
コピペで利用して頂けることを目指しつつも、お手元のデータに適用するためには、当記事で紹介させて頂くサンプルクエリを参考に、お使い頂く環境に応じてSQLを一部手直し頂く必要があるため、『SQLを少し読める方』向けの内容です。
SQLの実行環境は、『Redshift』を想定しています。
Redshift以外の環境ではクエリの手直しが必要になる場合がありますのでご了承ください。
はじめに
こんにちは、@N1_Data_Ninjya_U です。
普段はニフティ株式会社でData Ninjaとして、分析などのデータ活用の仕事をしています。

N1!Data Ninjaについて詳しくはこちら
ニフティでは、ニフティで「いちばん」その分野に詳しい人、もしくは、いずれ「いちばん」になりうる人、という意味を込めて、N1!(NIFTY No.1)と命名し、職種を問わず、様々な分野で活躍している社員の活躍を後押しするための制度があります。
私は、そのN1!制度の中で”データを使って色々分析や活用”という分野でN1!を頂き、
N1!Data Ninjaという肩書で仕事をしております。※Data Ninjaとは、アメリカの一部で流行っている肩書で、
一般的には
・データアナリスト
・データサイエンティスト
・データエンジニア
などを指す肩書ですが、弊社では
”データを使って色々分析や活用をする人”のような意味で使われています。
本記事では、データ分析において、同じような悩みを抱える方の助けとなればと思い、
データ分析に関する小ネタテクニックをご紹介させて頂きます。
少しでもお悩み解決の助けとなれば幸いです。
また、ニフティでは一緒に働いて頂ける仲間を募集しております!
もし本記事をきっかけにニフティに興味を持って頂けましたら、
就職先・転職先の候補の1つとして、ニフティを選択肢に入れて頂ければ幸いです。
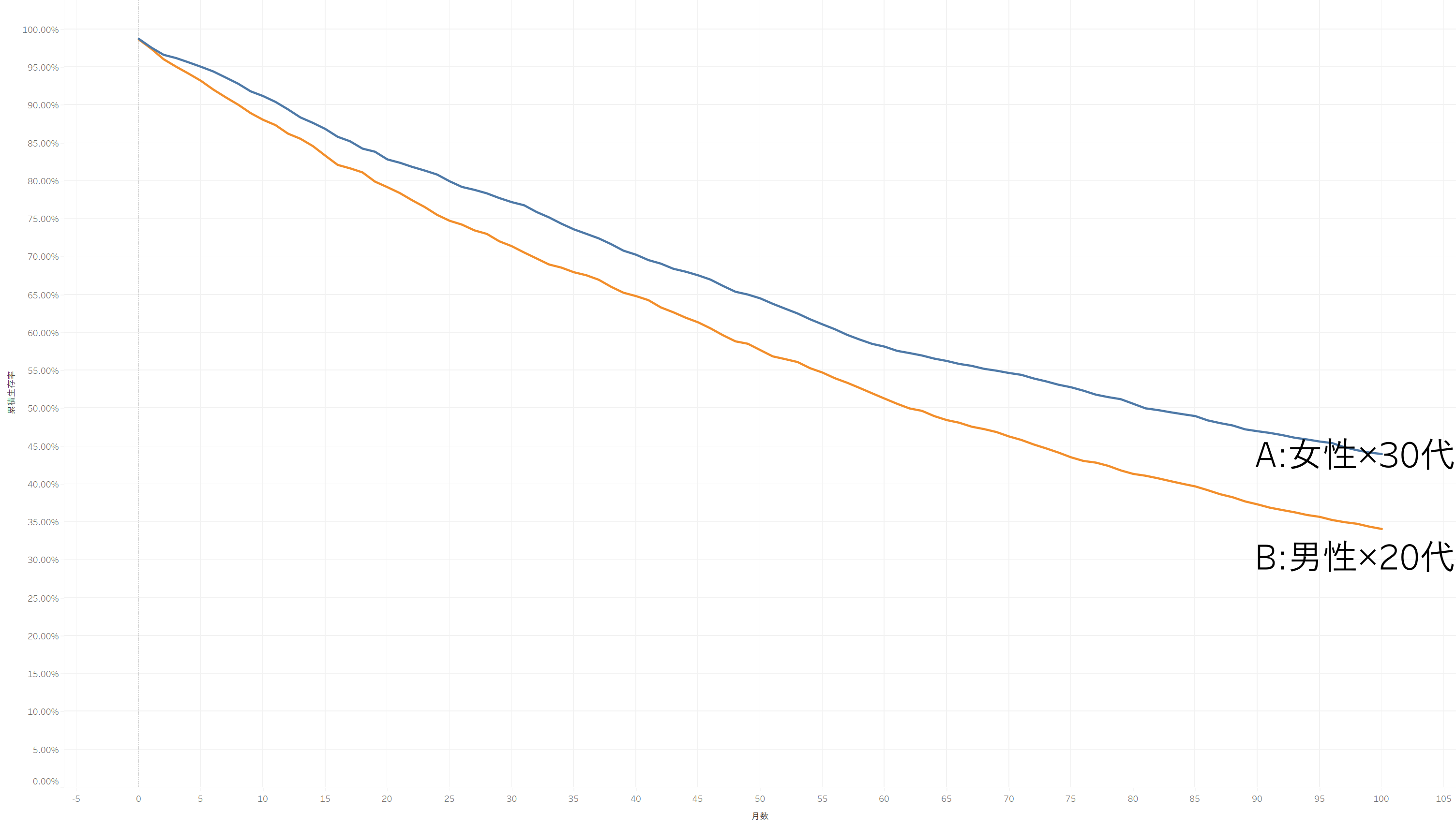
『AとBどちらの属性の方が、どれくらいよりサービスを使い続けて頂けるのか?』にSQLだけて応える!
『AとBどちらの属性の方が、どれくらいよりサービスを使い続けて頂けるのか?』
サブスクリプション系のサービスを展開されている方ですと、
こんな問いを受ける機会が多いのではないでしょうか?
上記の疑問に対して回答を出すのに便利なのが『生存曲線』です。
本記事では、下記のようなデータから、SQLのみで生存曲線を算出する方法をご紹介させて頂きます。
| id | class1 | class2 | start_date | end_date |
|---|---|---|---|---|
| 001 | 女性 | 20代 | 2020-01-03 | 2022-09-12 |
| 002 | 男性 | 30代 | 1998-02-21 | 2020-11-01 |
| 003 | 女性 | 30代 | 2023-03-15 | null |
- ※各カラムの説明
- id
- プライマリーキー
- class1
- 属性1
- class2
- 属性2
- start_date
- 開始日
- end_date
- 終了日
なぜSQLのみで算出する必要があるのか?
生存曲線を算出する方法はBIツール・Pythonを使うなどいくつもあります。
但し、データを扱う方の中で『一番ポピュラーで使える方が多い』『実行環境の準備も比較的簡単』なのがSQLかと思います。
そのSQLのみで完結して算出できることで、
『便利』かつ『関係者への算出方法の共有が楽になる』ことが期待できるため、そこにSQLのみで完結させることの価値があると考えます。
『生存曲線』と『平均月次解約率』・『想定平均利用月数』を算出するSQLクエリ
SQLのみで生存曲線を求めるクエリはこちらです。
『平均月次解約率』と『想定平均利用月数』は生存曲線が、生存曲線が『等比数列』で近似できる(減衰がほぼ一定のペース)場合を前提としてしています。
算出された生存曲線の形を見た上で、『平均月次解約率』と『想定平均利用月数』がそうか使えるか使えるか判断してください。
お手元のデータの仕様に合わせて、サンプルクエリより下記の点を書き変えて頂く必要があります。
-
/*集計粒度(ここから)*/ /*集計粒度(ここまで)*/という記述が10箇所ありますのデータの仕様に合わせて書きかえてください。(※1) -
(120)/*サービス提供期間上限設定値(月数)*/の120の部分を任意の値に変更してください。(※2) -
必要に応じて
サンプル数" >= 300の値を変更しください。
(※1)
サンプルで『class1×class2』としていますが、 データによって集計粒度が異なると思いますので、お手元のデータに合わせて書きかえて頂く必要があります。
(※2)
例)20年にしたい場合は((240)/*サービス提供期間上限設定値(月数)*/としてください。
『想定平均利用月数』の計算に影響します。『想定平均利用月数』を使わない場合は変更不要です。
解約率が低いデータの場合、100年以上など凄く長く続けてくださる飛び値的な方に引っ張られた想定平均値になってしまいます。その平均は最後の1人なるまでサービスを提供し続ける前提での値となってしまい現実的ではなく、過度長大き目な値になってしまうため、サービスを提供し続けたとしても長くて〇〇ヵ月までだろうという値を定める必要があります。
『生存曲線』と『平均月次解約率』・『想定平均利用月数』を算出するSQLクエリ
WITH
base_tb01 AS
(
SELECT
/*集計粒度(ここから)*/
NVL(class1,'null') AS class1,
NVL(class2,'null') AS class2,
/*集計粒度(ここまで)*/
DATEDIFF(month,start_date,
CASE WHEN DATE_TRUNC('month',end_date)<DATE_TRUNC('month',CONVERT_TIMEZONE('Asia/Tokyo',GETDATE()))/*クエリ実行月*/ THEN end_date
ELSE DATE_TRUNC('month',DATEADD('month',-1,CONVERT_TIMEZONE('Asia/Tokyo',GETDATE()))) /*クエリ実行月前月*/ END) AS num_month,
COUNT(id) AS cnt,
COUNT(CASE WHEN DATE_TRUNC('month',end_date)<DATE_TRUNC('month',CONVERT_TIMEZONE('Asia/Tokyo',GETDATE()))/*クエリ実行月*/ THEN id ELSE null END) AS cnt_end
FROM
table /*←参照先のテーブル名に書き変えてください*/
WHERE
start_date IS NOT NULL /*利用開始したデータだけに限定*/
AND
DATE_TRUNC('month',start_date)<DATE_TRUNC('month',CONVERT_TIMEZONE('Asia/Tokyo',GETDATE()))/*クエリ実行月*/ /*利用開始から1ヵ月以上経過していないデータを除外*/
AND
start_date <= NVL(end_date,'9999-12-31')/*終了日が開始日より前になっているデータを除外*/
/*以下任意に絞り込み条件を設定(※絞り込みが不要な場合は、下記2行を削除してください。)*/
AND
class1 IN ('男性','女性')
GROUP BY
/*集計粒度(ここから)*/
class1,
class2,
/*集計粒度(ここまで)*/
num_month
)
SELECT
*,
-("累積生存率"^(1::FLOAT/("利用月数"+1)))+1 AS "月次平均解約率",
CASE WHEN "月次平均解約率"=0 THEN 120/*サービス提供期間上限設定値(月数)*/
ELSE ((1 - "月次平均解約率" )^(120)/*サービス提供期間上限設定値(月数)*/-1)::FLOAT/((1-"月次平均解約率")-1) END AS "想定平均利用月数"
FROM
/*累積生存率をWindow関数で計算--------------------------------------------------------------------------------STR*/
(
SELECT
/*集計粒度(ここから)*/
class1,
class2,
/*集計粒度(ここまで)*/
num_month AS "利用月数",
cnt_r AS "サンプル数",
cnt_end_r AS "その月利用月数での解約数",
/*LN(0)対策*/CASE WHEN cnt_close_r = cnt_r THEN 0 ELSE
/*総積の計算方法の参考ページ https://qiita.com/moriokumura/items/2ba7eed139b34636a939*/
EXP(SUM(LN(1-(/*LN(0)対策*/CASE WHEN cnt_close_r = cnt_r THEN 0 ELSE cnt_close_r END::FLOAT/cnt_r))) OVER(PARTITION BY /*集計粒度(ここから)*/class1,class2/*集計粒度(ここまで)*/ ORDER BY num_month ROWS UNBOUNDED PRECEDING)) END AS "累積生存率"
FROM
(
SELECT
/*集計粒度(ここから)*/
list.class1,
list.class2,
/*集計粒度(ここまで)*/
list.num_month,
SUM(cnt) OVER(PARTITION BY /*集計粒度(ここから)*/list.class1,list.class2/*集計粒度(ここまで)*/ ORDER BY list.num_month DESC ROWS UNBOUNDED PRECEDING) AS cnt_r,
NVL(cnt_end,0) AS cnt_end_r
FROM
/*集計粒度×利用月数のリストを作成する--------------------------------------------------------------------------------STR*/
(
SELECT
/*集計粒度(ここから)*/
class1,
class2,
/*集計粒度(ここまで)*/
num_month
FROM
(
SELECT
/*集計粒度(ここから)*/
class1,
class2,
/*集計粒度(ここまで)*/
MAX(num_month) AS max_num_month
FROM
base_tb01
GROUP BY
/*集計粒度(ここから)*/
class1,
class2
/*集計粒度(ここまで)*/
)
CROSS JOIN
(SELECT ROW_NUMBER() OVER ()-1 as num_month FROM tb02 /*←1000レコード以上ある適当なテーブルを指定してください。*/ LIMIT 1000)
WHERE
num_month <= max_num_month
) AS list
/*集計粒度×利用月数のリストを作成する--------------------------------------------------------------------------------END*/
LEFT JOIN
base_tb01
ON list.num_month = base_tb01.num_month
AND
/*集計粒度(ここから)*/
list.class1 = base_tb01.class1
AND
list.class2 = base_tb01.class2
/*集計粒度(ここまで)*/
)
)
/*累積生存率をWindow関数で計算--------------------------------------------------------------------------------END*/
WHERE
/*サンプル数が一定数以上あるデータのみに限定 (※300程度以上のサンプル数に絞ることをオススメしますが、データ量などが少ない場合は、精度は下がりますが100など任意の値に変更して頂いて問題ありません。)*/
"サンプル数" >= 300
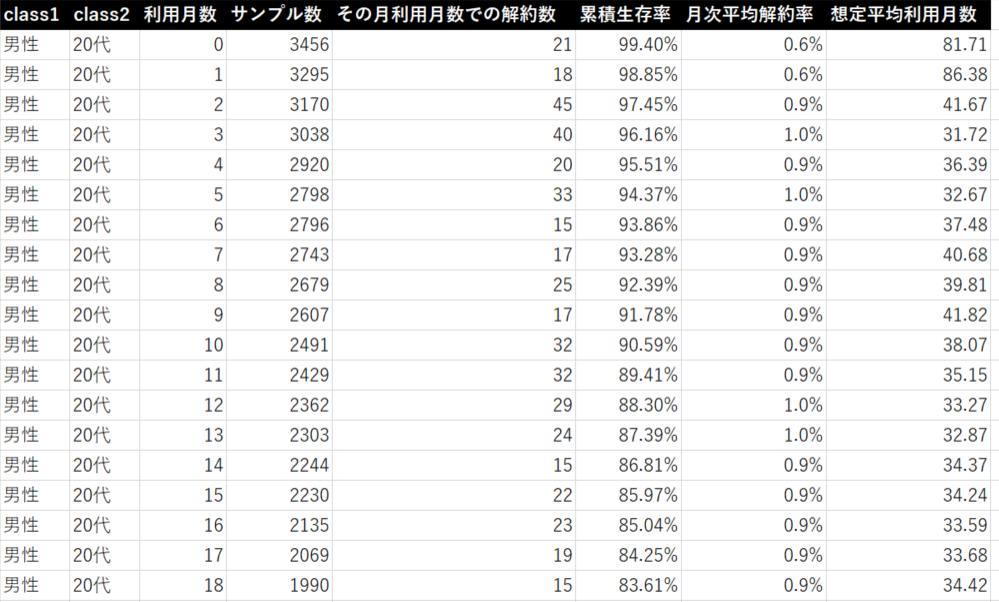
出力結果は下記のようになります。
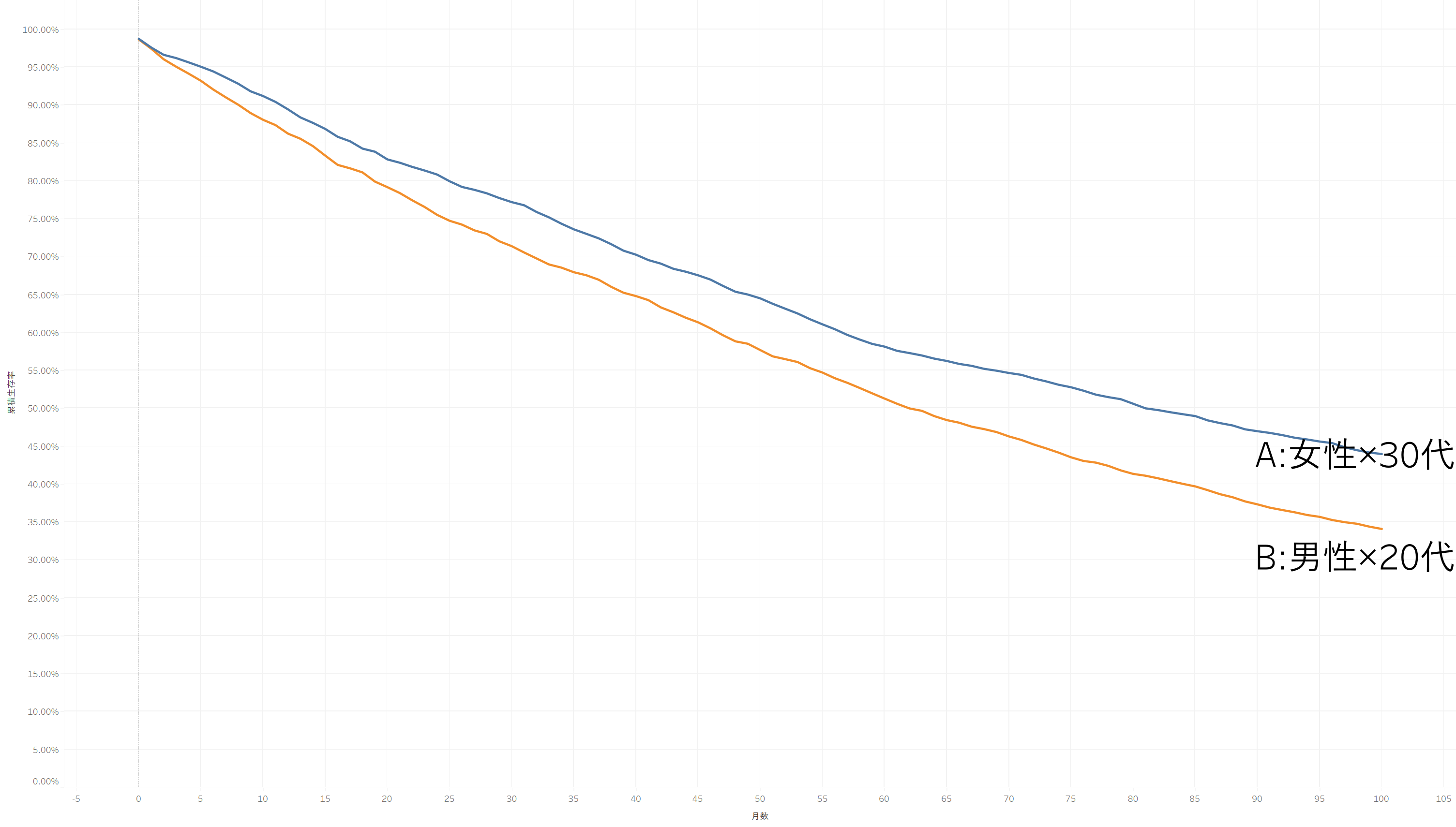
利用月数をX軸,累積生存率をY軸とすると、このような生存曲線グラフが生存曲線が完成します。
おわりに
ぜひお手元のデータで試してみてください。
筆者紹介
ニフティ株式会社でData Ninjaとして、分析などのデータ活用の仕事をしています。
当社についてご興味あれば、以下のリンクをご覧下さい。