今回は精度向上に挑戦してみた。
結果からいうと、どうも使えないかなって感じがする。
以下の二つを参考にした。
【参考】
①Pythonで日本語OCRを行うときのメモ
②甲骨文字で書かれた文章をOCRで読み取れるようにしてみる
やったこと
・読込・解釈するモードを変更してみる
・精度を上げるために、
①学習済データを変える
②学習してみる
・読込・解釈するモードを変更してみる
参考①から以下の読み込みパラメータを変更できることを知ったので、これをやってみた。
結果は、やはり6が一番よさそうである。
※詳細は省略します
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
次に、実はもともとOCRなので全体を読み・解釈するをやってみた。
コードは以下のとおり、
with open('rect_line.txt', 'w', newline='\n', encoding="utf-8") as f:
for i in range(0,1,1):
txt = tool.image_to_string(
Image.open("./data1/kiseki_"+str(i)+".jpg"),
lang=lang_setting, # "jpn",
builder=pyocr.builders.LineBoxBuilder(tesseract_layout=6) #6 LineBoxBuilder #TextBuilder
)
# 認識範囲を描画
out = cv2.imread("./data/8_1_roi_"+str(i)+".jpg")
for d in txt:
print(d.position)
cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2) # 赤い枠を描画
plt.imshow(out)
plt.pause(1)
plt.close()
txt=d.content
print( txt )
f.write(txt+'\n')
結果(jpn_best)は以下ようなものとなります。
※総じて、画像抽出してやるよりは精度は落ちる結果になりました
(keras-gpu) C:\Users\user\AppData\Local\Tesseract-OCR>python pyocr_lineBox_read.py
['eng', 'jpn', 'jpn1', 'jpn_best', 'jpn_fast', 'jpn_vert', 'jpn_vert_fast', 'kib', 'num', 'osd']
jpn_best
Will use tool 'Tesseract (sh)'
((4, 6), (105, 15))
2019 年 3 月 31 日 語 守
((3, 10), (106, 38))
太尾
((64, 36), (94, 44))
14 還 6
((4, 36), (105, 56))
ba
((4, 60), (105, 70))
三田 音 音 Se
((4, 75), (105, 83))
ww ea
((5, 88), (105, 98))
良 S08kg
((9, 101), (105, 110))
21212|2 生 354
((5, 114), (53, 122))
アル アイ ン
((8, 128), (32, 138))
(on
位置は比較的に正確に取得できまました。
そして、まとめてOCRできるのがメリットです。
しかし、精度はいまいちな感じです。
・精度を上げるために
①学習済データを変える
公開されているデータは以下にある
・tesseract-ocr / tesseract
Updated Data Files for Version 4.00 (September 15, 2017)
We have three sets of .traineddata files on GitHub in three separate repositories.
https://github.com/tesseract-ocr/tessdata_best
https://github.com/tesseract-ocr/tessdata_fast
https://github.com/tesseract-ocr/tessdata
この3つのデータは、普通のユーザーはtessdata_fastがいいと推奨されています。
確かに、一番処理が速く、精度も得られました。
tessdata_bestは少し処理は犠牲にするけど、精度があがり、これをベースに再学習するのが良いとのことです。
使ってみると、あんまり精度は変わらない感じでした。
tessdataは前のバージョンに対応しているものだそうです。
ということで、これらをそれぞれ使うのと、さらに組み合わせて使ってみましたが、ぴったんこな精度はでません。
また、
Data Files for Version 4.00 (November 29, 2016)
といういのもあるので、これも使ってみましたが、いまいちでした。
ということで、これらの組み合わせだと、競馬新聞読みには、tessdata_fastがいいと思います。
※まだまだ精度悪いですが、。。。おまけに組み合わせた場合の例を挙げておきます
②学習してみる
ということで、学習もしてみました。
学習キットは以下のサイトにあります。そして参考②に使い方があります。
以下は、参考②からの受け売りです。
jTessBoxEditorのインストール
Tesseract用の学習データを作成する為のツール「jTessBoxEditor」をインストールします。
インストール方法
下記よりzipファイル「jTessBoxEditor-2.0.zip」をダウンロードします。
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
上記zipファイルを適当なフォルダに解凍します。
起動方法
jTessBoxEditor.jar をダブルクリック or 下記コマンド で起動します。
java -Xms128m -Xmx1024m -jar jTessBoxEditor.jar
※実行には、JRE8以上が必要です。
※Oracleで登録して、ダウンロードしてインストールしました
※起動はダブルクリックしました
使い方は、上記でもわかりますが、以下がさらに詳細に記載してくれています。
【参考】
・③文字認識エンジンTesseract OCRで学習
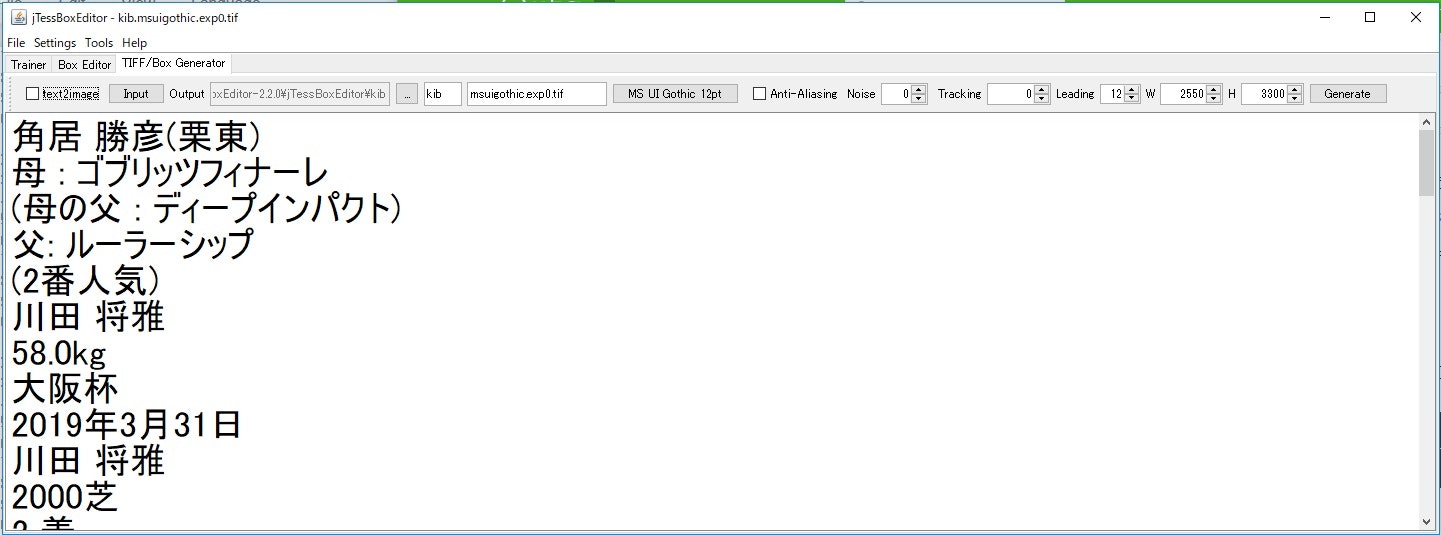
簡単に画像を貼っておきます。
【Generate】
Output;C:\Users\user\Downloads\jTessBoxEditor-2.2.0\jTessBoxEditor\kib
kib;kib.traineddataの最初の3文字
フォント;MS UI Gothic(学習する文字列のフォントだけど、。。。)
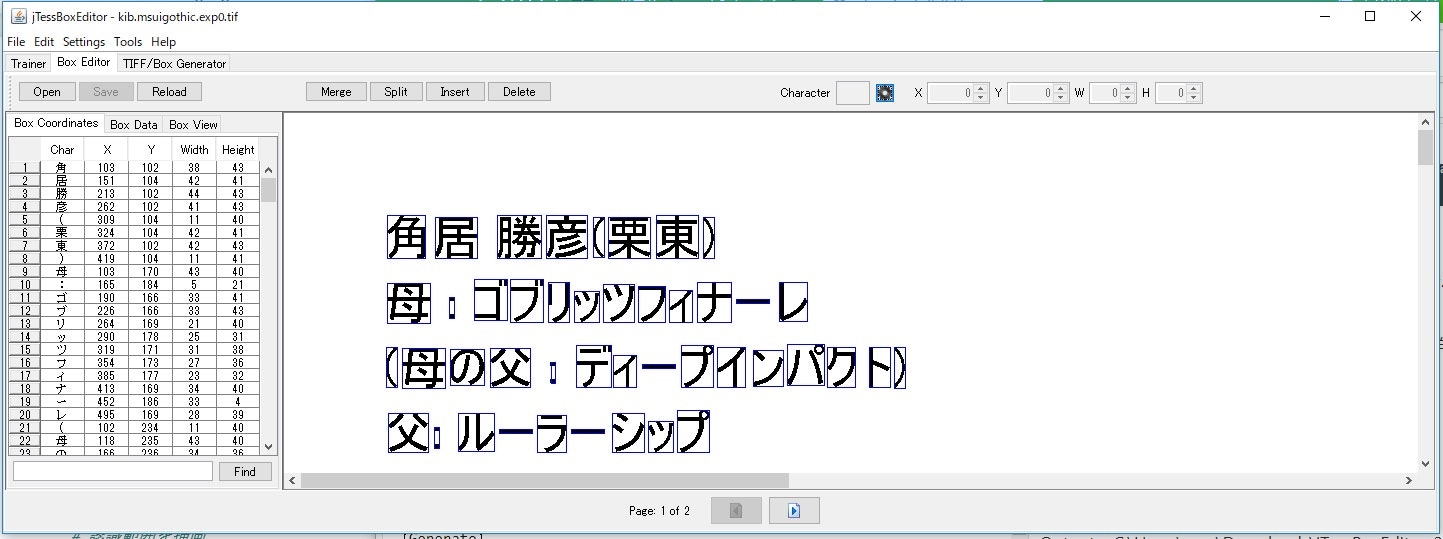
【Training_Tifイメージ】
kib.msuigothic.exp0.tifを開いたところ、以下のようにどのように学習するかTif画像が見えます。
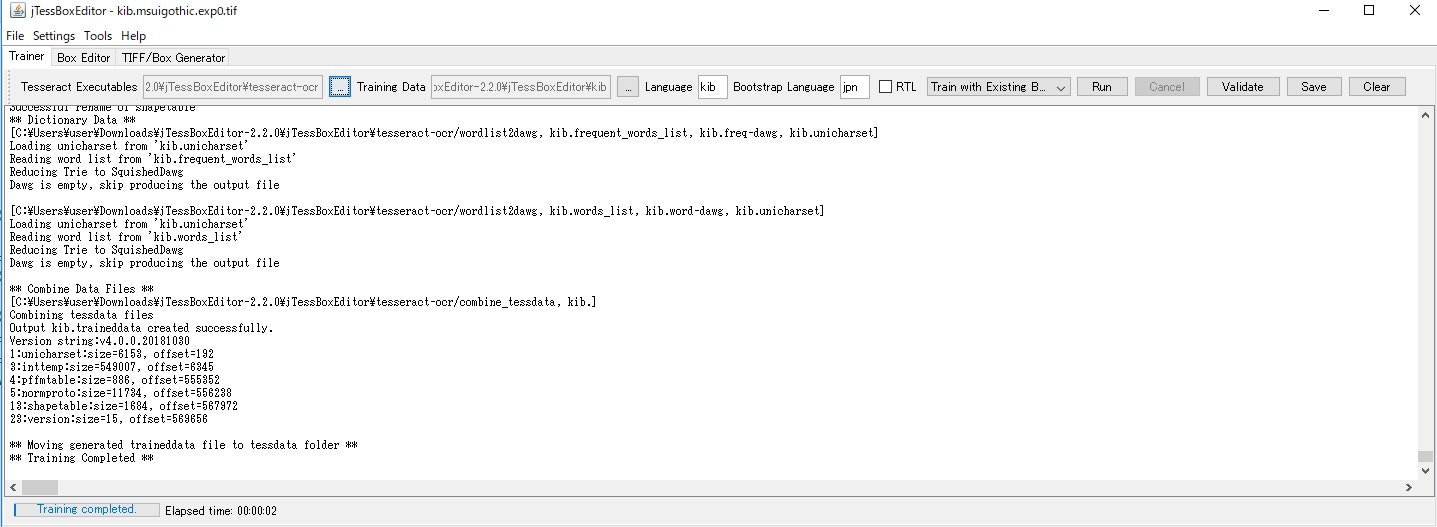
【Training】
TrainingData;kib.msuigothic.exp0.box
Langage;kib
BootstrapLangage;jpn
TrainWithExistingBoxを選ぶ
Runで実行。。。エラーが出なければ下のように終了して、以下のディレクトリにkib.tessdataが生成される。
このファイルをTessaractOCRの実行環境へコピペして使う。
C:\Users\user\Downloads\jTessBoxEditor-2.2.0\jTessBoxEditor\kib\tessdata
C:\Users\user\AppData\Local\Tesseract-OCR\tessdata
学習についてはより具体的には、参考②や参考③の手順を追ってやるとできるようになると思いますので、ここでは詳細は割愛します。
学習データの使い方は、以下のようにします。
# そのOCRツールで使用できる言語を確認
langs = tool.get_available_languages()
print(langs)
# 言語に日本語と今回の学習済みデータ(kib)を指定
lang_setting = langs[1]+"+"+langs[6]
# ['eng', 'jpn', 'jpn_best', 'jpn_fast', 'jpn_vert', 'jpn_vert_fast', 'kib']
としています。
コード全体は以下におきました
・read_keiba_paper /pyocr_lineBox_read.py
まとめ
・OCRの精度をあげようと学習済データの組み合わせをやってみたが精度はあまり上がらなかった
・学習もやってみたが、効果は限定的でそれほど上がらない
・もう少し原理的な部分で改良したいと考えた
おまけ
lang_setting=jpn+jpn1+jpn_best+jpn_fast+jpn_vert+jpn_vert_fastを使った場合
(keras-gpu) C:\Users\user\AppData\Local\Tesseract-OCR>python pyocr_example.py
['eng', 'jpn', 'jpn1', 'jpn_best', 'jpn_fast', 'jpn_vert', 'jpn_vert_fast', 'kib', 'num', 'osd']
jpn+jpn1+jpn_best+jpn_fast+jpn_vert+jpn_vert_fast
Will use tool 'Tesseract (sh)'
角 居 効 彦 ( 柔 束 )
畜 : ブリ ッ ツ フィ ナー レ
( 母 の 父 : デ ィ ー ブ イ ン パ バ ク ト )
父 : ル ー ラ ー シ ッ プ
(② 番 人 気 ) |
ま . さ ③
川 田 封 雅
仕 ⑤/ 黛 鳥
58.0kq
ル ベーw
デ ー
ャ ー
_・ー ご に
良
大 貨 杯
2019 年 3 月 31 互
川 [ 田 封 雅
2000 受
2 荷
ア ル ア イ ン
(0.0)
2
ク
ク
ク
14 6 番
デ ま ペ w
ご Tf イ ノ ト ス ト
③ ③⑤.④
57.0kg
コー
S08kq
阪神
本
有 馬 記 念
2018 年 12 月 23 日 中 山
川 [ 田 封 雅
2500 逐
拐 輝
ら 着
ブラ スト ワン
ピ ー ズ (D.⑥)
1
1
1
1
t も 磁 ⑭ 畑
② 哉 人 気
③F ③⑦.⑤
57.0kq
2・32.8
S06kq
G l
2018 年 11 月 25 日 東京
シ ャ ル ン C
川 田 将 雅
2400 芝
イ (0.3)
フ 着
民
ア ー モ ン ド ア
1
称 昨
1
⑭ 碁 ⑧ 界
④ す 哉 人 気
③F ③④.⑦
57.0kq
ナ ェ フ ロ . ロ
504kq
G |
天 君 贋 ( 秋 )
2018 年 10 月 28 日 束 京
③ 着
川田 封 雄
2000 逐
民
レ イ エ オ ロ
(0.2)
1
ーー]
⑫ 磁 ① 番
ら 孝 人 気
③F ③④.⑦
58.0kq
57.0
496kqg