 第十七夜は、昨夜の結果がどうにもおかしいので、ディープなNetworkモデルをやり直して、将棋AIのどれが強いか総当たり戦を再度やってみた。
### やったこと
(1)ResnetのディープなNetworkモデルで学習した
(2)昨夜の上位のNetworkモデルで総当たり戦を実施した
### (1)ResnetのディープなNetworkモデルで学習した
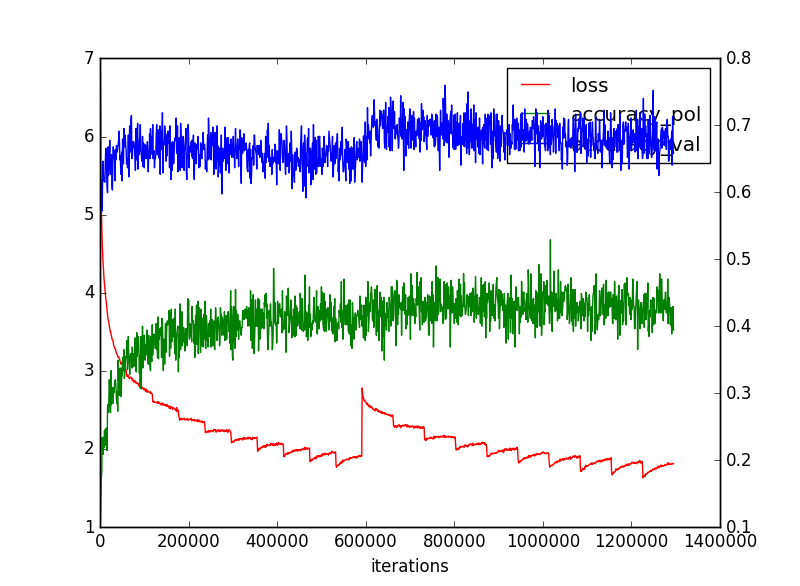
モデルは以下のとおりのBlocks=20すなわち全部で3層+40層の43層と今までと比べるととても深いものをやってみました。
第十七夜は、昨夜の結果がどうにもおかしいので、ディープなNetworkモデルをやり直して、将棋AIのどれが強いか総当たり戦を再度やってみた。
### やったこと
(1)ResnetのディープなNetworkモデルで学習した
(2)昨夜の上位のNetworkモデルで総当たり戦を実施した
### (1)ResnetのディープなNetworkモデルで学習した
モデルは以下のとおりのBlocks=20すなわち全部で3層+40層の43層と今までと比べるととても深いものをやってみました。
dlShogi-kai/Network/ResnetSimple/policy_value_resnetSimple.py
主要な部分は以下のとおり(ほとんどだけど)
class Block(Chain):
def __init__(self):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.conv2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
def __call__(self, x):
h1 = F.relu(self.conv1(x))
h2 = self.conv2(h1)
return F.relu(x+h2) #x+h2
class PolicyValueResnet(Chain):
def __init__(self, blocks = 20):
super(PolicyValueResnet, self).__init__()
self.blocks = blocks
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
self.l2=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
for i in range(1, 20):
self.add_link('b{}'.format(i), Block())
# policy network
self.policy=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.policy_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.value1=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.value2=L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.value3=L.Linear(fcl, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
h = F.relu(self.l2(h))
for i in range(1, 20):
h = self['b{}'.format(i)](h)
# policy network
h_policy = self.policy(h)
u_policy = self.policy_bias(F.reshape(h_policy, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h_value = F.relu(self.value1(h))
h_value = F.relu(self.value2(h_value))
u_value = self.value3(h_value)
return u_policy, u_value
ポイントは以下のとおり
1.for i in range(1, 20):およびfor i in range(1, 20):と追加するNetworkの数を明示した
2.ResnetはBatchNormalizationしているが、外してみた
※これはなんとなく将棋の場合は変な規格化は悪い影響がありそうな気がしたため
3.Layer13のモデルを作成できるように入力に次ぐ二層目のNetworkを追加した
※これでblocks=5として、Block()のreturn F.relu(h2)とするとLayer13と同じ構造になるが、今回はreturn F.relu(x+h2)としている
このNetworkモデルで以下のような結果を得た。Lossは今一つだが、一致率は抜群な結果となった。
| 名称 | loss | 一致率(方策) | 一致率(価値) | 備考 |
|---|---|---|---|---|
| policy | 1.682677 | 0.4226734 | - | 方策ネットワークのみ |
| Policy_Value;Layer13 | 2.016 | 0.4204578 | 0.67033803 | 13層の方策・価値ネットワークでMCTS |
| Policy_Value;Layer23 | 2.1938 | 0.41157416 | 0.6601796 | 23層のMCTS |
| ResnetSimple40 | 2.5091131 | 0.42899686 | 0.6974323 | Resnet20block43層 |
| ResnetSimple40 | 1.756215 | 0.43086118 | 0.6800308 | Loss最小対戦は上記 |
 |
(2)昨夜の上位のNetworkモデルで総当たり戦を実施した
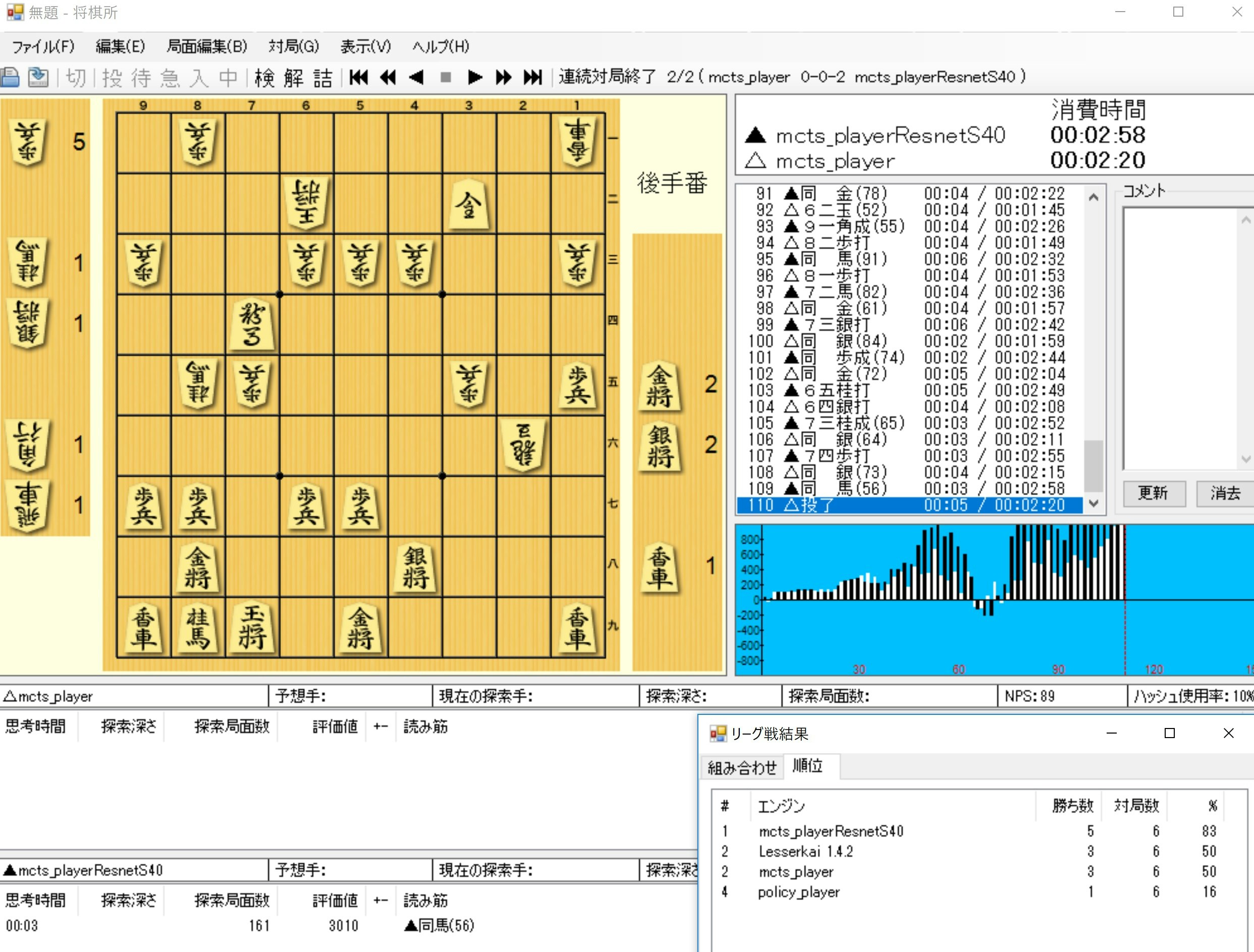

| ---------- | R43 | L13 | LKai | policy | Win | Draw | Loss | Pt |
|---|---|---|---|---|---|---|---|---|
| R43 | - | 2 | 1 | 2 | 5 | 0 | 1 | 5 |
| L13 | 0 | - | 2 | 1 | 3 | 0 | 3 | 3 |
| LKai | 1 | 0 | - | 2 | 3 | 0 | 3 | 3 |
| policy | 0 | 1 | 0 | - | 1 | 0 | 5 | 1 |
まとめ
・43層というディープなモデルで今までで一番強い将棋AIが作成できた
・バグが回避できたのでバリエーションを追求してさらに強い将棋AIを作成したい