 21 | 479.0 | 783.0 |
| 22 | 782.0 | 838.0 |
| 23 | 605.0 | 648.0 |
| 24 | 485.0 | 579.0 |
| 26 | 637.0 | 686.0 |
| 29 | 605.0 | 652.0 |
| 30 | 775.0 | 774.0 |
| 31 | 634.0 | 609.0 |
| 32 | 539.0 | 686.0 |
| 33 | 778.0 | 607.0 |
| 34 | 793.0 | 775.0 |
| 36 | 543.0 | 612.0 |
| 37 | 575.0 | 746.0 |
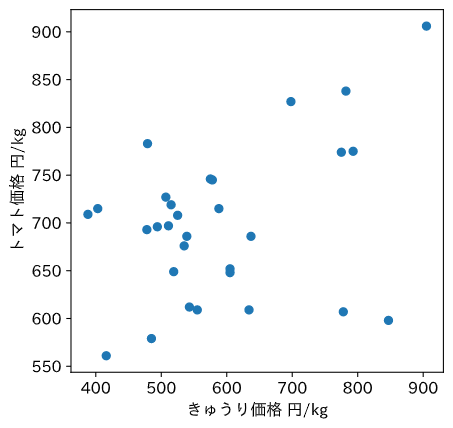
最後に散布図を描写して終わる。
from matplotlib import pyplot as plt
import japanize_matplotlib
fig = plt.figure(figsize=(7, 7))
plt.rcParams["font.size"] = 17
plt.scatter(vege_["vege1"], vege_["vege2"])
plt.xlabel('きゅうり価格 円/kg')
plt.ylabel('トマト価格 円/kg')
plt.show()
クレジット表示
「このサービスは、政府統計総合窓口(e-Stat)のAPI機能を使用していますが、サービスの内容は国によって保証されたものではありません。」