今回はStyleGANを使ってアニメ顔の学習に挑戦してみました。
学習に関する参考はほとんどなく以下のものがありました。結構学習に時間もかかるし、情報も不十分でしたが、一応自前マシンで学習でき、かつ学習途中からの再学習もできたので、記事にまとめておきます。
【参考】
①How To Use Custom Datasets With StyleGAN - TensorFlow Implementation
②styleganで独自モデルの学習方法
③StyleGAN log
④Making Anime Faces With StyleGAN
やったこと
・アニメ顔データの準備
・とにかく学習する
・潜在空間でのミキシングをやってみる
・再学習するには
・アニメ顔データの準備
アニメ顔は以前DCGANで利用したサイトから、ダウンロードして準備しました。
今回の利用のポイントは少なくとも画像サイズを合わせて、かつファイル名を変更して読み取りやすく、1.pngのように変更すること。
StyleGANの学習という意味では目鼻顔などのアラインメントを合わせたいが、次回にパスした。
ということで、上記のデータ整理は以下のコードで実施した。
ちなみにサイズ(128,128)を1000個用意した。
from PIL import Image
import glob
import random
files = glob.glob("./anime/**/*.png", recursive=True)
files = random.sample(files, 1000)
res = []
sk=0
for path in files:
img = Image.open(path)
img = img.resize((128, 128))
img.save( "img/{}.png".format(sk))
sk += 1
・とにかく学習する
学習コードは、参考①のビデオと参考②を眺めつつ、以下のようにした。
kimgは学習image数であり、単位が千imgを意味している。
総学習イメージ数が3400kimgを意味する
次の行は学習開始解像度=4
そして、custom_datasetがtf_recordsに変換した画像のDir(=datasets/custom_dataset)である。さらに、とりあえずの学習ということで、解像度=64で学習してみたが問題なく学習できた。
また、StyleGANはpganであり、サイズ毎学習であるが、サイズ毎のminibatchサイズも以下のとおり、小さめに設定した。
train.total_kimg = 3400、
sched.lod_initial_resolution = 4
desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False
desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2}
つまり、以下の必要最小限で動く。
# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# This work is licensed under the Creative Commons Attribution-NonCommercial
# 4.0 International License. To view a copy of this license, visit
# http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
# Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
"""Main entry point for training StyleGAN and ProGAN networks."""
import copy
import dnnlib
from dnnlib import EasyDict
import config
from metrics import metric_base
# ----------------------------------------------------------------------------
# Official training configs for StyleGAN, targeted mainly for FFHQ.
if 1:
desc = 'sgan' # Description string included in result subdir name.
train = EasyDict(run_func_name='training.training_loop.training_loop') # Options for training loop.
G = EasyDict(func_name='training.networks_stylegan.G_style') # Options for generator network.
D = EasyDict(func_name='training.networks_stylegan.D_basic') # Options for discriminator network.
G_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for generator optimizer.
D_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for discriminator optimizer.
G_loss = EasyDict(func_name='training.loss.G_logistic_nonsaturating') # Options for generator loss.
D_loss = EasyDict(func_name='training.loss.D_logistic_simplegp', r1_gamma=10.0) # Options for discriminator loss.
dataset = EasyDict() # Options for load_dataset().
sched = EasyDict() # Options for TrainingSchedule.
grid = EasyDict(size='4k', layout='random') #4k # Options for setup_snapshot_image_grid().
metrics = [metric_base.fid50k] # Options for MetricGroup.
submit_config = dnnlib.SubmitConfig() # Options for dnnlib.submit_run().
tf_config = {'rnd.np_random_seed': 1000} # Options for tflib.init_tf().
# Dataset.
desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False
# Number of GPUs.
desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2}
# Default options.
train.total_kimg = 3400
sched.lod_initial_resolution = 4
sched.G_lrate_dict = {128: 0.0015, 256: 0.002, 512: 0.003, 1024: 0.003}
sched.D_lrate_dict = EasyDict(sched.G_lrate_dict)
# ----------------------------------------------------------------------------
# Main entry point for training.
# Calls the function indicated by 'train' using the selected options.
def main():
kwargs = EasyDict(train)
kwargs.update(G_args=G, D_args=D, G_opt_args=G_opt, D_opt_args=D_opt, G_loss_args=G_loss, D_loss_args=D_loss)
kwargs.update(dataset_args=dataset, sched_args=sched, grid_args=grid, metric_arg_list=metrics, tf_config=tf_config)
kwargs.submit_config = copy.deepcopy(submit_config)
kwargs.submit_config.run_dir_root = dnnlib.submission.submit.get_template_from_path(config.result_dir)
kwargs.submit_config.run_dir_ignore += config.run_dir_ignore
kwargs.submit_config.run_desc = desc
dnnlib.submit_run(**kwargs)
# ----------------------------------------------------------------------------
if __name__ == "__main__":
main()
# ----------------------------------------------------------------------------
なお、データのtfrecordsへの変換は参考①から以下のように実施した。
※ここで元画像は./animeに入れておく、そして画像サイズ毎の変換ファイルはcustom_datasetに6個のサイズの異なるファイルが格納された。
python dataset_tool.py create_from_images datasets/custom_dataset ./anime
上記でとりあえず、学習できると思う。
・潜在空間でのミキシングをやってみる
1060マシンで上記のコードを10h程度で以下の絵が得られる。
決して綺麗とは言えないが、とにかく最弱マシンでも学習できた。
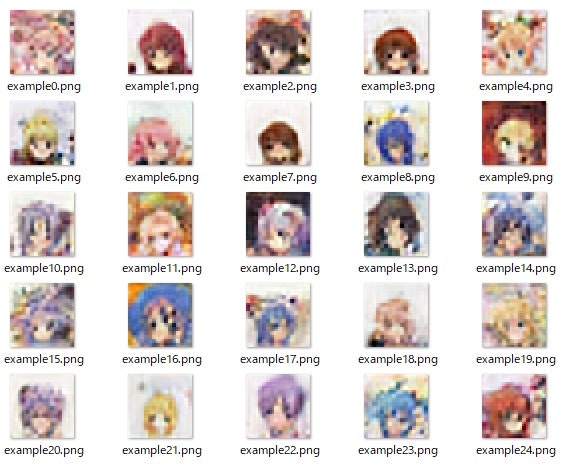
さらに、潜在空間での17,18のミキシングをやってみると以下の絵が得られた。

1080マシンで解像度128x128サイズで1d8h程度回して、kimg=4705の場合以下のように画像がしっかりしてきた。
※これでもpid50K=168程度で精度はまだまだだが、。。。以前のDCGANの画像と比べてこちらの方が綺麗に見える
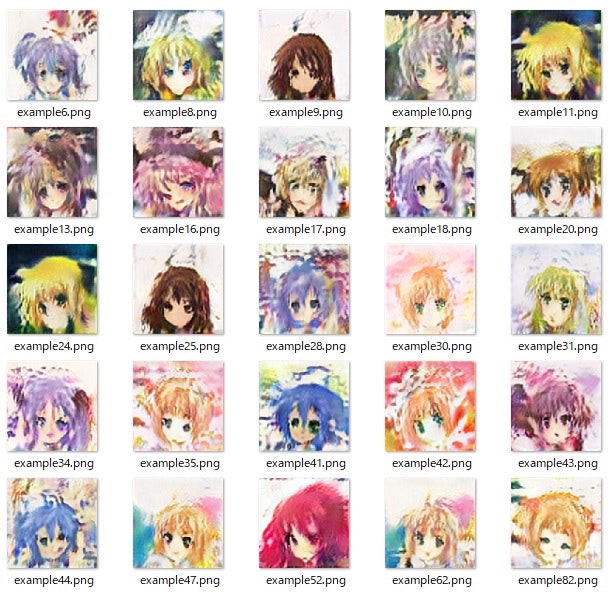
さらに、潜在空間での11,82のミキシングをやってみると以下の絵が得られた。

・再学習するには
最後に禁断(誰も公開していないようなので)の途中中断した場合の継続学習の仕方が出来たので、まとめておく。
※この方法はちょっとだけ参考②と参考④に記載がある
以下のコードで実施する。
すなわち、training_loop.pyの以下の部分を修正する。
resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch.
resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect.
また、network_snapshot_ticks = 1, # How often to export network snapshots? として、毎回出力にしている。
def training_loop(
submit_config,
G_args = {}, # Options for generator network.
D_args = {}, # Options for discriminator network.
G_opt_args = {}, # Options for generator optimizer.
D_opt_args = {}, # Options for discriminator optimizer.
G_loss_args = {}, # Options for generator loss.
D_loss_args = {}, # Options for discriminator loss.
dataset_args = {}, # Options for dataset.load_dataset().
sched_args = {}, # Options for train.TrainingSchedule.
grid_args = {}, # Options for train.setup_snapshot_image_grid().
metric_arg_list = [], # Options for MetricGroup.
tf_config = {}, # Options for tflib.init_tf().
G_smoothing_kimg = 10.0, # Half-life of the running average of generator weights.
D_repeats = 1, # How many times the discriminator is trained per G iteration.
minibatch_repeats = 4, # Number of minibatches to run before adjusting training parameters.
reset_opt_for_new_lod = True, # Reset optimizer internal state (e.g. Adam moments) when new layers are introduced?
total_kimg = 15000, # Total length of the training, measured in thousands of real images.
mirror_augment = False, # Enable mirror augment?
drange_net = [-1,1], # Dynamic range used when feeding image data to the networks.
image_snapshot_ticks = 1, # How often to export image snapshots?
network_snapshot_ticks = 1, # How often to export network snapshots? default=10
save_tf_graph = False, # Include full TensorFlow computation graph in the tfevents file?
save_weight_histograms = False, # Include weight histograms in the tfevents file?
resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch.
resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect.
resume_kimg = 1040.9, # Assumed training progress at the beginning. Affects reporting and training schedule.
resume_time = 5599.0): # Assumed wallclock time at the beginning. Affects reporting.
resume_time = 5599.0
は秒単位で入力する。
このままだとメモリーがたまらないので、さらに上書き保存するためにもう一か所、下のコードのように変更した。
if cur_tick % network_snapshot_ticks == 0 or done or cur_tick == 1:
#pkl = os.path.join(submit_config.run_dir, 'network-snapshot-%06d.pkl' % (cur_nimg // 1000))
pkl = os.path.join(submit_config.run_dir, 'network-snapshot-.pkl')
misc.save_pkl((G, D, Gs), pkl)
metrics.run(pkl, run_dir=submit_config.run_dir, num_gpus=submit_config.num_gpus, tf_config=tf_config)
計算が1080マシンでもかなりかかるので、これを利用した結果については後日公開したいと思う。
まとめ
・自前マシンでStyleGANの学習ができるようになった
・学習データで今まで報告したようなミキシングが出来た
・途中で中断した場合の再開の仕方が分かった
・今回は1000データだが、100以下の少数データの結果も見ようと思う
・さらに精度を追求してスタイルなどもやってみようと思う
おまけ
dnnlib: Running training.training_loop.training_loop() on localhost...
Streaming data using training.dataset.TFRecordDataset...
Dataset shape = [3, 64, 64]
Dynamic range = [0, 255]
Label size = 0
Constructing networks...
G Params OutputShape WeightShape
--- --- --- ---
latents_in - (?, 512) -
labels_in - (?, 0) -
lod - () -
dlatent_avg - (512,) -
G_mapping/latents_in - (?, 512) -
G_mapping/labels_in - (?, 0) -
G_mapping/PixelNorm - (?, 512) -
G_mapping/Dense0 262656 (?, 512) (512, 512)
G_mapping/Dense1 262656 (?, 512) (512, 512)
G_mapping/Dense2 262656 (?, 512) (512, 512)
G_mapping/Dense3 262656 (?, 512) (512, 512)
G_mapping/Dense4 262656 (?, 512) (512, 512)
G_mapping/Dense5 262656 (?, 512) (512, 512)
G_mapping/Dense6 262656 (?, 512) (512, 512)
G_mapping/Dense7 262656 (?, 512) (512, 512)
G_mapping/Broadcast - (?, 10, 512) -
G_mapping/dlatents_out - (?, 10, 512) -
Truncation - (?, 10, 512) -
G_synthesis/dlatents_in - (?, 10, 512) -
G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,)
G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512)
G_synthesis/ToRGB_lod4 1539 (?, 3, 4, 4) (1, 1, 512, 3)
G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512)
G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512)
G_synthesis/ToRGB_lod3 1539 (?, 3, 8, 8) (1, 1, 512, 3)
G_synthesis/Upscale2D - (?, 3, 8, 8) -
G_synthesis/Grow_lod3 - (?, 3, 8, 8) -
G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512)
G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512)
G_synthesis/ToRGB_lod2 1539 (?, 3, 16, 16) (1, 1, 512, 3)
G_synthesis/Upscale2D_1 - (?, 3, 16, 16) -
G_synthesis/Grow_lod2 - (?, 3, 16, 16) -
G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512)
G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512)
G_synthesis/ToRGB_lod1 1539 (?, 3, 32, 32) (1, 1, 512, 3)
G_synthesis/Upscale2D_2 - (?, 3, 32, 32) -
G_synthesis/Grow_lod1 - (?, 3, 32, 32) -
G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256)
G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256)
G_synthesis/ToRGB_lod0 771 (?, 3, 64, 64) (1, 1, 256, 3)
G_synthesis/Upscale2D_3 - (?, 3, 64, 64) -
G_synthesis/Grow_lod0 - (?, 3, 64, 64) -
G_synthesis/images_out - (?, 3, 64, 64) -
G_synthesis/lod - () -
G_synthesis/noise0 - (1, 1, 4, 4) -
G_synthesis/noise1 - (1, 1, 4, 4) -
G_synthesis/noise2 - (1, 1, 8, 8) -
G_synthesis/noise3 - (1, 1, 8, 8) -
G_synthesis/noise4 - (1, 1, 16, 16) -
G_synthesis/noise5 - (1, 1, 16, 16) -
G_synthesis/noise6 - (1, 1, 32, 32) -
G_synthesis/noise7 - (1, 1, 32, 32) -
G_synthesis/noise8 - (1, 1, 64, 64) -
G_synthesis/noise9 - (1, 1, 64, 64) -
images_out - (?, 3, 64, 64) -
--- --- --- ---
Total 25137935
D Params OutputShape WeightShape
--- --- --- ---
images_in - (?, 3, 64, 64) -
labels_in - (?, 0) -
lod - () -
FromRGB_lod0 1024 (?, 256, 64, 64) (1, 1, 3, 256)
64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256)
64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512)
Downscale2D - (?, 3, 32, 32) -
FromRGB_lod1 2048 (?, 512, 32, 32) (1, 1, 3, 512)
Grow_lod0 - (?, 512, 32, 32) -
32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512)
32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512)
Downscale2D_1 - (?, 3, 16, 16) -
FromRGB_lod2 2048 (?, 512, 16, 16) (1, 1, 3, 512)
Grow_lod1 - (?, 512, 16, 16) -
16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512)
16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512)
Downscale2D_2 - (?, 3, 8, 8) -
FromRGB_lod3 2048 (?, 512, 8, 8) (1, 1, 3, 512)
Grow_lod2 - (?, 512, 8, 8) -
8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512)
8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512)
Downscale2D_3 - (?, 3, 4, 4) -
FromRGB_lod4 2048 (?, 512, 4, 4) (1, 1, 3, 512)
Grow_lod3 - (?, 512, 4, 4) -
4x4/MinibatchStddev - (?, 513, 4, 4) -
4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512)
4x4/Dense0 4194816 (?, 512) (8192, 512)
4x4/Dense1 513 (?, 1) (512, 1)
scores_out - (?, 1) -
--- --- --- ---
Total 22498049
Building TensorFlow graph...
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
Setting up snapshot image grid...
Setting up run dir...
Training...
tick 1 kimg 160.3 lod 4.00 minibatch 128 time 5m 35s sec/tick 297.2 sec/kimg 1.85 maintenance 38.0 gpumem 1.7
network-snapshot-000160 time 16m 22s fid50k 454.0154
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
tick 2 kimg 320.5 lod 4.00 minibatch 128 time 26m 00s sec/tick 222.0 sec/kimg 1.39 maintenance 1002.8 gpumem 2.0
tick 3 kimg 480.8 lod 4.00 minibatch 128 time 29m 43s sec/tick 222.0 sec/kimg 1.38 maintenance 1.4 gpumem 2.0
tick 4 kimg 620.8 lod 3.97 minibatch 64 time 33m 41s sec/tick 236.2 sec/kimg 1.69 maintenance 1.2 gpumem 2.0
tick 5 kimg 760.8 lod 3.73 minibatch 64 time 41m 24s sec/tick 462.3 sec/kimg 3.30 maintenance 1.3 gpumem 2.0
tick 6 kimg 900.9 lod 3.50 minibatch 64 time 49m 07s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0
tick 7 kimg 1040.9 lod 3.27 minibatch 64 time 56m 49s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0
tick 8 kimg 1180.9 lod 3.03 minibatch 64 time 1h 04m 31s sec/tick 460.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0
tick 9 kimg 1321.0 lod 3.00 minibatch 64 time 1h 12m 06s sec/tick 453.5 sec/kimg 3.24 maintenance 1.3 gpumem 2.0
tick 10 kimg 1461.0 lod 3.00 minibatch 64 time 1h 19m 40s sec/tick 452.6 sec/kimg 3.23 maintenance 1.3 gpumem 2.0
network-snapshot-001460 time 8m 33s fid50k 378.7820
tick 11 kimg 1601.0 lod 3.00 minibatch 64 time 1h 35m 49s sec/tick 453.8 sec/kimg 3.24 maintenance 515.6 gpumem 2.0
tick 12 kimg 1741.1 lod 3.00 minibatch 64 time 1h 43m 24s sec/tick 453.8 sec/kimg 3.24 maintenance 1.3 gpumem 2.0
tick 13 kimg 1861.1 lod 2.90 minibatch 32 time 1h 57m 38s sec/tick 852.2 sec/kimg 7.10 maintenance 1.3 gpumem 2.0
tick 14 kimg 1981.2 lod 2.70 minibatch 32 time 2h 18m 55s sec/tick 1275.3 sec/kimg 10.62 maintenance 2.0 gpumem 2.0
tick 15 kimg 2101.2 lod 2.50 minibatch 32 time 2h 40m 10s sec/tick 1273.1 sec/kimg 10.60 maintenance 1.9 gpumem 2.0
tick 16 kimg 2221.3 lod 2.30 minibatch 32 time 3h 01m 25s sec/tick 1273.0 sec/kimg 10.60 maintenance 1.9 gpumem 2.0
tick 17 kimg 2341.4 lod 2.10 minibatch 32 time 3h 22m 42s sec/tick 1275.0 sec/kimg 10.62 maintenance 1.9 gpumem 2.0
tick 18 kimg 2461.4 lod 2.00 minibatch 32 time 3h 43m 49s sec/tick 1265.4 sec/kimg 10.54 maintenance 1.9 gpumem 2.0
tick 19 kimg 2581.5 lod 2.00 minibatch 32 time 4h 04m 45s sec/tick 1253.8 sec/kimg 10.44 maintenance 1.9 gpumem 2.0
tick 20 kimg 2701.6 lod 2.00 minibatch 32 time 4h 25m 41s sec/tick 1254.5 sec/kimg 10.45 maintenance 1.9 gpumem 2.0
network-snapshot-002701 time 9m 08s fid50k 338.4830
tick 21 kimg 2821.6 lod 2.00 minibatch 32 time 4h 55m 47s sec/tick 1255.4 sec/kimg 10.46 maintenance 551.1 gpumem 2.0
tick 22 kimg 2941.7 lod 2.00 minibatch 32 time 5h 16m 44s sec/tick 1254.7 sec/kimg 10.45 maintenance 1.8 gpumem 2.0
tick 23 kimg 3041.7 lod 1.93 minibatch 16 time 5h 52m 23s sec/tick 2136.8 sec/kimg 21.36 maintenance 1.8 gpumem 2.0
tick 24 kimg 3141.8 lod 1.76 minibatch 16 time 6h 52m 21s sec/tick 3593.7 sec/kimg 35.93 maintenance 4.5 gpumem 2.0
tick 25 kimg 3241.8 lod 1.60 minibatch 16 time 7h 52m 23s sec/tick 3597.7 sec/kimg 35.97 maintenance 4.5 gpumem 2.0
tick 26 kimg 3341.8 lod 1.43 minibatch 16 time 8h 52m 34s sec/tick 3606.5 sec/kimg 36.05 maintenance 4.6 gpumem 2.0
tick 27 kimg 3400.0 lod 1.33 minibatch 16 time 9h 27m 29s sec/tick 2090.0 sec/kimg 35.92 maintenance 4.6 gpumem 2.0
network-snapshot-003400 time 11m 15s fid50k 327.9088
dnnlib: Finished training.training_loop.training_loop() in 9h 38m 52s.
(keras-gpu) C:\Users\user\stylegan-master>python train.py
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
Creating the run dir: results\00004-sgan-custom_dataset-1gpu
Copying files to the run dir
dnnlib: Running training.training_loop.training_loop() on localhost...
Streaming data using training.dataset.TFRecordDataset...
WARNING:tensorflow:From C:\Users\user\stylegan-master\training\dataset.py:76: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version.
Instructions for updating:
Use eager execution and:
`tf.data.TFRecordDataset(path)`
WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
Dataset shape = [3, 128, 128]
Dynamic range = [0, 255]
Label size = 0
Constructing networks...
G Params OutputShape WeightShape
--- --- --- ---
latents_in - (?, 512) -
labels_in - (?, 0) -
lod - () -
dlatent_avg - (512,) -
G_mapping/latents_in - (?, 512) -
G_mapping/labels_in - (?, 0) -
G_mapping/PixelNorm - (?, 512) -
G_mapping/Dense0 262656 (?, 512) (512, 512)
G_mapping/Dense1 262656 (?, 512) (512, 512)
G_mapping/Dense2 262656 (?, 512) (512, 512)
G_mapping/Dense3 262656 (?, 512) (512, 512)
G_mapping/Dense4 262656 (?, 512) (512, 512)
G_mapping/Dense5 262656 (?, 512) (512, 512)
G_mapping/Dense6 262656 (?, 512) (512, 512)
G_mapping/Dense7 262656 (?, 512) (512, 512)
G_mapping/Broadcast - (?, 12, 512) -
G_mapping/dlatents_out - (?, 12, 512) -
Truncation - (?, 12, 512) -
G_synthesis/dlatents_in - (?, 12, 512) -
G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,)
G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512)
G_synthesis/ToRGB_lod5 1539 (?, 3, 4, 4) (1, 1, 512, 3)
G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512)
G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512)
G_synthesis/ToRGB_lod4 1539 (?, 3, 8, 8) (1, 1, 512, 3)
G_synthesis/Upscale2D - (?, 3, 8, 8) -
G_synthesis/Grow_lod4 - (?, 3, 8, 8) -
G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512)
G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512)
G_synthesis/ToRGB_lod3 1539 (?, 3, 16, 16) (1, 1, 512, 3)
G_synthesis/Upscale2D_1 - (?, 3, 16, 16) -
G_synthesis/Grow_lod3 - (?, 3, 16, 16) -
G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512)
G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512)
G_synthesis/ToRGB_lod2 1539 (?, 3, 32, 32) (1, 1, 512, 3)
G_synthesis/Upscale2D_2 - (?, 3, 32, 32) -
G_synthesis/Grow_lod2 - (?, 3, 32, 32) -
G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256)
G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256)
G_synthesis/ToRGB_lod1 771 (?, 3, 64, 64) (1, 1, 256, 3)
G_synthesis/Upscale2D_3 - (?, 3, 64, 64) -
G_synthesis/Grow_lod1 - (?, 3, 64, 64) -
G_synthesis/128x128/Conv0_up 426496 (?, 128, 128, 128) (3, 3, 256, 128)
G_synthesis/128x128/Conv1 279040 (?, 128, 128, 128) (3, 3, 128, 128)
G_synthesis/ToRGB_lod0 387 (?, 3, 128, 128) (1, 1, 128, 3)
G_synthesis/Upscale2D_4 - (?, 3, 128, 128) -
G_synthesis/Grow_lod0 - (?, 3, 128, 128) -
G_synthesis/images_out - (?, 3, 128, 128) -
G_synthesis/lod - () -
G_synthesis/noise0 - (1, 1, 4, 4) -
G_synthesis/noise1 - (1, 1, 4, 4) -
G_synthesis/noise2 - (1, 1, 8, 8) -
G_synthesis/noise3 - (1, 1, 8, 8) -
G_synthesis/noise4 - (1, 1, 16, 16) -
G_synthesis/noise5 - (1, 1, 16, 16) -
G_synthesis/noise6 - (1, 1, 32, 32) -
G_synthesis/noise7 - (1, 1, 32, 32) -
G_synthesis/noise8 - (1, 1, 64, 64) -
G_synthesis/noise9 - (1, 1, 64, 64) -
G_synthesis/noise10 - (1, 1, 128, 128) -
G_synthesis/noise11 - (1, 1, 128, 128) -
images_out - (?, 3, 128, 128) -
--- --- --- ---
Total 25843858
D Params OutputShape WeightShape
--- --- --- ---
images_in - (?, 3, 128, 128) -
labels_in - (?, 0) -
lod - () -
FromRGB_lod0 512 (?, 128, 128, 128) (1, 1, 3, 128)
128x128/Conv0 147584 (?, 128, 128, 128) (3, 3, 128, 128)
128x128/Conv1_down 295168 (?, 256, 64, 64) (3, 3, 128, 256)
Downscale2D - (?, 3, 64, 64) -
FromRGB_lod1 1024 (?, 256, 64, 64) (1, 1, 3, 256)
Grow_lod0 - (?, 256, 64, 64) -
64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256)
64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512)
Downscale2D_1 - (?, 3, 32, 32) -
FromRGB_lod2 2048 (?, 512, 32, 32) (1, 1, 3, 512)
Grow_lod1 - (?, 512, 32, 32) -
32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512)
32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512)
Downscale2D_2 - (?, 3, 16, 16) -
FromRGB_lod3 2048 (?, 512, 16, 16) (1, 1, 3, 512)
Grow_lod2 - (?, 512, 16, 16) -
16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512)
16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512)
Downscale2D_3 - (?, 3, 8, 8) -
FromRGB_lod4 2048 (?, 512, 8, 8) (1, 1, 3, 512)
Grow_lod3 - (?, 512, 8, 8) -
8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512)
8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512)
Downscale2D_4 - (?, 3, 4, 4) -
FromRGB_lod5 2048 (?, 512, 4, 4) (1, 1, 3, 512)
Grow_lod4 - (?, 512, 4, 4) -
4x4/MinibatchStddev - (?, 513, 4, 4) -
4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512)
4x4/Dense0 4194816 (?, 512) (8192, 512)
4x4/Dense1 513 (?, 1) (512, 1)
scores_out - (?, 1) -
--- --- --- ---
Total 22941313
Building TensorFlow graph...
WARNING:tensorflow:From C:\Users\user\stylegan-master\training\training_loop.py:167: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Deprecated in favor of operator or tf.math.divide.
WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
Setting up snapshot image grid...
2020-01-20 07:05:17.296825: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:17.320746: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:17.342289: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.15GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:17.350675: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:17.399302: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.10GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
Setting up run dir...
Training...
2020-01-20 07:05:35.259782: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:35.316821: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:35.386177: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:35.430917: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-01-20 07:05:35.476293: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
tick 1 kimg 140.0 lod 4.00 minibatch 64 time 8m 55s sec/tick 483.6 sec/kimg 3.45 maintenance 51.7 gpumem 1.6
network-snapshot-000140 time 8m 46s fid50k 360.7307
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
tick 2 kimg 280.1 lod 4.00 minibatch 64 time 25m 58s sec/tick 479.1 sec/kimg 3.42 maintenance 543.3 gpumem 2.0
tick 3 kimg 420.1 lod 4.00 minibatch 64 time 33m 59s sec/tick 479.0 sec/kimg 3.42 maintenance 2.3 gpumem 2.0
tick 4 kimg 560.1 lod 4.00 minibatch 64 time 42m 01s sec/tick 479.8 sec/kimg 3.43 maintenance 2.2 gpumem 2.0
tick 5 kimg 680.2 lod 3.87 minibatch 32 time 59m 14s sec/tick 1030.6 sec/kimg 8.58 maintenance 2.2 gpumem 2.0
tick 6 kimg 800.3 lod 3.67 minibatch 32 time 1h 21m 24s sec/tick 1327.7 sec/kimg 11.06 maintenance 2.2 gpumem 2.0
tick 7 kimg 920.3 lod 3.47 minibatch 32 time 1h 43m 29s sec/tick 1323.3 sec/kimg 11.02 maintenance 2.2 gpumem 2.0
tick 8 kimg 1040.4 lod 3.27 minibatch 32 time 2h 05m 23s sec/tick 1311.2 sec/kimg 10.92 maintenance 2.2 gpumem 2.0
tick 9 kimg 1160.4 lod 3.07 minibatch 32 time 2h 27m 16s sec/tick 1311.7 sec/kimg 10.92 maintenance 2.2 gpumem 2.0
tick 10 kimg 1280.5 lod 3.00 minibatch 32 time 2h 48m 55s sec/tick 1296.9 sec/kimg 10.80 maintenance 2.2 gpumem 2.0
network-snapshot-001280 time 9m 16s fid50k 292.2210
tick 11 kimg 1400.6 lod 3.00 minibatch 32 time 3h 19m 47s sec/tick 1291.2 sec/kimg 10.75 maintenance 560.0 gpumem 2.0
tick 12 kimg 1520.6 lod 3.00 minibatch 32 time 3h 41m 20s sec/tick 1291.5 sec/kimg 10.76 maintenance 2.2 gpumem 2.0
tick 13 kimg 1640.7 lod 3.00 minibatch 32 time 4h 02m 53s sec/tick 1290.3 sec/kimg 10.75 maintenance 2.3 gpumem 2.0
tick 14 kimg 1760.8 lod 3.00 minibatch 32 time 4h 24m 26s sec/tick 1290.8 sec/kimg 10.75 maintenance 2.2 gpumem 2.0
tick 15 kimg 1860.8 lod 2.90 minibatch 16 time 5h 08m 55s sec/tick 2667.1 sec/kimg 26.66 maintenance 2.2 gpumem 2.0
tick 16 kimg 1960.8 lod 2.73 minibatch 16 time 6h 10m 02s sec/tick 3663.8 sec/kimg 36.63 maintenance 3.3 gpumem 2.0
tick 17 kimg 2060.9 lod 2.57 minibatch 16 time 7h 11m 09s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0
tick 18 kimg 2160.9 lod 2.40 minibatch 16 time 8h 12m 15s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0
tick 19 kimg 2260.9 lod 2.23 minibatch 16 time 9h 13m 22s sec/tick 3663.0 sec/kimg 36.62 maintenance 3.3 gpumem 2.0
tick 20 kimg 2361.0 lod 2.07 minibatch 16 time 10h 14m 28s sec/tick 3662.6 sec/kimg 36.61 maintenance 3.3 gpumem 2.0
network-snapshot-002360 time 11m 20s fid50k 329.8881
tick 21 kimg 2461.0 lod 2.00 minibatch 16 time 11h 26m 28s sec/tick 3635.4 sec/kimg 36.34 maintenance 685.2 gpumem 2.0
tick 22 kimg 2561.0 lod 2.00 minibatch 16 time 12h 27m 40s sec/tick 3668.3 sec/kimg 36.67 maintenance 3.3 gpumem 2.0
tick 23 kimg 2661.1 lod 2.00 minibatch 16 time 13h 28m 13s sec/tick 3630.0 sec/kimg 36.29 maintenance 3.4 gpumem 2.0
tick 24 kimg 2761.1 lod 2.00 minibatch 16 time 14h 29m 10s sec/tick 3652.9 sec/kimg 36.52 maintenance 3.4 gpumem 2.0
tick 25 kimg 2861.1 lod 2.00 minibatch 16 time 15h 29m 52s sec/tick 3639.3 sec/kimg 36.38 maintenance 3.3 gpumem 2.0
tick 26 kimg 2961.2 lod 2.00 minibatch 16 time 16h 30m 13s sec/tick 3617.6 sec/kimg 36.16 maintenance 3.3 gpumem 2.0
tick 27 kimg 3041.2 lod 1.93 minibatch 8 time 18h 07m 10s sec/tick 5814.1 sec/kimg 72.68 maintenance 3.3 gpumem 2.0
tick 28 kimg 3121.2 lod 1.80 minibatch 8 time 20h 29m 23s sec/tick 8525.3 sec/kimg 106.57 maintenance 7.0 gpumem 2.0
tick 29 kimg 3201.2 lod 1.66 minibatch 8 time 22h 51m 39s sec/tick 8528.9 sec/kimg 106.61 maintenance 7.2 gpumem 2.0
tick 30 kimg 3281.2 lod 1.53 minibatch 8 time 1d 01h 14m sec/tick 8536.7 sec/kimg 106.71 maintenance 7.3 gpumem 2.0
network-snapshot-003281 time 14m 53s fid50k 321.2979
tick 31 kimg 3361.2 lod 1.40 minibatch 8 time 1d 03h 51m sec/tick 8535.0 sec/kimg 106.69 maintenance 902.6 gpumem 2.0
tick 32 kimg 3441.2 lod 1.26 minibatch 8 time 1d 06h 13m sec/tick 8542.2 sec/kimg 106.78 maintenance 7.4 gpumem 2.0
tick 33 kimg 3521.2 lod 1.13 minibatch 8 time 1d 08h 36m sec/tick 8540.9 sec/kimg 106.76 maintenance 7.6 gpumem 2.0
tick 34 kimg 3601.2 lod 1.00 minibatch 8 time 1d 10h 58m sec/tick 8538.5 sec/kimg 106.73 maintenance 7.5 gpumem 2.0
tick 35 kimg 3681.2 lod 1.00 minibatch 8 time 1d 13h 19m sec/tick 8427.5 sec/kimg 105.34 maintenance 7.5 gpumem 2.0
...