競馬の予測は、いろいろやられていますが、今回は普通に競馬新聞の情報から予測するために、まず競馬新聞の読み方をやってみた。
やり方は簡単で、各馬のこれまでの成績を読込めばよい。
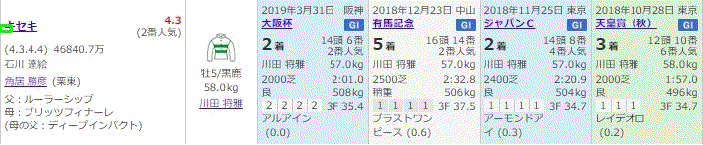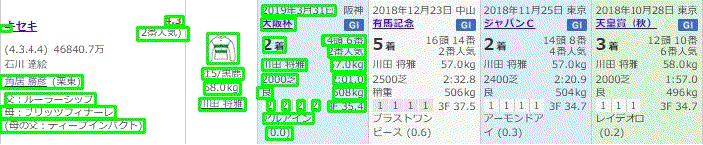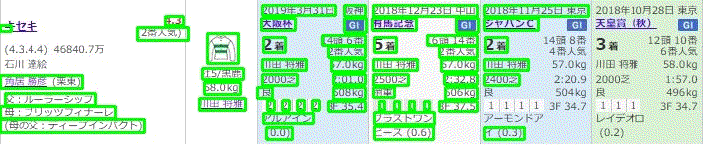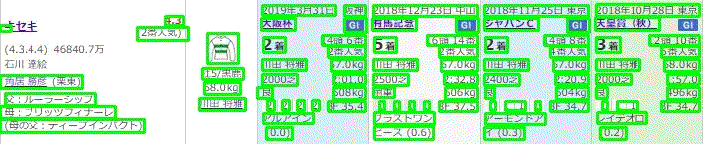
例えば、宝塚記念のキセキの成績が以下のように掲載される。
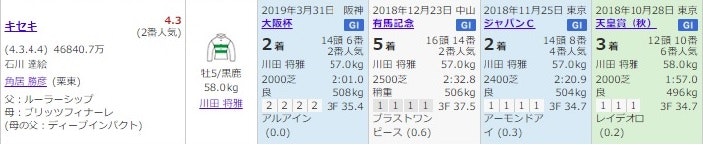
この競馬新聞の情報はかなり充実というか過密に段組みされており、見やすく整理されている。だから、ほんとはその位置情報だけでかなり読めるのかもしれない。
しかし、ここではこれをOpencvの関数で読み込むことを考える。
ちょうど、参考にレシートの読み込みをPythonでやられているのでこれをまねることにする。
※参考①は参考②を綺麗にPythonに移植されています。そしてこのシーケンスを少し変更しようとしましたが、結果は悪くなったのでここでは全く同じコードで実施します。
【参考】
・①OpenCVをPythonで文字の場所をレシートから取得する
・②Receipt Scanner (Text Detection)
当初のコードは以下に置きました
・read_keiba_paper/text_detection.py
コード解説
前半は、参考①②のとおりです。
以下は参考②から引用しました。
My approaches to detect where the texts are:
① Change color space from BGR (or RGB) to Gray
② Apply Morphological Gradient
③ Apply threshold to convert to binary image
④ Apply Closing Morphological Transformation
⑤ Find contours and filter it
以下は参考①からの引用であり、コードはこちらのものを使わせていただきました。
⓪画像の読み取り
①ガウシアンフィルタで画像の平滑化
②Laplacianを使った画像の勾配検出
③大津の手法を使った画像の2値化
④モルフォロジー変換(クロージング)
⑤純粋なクロージング
⑥Laplacianを使った画像の勾配検出
⑦外接矩形
ただし、そのままやると当然抽出されるエリアが不適当になるので、競馬新聞の抽出に合うように以下を変更しました。
1.以下のClosingエリアの大きさを小さくしました
kernel = np.ones((3, 8), np.uint8) #(3, 20)
closing = cv2.morphologyEx(th2, cv2.MORPH_CLOSE, kernel)
これを変更する前は、以下のように抽出します。

すなわち、開催を超えて抽出されるので後でデータを読むことがちょっと難しくなります。上記のように変更すると、正しく分割して抽出してくれます。
2.枠付け順序を左からやれるようにsorted関数を使いました
rect=[]
for i, contour in enumerate(contours):
re = cv2.boundingRect(contour)
rect.append(re)
rect=sorted(rect, key=itemgetter(1))
rect=sorted(rect, key=itemgetter(0))
まず、contours, hierarchy = cv2.findContours(lap2, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)で抽出されたcontoursに対して、上記のようにrectに格納し、それをsortedします。ここでは第二引数(y軸の初期値;できるだけ上から抽出する)でソートしたあと、第一引数(x軸の初期値;左から抽出する)こととします。実際には、このy軸の並べ替えは縦に並んでいるように見えますがpixel単位で見ると少しずれていて、今のところきちんと整列して抽出できていません。
3.位置情報をcsvファイルに格納する
with open(output_root_path +'./rect.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(map(lambda x: x, rect[i]))
4.1と同じような改善ですが、抽出するエリアの面積と大きさを制限しました
まず、面積は以下のようにしました。
min_area = 30 #img.shape[0] * img.shape[1] * 1e-3 #-4
max_area = 2500
...
area = (rect[i][3])*(rect[i][2])
if area < min_area or area > max_area:
continue
元々は全体の面積に対して$10^{-4}$となっていましたが、今回は上記のように最小と最大で制限を加えました。
また、大きさ(w、h)は以下のように制限しています。参考①②では(10,10)以下としていますが、ここでは(5,5)としました。
※このパラメータだと実は肝心のキセキが抽出されないので、さらに追及する必要があります
if rect[i][2] < 5 or rect[i][3] < 5:
continue
上記の改善により以下のような図が得られます。
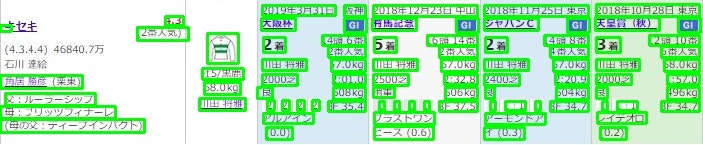
そして、以下のように順次抽出されます。
5.以下がそれぞれの抽出された要素画像です
| 1 | 2 | 3 | 4 |
|---|---|---|---|
 |
 |
 |
 |
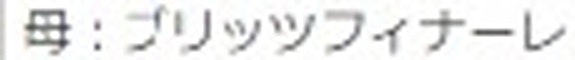 |
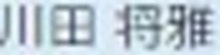 |
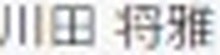 |
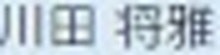 |
 |
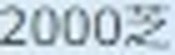 |
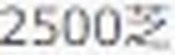 |
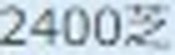 |
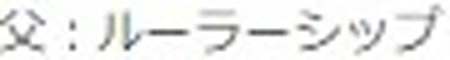 |
 |
 |
 |
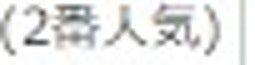 |
 |
 |
 |
 |
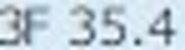 |
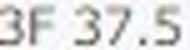 |
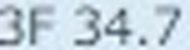 |
 |
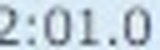 |
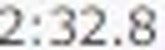 |
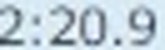 |
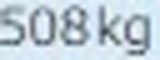 |
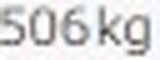 |
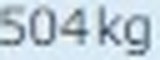 |
|
 |
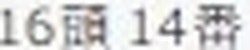 |
 |
|
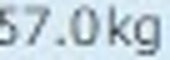 |
 |
 |
|
 |
 |
 |
6.テンプレート方式で順番をそろえる
上記の枠が描かれる順序を上から下にしたいということで、テンプレート方式にしてみました。すなわち、上記で得られたcsvファイルが以下のような並びになっているとします。
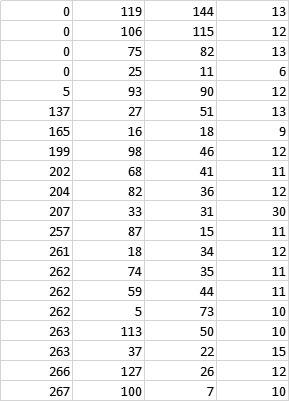
これを以下のように並べ替えてこれを読み込むようにしました。
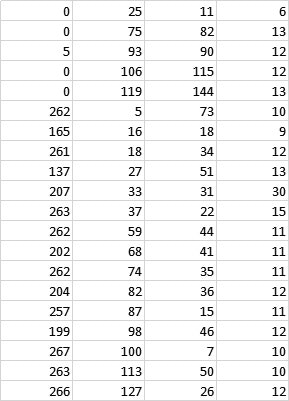
つまり、第一カラムの塊同士(小さな誤差は無視して)で第二カラムでソートすることにより、レース毎の情報を上から読み込むようにしました。
ここで、これを読み込むコードが少しはまりました。
すなわち以下のコードで読めることが分かります。
※因みに、この部分はググっても参考にできるものが無いので工夫しています
すなわち、最初のコードでrect2というstrとしてのlistを読込ます。
rect2=[]
with open(output_root_path+'rect.csv', newline='') as f:
rect1 = csv.reader(f, delimiter=' ', quotechar=' ')
for r in rect1:
r1=', '.join(r)
print(r1)
rect2.append(r1)
そしてこれをnumerateのlistに以下のコードで変換しています。
rect=[]
for i in range(len(rect2)):
str = rect2[i]
a=str.split(",")
rect3=[]
for j in range(4):
rect1=int(a[j])
print(type(rect1),a[j])
rect3.append(rect1)
rect.append(rect3)
こうして得られたcsvファイルを使うと以下のようにだいたい想定した通りの動きをしてくれました。これでデータを読み込んで実際の数字等に変換したときDBなどへの格納が楽になると思います。
※まだ若干並べ替えをさぼっていますが。。。
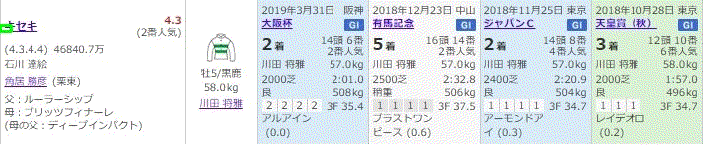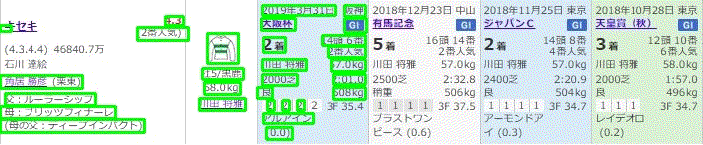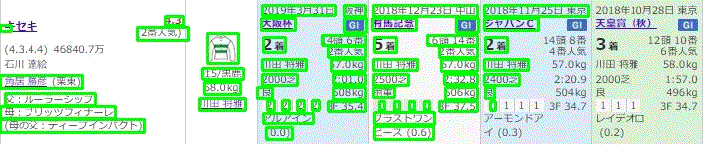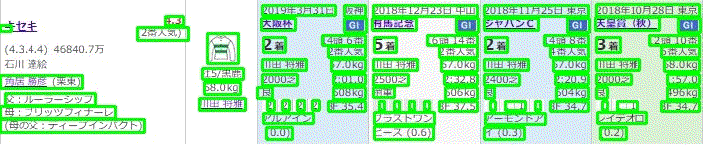
まとめ
・競馬新聞のデータを読めるようになった
・テンプレート方式を利用すると目的のデータを自在に読める
・実際に、数値化するアプリを作成したいと思う
・実際に、データを数値変換して競馬予測をやってみようと思う
以下に最後のコードを掲載する
・read_keiba_paper/contours.py
・read_keiba_paper/contours_read.py