私はちょっと情報系な学部に所属しているのですが,情報系だけあって,私の学部には
- 計算すること(シミュレーションなど)
- アルゴリズムを実行して難解な問題を解くこと(競技プログラミングなど)
に強い学生がそこそこいる印象です.しかし,データ整理ができる学生はまだ少ないと見えます.私の学部には学生実験という科目があるのですが,ここでは実験中に様々なデータを取り,それぞれグラフにしてレポートにする必要があります.グラフ作成にPythonはとても役立ちますが,そうすると必ず必要になるのがPython上での実験結果のデータ整理です.
データが1つしか無かったら,普通にファイル読み込み→前処理→計算→グラフ表示...みたいな処理をすればいいな,と頭の中でも思考が付きますが,じゃあ,データが3つあって,それを全て表示するグラフを描け...みたいな複雑な要件になったらどうでしょう.この時に,データを整理しながら,冷静にPythonをいじれるようにする必要があります.
今回は,学生実験のレポートのグラフをPythonで作ることを目標とし,そこに至るまでのPython上でのデータの整理術について少し紹介したいと思います.Pythonで学生実験をDXしましょう!
例1. ●●メートル走記録の比較
問. Alya,Bery,Cillaの3人が50m,80m,100m,200m走をして,それぞれのタイムを記録しました.ヨコ軸を長さ,タテ軸を平均速度[km/h]として,長さに対する平均速度[km/h]を個人別に折れ線グラフで表して下さい.
なお,各長さ[m]に対するタイム[s]は以下の表の通りで,1data.csvとして与えられます.
| Length | Alya | Bery | Cilla |
|---|---|---|---|
| 50 | 8.5 | 7.4 | 10.2 |
| 80 | 14.5 | 12.2 | 18.4 |
| 100 | 20.2 | 17.8 | 24.8 |
| 200 | 58.9 | 43.3 | 68.6 |
目標としているグラフは↓に示すようなものです.
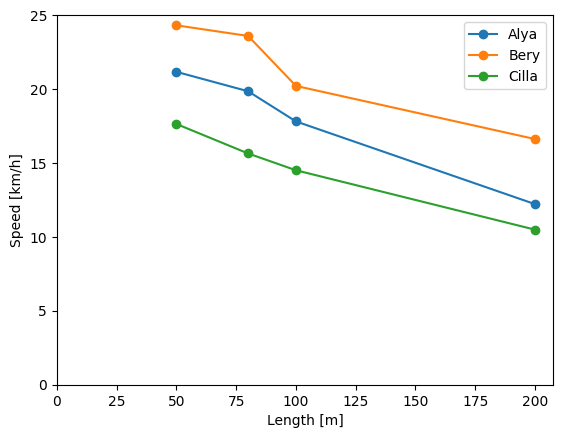
何を整理すべき?
与えられるデータは,長さ[m]とその時のタイム[s]のみです.従って,平均速度[km/h]をグラフに表示するためには,
- 長さとタイムから平均速度[km/h]を求める.
- ↑この処理を計12個(3人$\times$4種)の記録それぞれに同じく行う.
- 計算結果を綺麗にまとめて保存する.
必要があります.ここではそのやり方を実践してみます.
やり方1:Pandasを使う
❶必要なモジュールをインポートします.
import pandas as pd
import matplotlib.pyplot as plt
❷CSVファイルを読み込み,中身を覗いてみます.
raw = pd.read_csv("1data.csv")
print(raw)
Length Alya Bery Cilla
0 50 8.5 7.4 10.2
1 80 14.5 12.2 18.4
2 100 20.2 17.8 24.8
3 200 58.9 43.3 68.6
rawはDataFrameクラスになっています.
❸ここでDataFrameの算術処理について確認します. 列名をインデックスとして当てはめると
raw["Length"]
0 50
1 80
2 100
3 200
Name: Length, dtype: int64
表の縦方向にデータが取り出され,ベクトルとして出力されます.ここでは,4次元のベクトルになっています.では,ベクトル同士で割り算をするとどうなるかというと,
raw["Length"]/raw["Alya"]
0 5.882353
1 5.517241
2 4.950495
3 3.395586
dtype: float64
ベクトルの各要素同士で割り算されます.この計算は...アダマール商 とでも言えばいいでしょうか🤔.これで,それぞれの長さでの速度を一発で計算できることが確認できます.
❹速度の計算後のデータを保存することを考える🔆
先ほどのコード例では,Alyaの記録について,それぞれの長さにおける平均速度[m/s]を求めることができました.これを,他2人についても同じように処理し,処理結果を保存することを考えます.
❺計算後のデータを保存するための空のDataFrameを作ります.
speed_table = pd.DataFrame()
print(speed_table)
Empty DataFrame
Columns: []
Index: []
計算後のデータを保存する先として,既に存在しているrawを使う手もありますが,基本的に,「変数に途中から手を加える」みたいな処理は頭がこんがらがったり,バグの原因になったりするので,避けた方がいいです.
❻Alyaの速度を計算し保存します. そして,保存した後のspeed_tableを確認します.
speed_table["Alya"] = raw["Length"]/raw["Alya"]*3.6
print(speed_table)
Alya
0 21.176471
1 19.862069
2 17.821782
3 12.224109
Alyaのそれぞれの長さでの速さを表す4次元のベクトルが,Alya列に追加されましたね.
処理をする毎に変数(ここではspeed_table)をしつこく確認することをお勧めします.
あなたのコンピューターなのですから,コンピューターが何を処理してどうなったかは,束縛の強い恋人のごとく,頻繁にしつこく心ゆくまで追いかけるべきです.
❼他の2人の速度も計算し保存します.
speed_table["Bery"] = raw["Length"]/raw["Bery"]*3.6
speed_table["Cilla"] = raw["Length"]/raw["Cilla"]*3.6
print(speed_table)
Alya Bery Cilla
0 21.176471 24.324324 17.647059
1 19.862069 23.606557 15.652174
2 17.821782 20.224719 14.516129
3 12.224109 16.628176 10.495627
❽お疲れ様です.完成したspeed_tableを基にグラフを描画します.
plt.figure()
plt.plot(raw["Length"], speed_table["Alya"], label="Alya", marker="o")
plt.plot(raw["Length"], speed_table["Bery"], label="Bery", marker="o")
plt.plot(raw["Length"], speed_table["Cilla"], label="Cilla", marker="o")
plt.xlim(left=0)
plt.ylim(bottom=0)
plt.xlabel("Length [m]")
plt.ylabel("Speed [km/h]")
plt.legend()
plt.show()
ヨコ軸が長さ,タテ軸が速さを表すようにします.そのためには,plt.plot(X,Y)のXには長さのベクトル,Yには速さのベクトルを指定する必要があり,X=raw["Length"],Y=speed_table["名前"]を入れればいいことが分かります.
その他,Matplotlibに関する詳しいことは各自調べて下さい.
やり方2:Pandasを使う(ちょっと賢いやり方で)
やり方1でも十分プラティカルな方法だと思いますが,少し無駄な書き方があります.先ほどのコードを見てもらうと,同じようなコードが人数分繰り返されています.
speed_table["Alya"] = raw["Length"]/raw["Alya"]*3.6
speed_table["Bery"] = raw["Length"]/raw["Bery"]*3.6
speed_table["Cilla"] = raw["Length"]/raw["Cilla"]*3.6 #3回目!!
plt.plot(raw["Length"], speed_table["Alya"], label="Alya", marker="o")
plt.plot(raw["Length"], speed_table["Bery"], label="Bery", marker="o")
plt.plot(raw["Length"], speed_table["Cilla"], label="Cilla", marker="o") #3回目!!
3人ならまだいいかもしれませんが,例えば10人のデータを扱わなければいけない場合,10行も似通ったコードをコピペするのは効率が悪いし,コードの見通しが悪くなります.そこで,for構文などを使って見通しのいい賢いコードに書き換えようと思います.
プログラミングの用語にDRY - Don't Repeat Yourselfというものがあります.これは,似通ったコードを何回も書くな,ということわざです.
❶名前リストというものを作ります🔆
NAME_LIST = ["Alya", "Bery", "Cilla"]
❷名前リストを使ってspeed_tableを賢く作ります. なお,CSVファイルは既にrawとして読み込まれているものとします.
speed_table = pd.DataFrame()
for name in NAME_LIST:
speed_table[name] = raw["Length"]/raw[name]*3.6
print(speed_table)
ここで使うのがfor構文です.以上のコードは,以下のコードと等価です.賢いでしょ
speed_table = pd.DataFrame()
speed_table["Alya"] = raw["Length"]/raw["Alya"]*3.6
speed_table["Bery"] = raw["Length"]/raw["Bery"]*3.6
speed_table["Cilla"] = raw["Length"]/raw["Cilla"]*3.6
print(speed_table)
❸名前リストを使って賢くグラフを描画します.
plt.figure()
for name in NAME_LIST:
plt.plot(raw["Length"], speed_table[name], label=name, marker="o")
plt.xlim(left=0)
plt.ylim(bottom=0)
plt.xlabel("Length [m]")
plt.ylabel("Speed [km/h]")
plt.legend()
plt.show()
forを使うことで,似通った処理を自動的に行なってくれるようになりました.データ整理では,このように,コンピューターができることはなるべくコンピューターに任せるといいと思います.
まとめ
Pythonは数式処理や複雑なアルゴリズムの実行,グラフ描画にとても適した言語です.なので,データ整理のテクニックも学べば,学生実験などでのグラフ描画も簡単に行えるほどのパワーを引き出すことができます.
例ややり方は,適宜追加していこうと思います.