表題のとおりです。
今回は以下の参考のとおりに自前学習したまゆゆとアニメ顔が微笑んでくれるかやってみました。
【参考】
StyleGanで福沢諭吉を混ぜてみる
結論からいうと以下のような笑顔画像が得られ成功しました♬
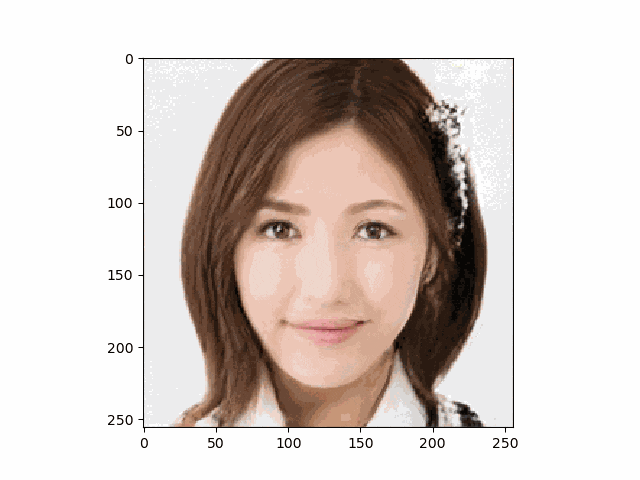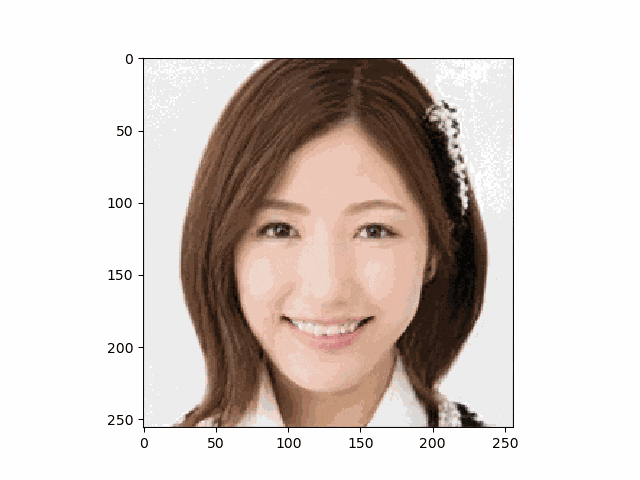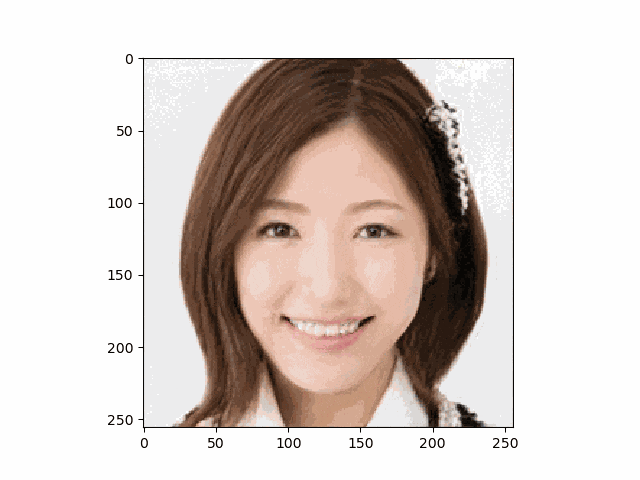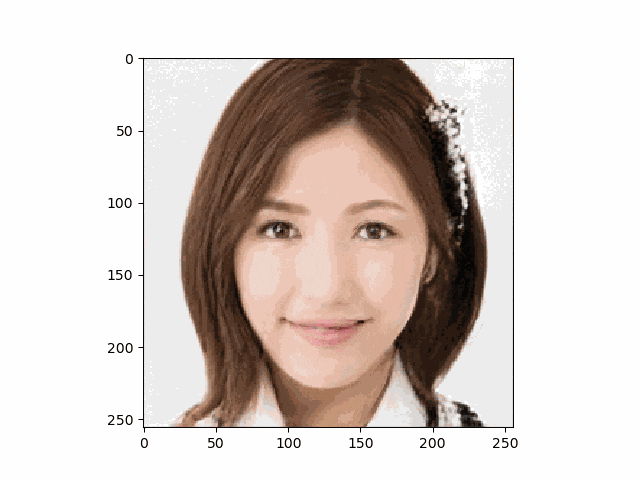
癒されますね♬
やったこと
・自前の画像を学習する
・笑顔画像を生成し、動画を作成する
・アニメ顔画像もやってみる
・自前の画像を学習する
まゆゆは、前回と同じというか前回のnpyデータを利用しました。
一方、アニメ顔画像は同じようにalignしようとしましたが、顔の作りが違いすぎてalignできませんでした。
しかし、アニメ顔画像についても同様に学習しました。
その結果、学習は出来たようで、以下の画像が出力できるnpyが取得できました。
| 1 | 2 |
|---|---|
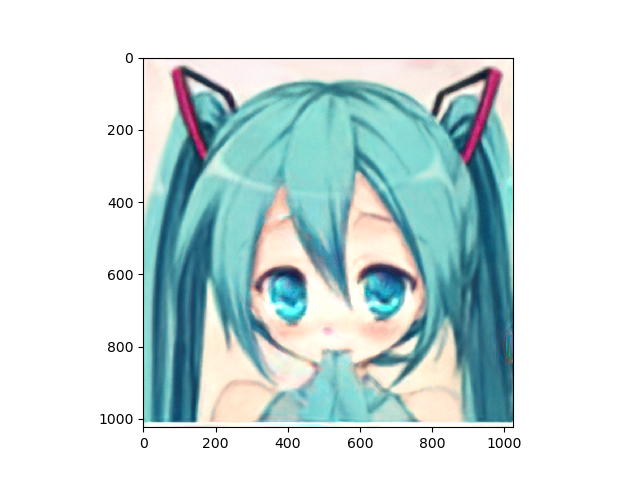 |
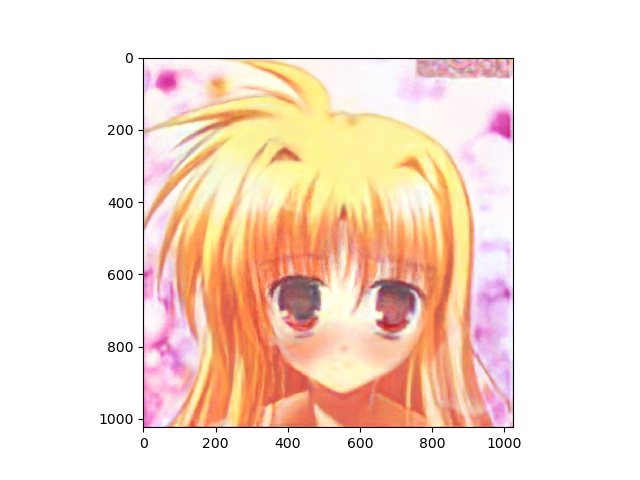 |
| 当然のように、これらの画像を利用してMixingもやってみました。 | |
| しかし、。。。結果は以下のとおり、 |
| Mixing in projected latent space |  |
|---|---|
 |
 |
| どうも写像潜在空間は人間どもに汚されてしまっているようです | |
| この傾向は、人の顔とMixingしても同様な感じです。 | |
| その絵は今回は貼らずに置きます。 |
・笑顔画像を生成し、動画を作成する
原理は、簡単に書くと以下のとおりです。
latent_vector = np.load('./latent/mayuyu.npy')
coeff = [-1,-0.8,-0.6,-0.4,-0.2, 0,0.2,0.4,0.6,0.8, 1]
direction = np.load('ffhq_dataset/latent_directions/smile.npy')
new_latent_vector[:8] = (latent_vector + coeff*direction)[:8]
smile_image = generate_image(new_latent_vector)
この新しいnew_latent_vectorで、smile画像生成します。
ということで、以下のようなコードになります。
コードは以下に置きました。
StyleGAN/mayuyu_smile.py
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
import sys
from PIL import Image, ImageDraw
from encoder.generator_model import Generator
import matplotlib.pyplot as plt
tflib.init_tf()
fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl'
with open(fpath, mode='rb') as f:
generator_network, discriminator_network, Gs_network = pickle.load(f)
generator = Generator(Gs_network, batch_size=1, randomize_noise=False)
def generate_image(latent_vector):
latent_vector = latent_vector.reshape((1, 18, 512))
generator.set_dlatents(latent_vector)
img_array = generator.generate_images()[0]
img = PIL.Image.fromarray(img_array, 'RGB')
return img.resize((256, 256))
def move_and_show(latent_vector, direction, coeffs):
for i, coeff in enumerate(coeffs):
new_latent_vector = latent_vector.copy()
new_latent_vector[:8] = (latent_vector + coeff*direction)[:8]
plt.imshow(generate_image(new_latent_vector))
plt.pause(1)
plt.savefig("./results/example{}.png".format(i))
plt.close()
mayuyu = np.load('./latent/mayuyu.npy')
smile_direction = np.load('ffhq_dataset/latent_directions/smile.npy')
move_and_show(mayuyu, smile_direction, [-1,-0.8,-0.6,-0.4,-0.2, 0,0.2,0.4,0.6,0.8, 1])
s=22
images = []
for i in range(0,11,1):
im = Image.open(config.result_dir+'/example'+str(i)+'.png')
im =im.resize(size=(640,480), resample=Image.NEAREST)
images.append(im)
for i in range(10,0,-1):
im = Image.open(config.result_dir+'/example'+str(i)+'.png')
im =im.resize(size=(640, 480), resample=Image.NEAREST)
images.append(im)
images[0].save(config.result_dir+'/mayuyu_smile{}.gif'.format(11), save_all=True, append_images=images[1:s], duration=100*2, loop=0)
こうして、トランプさんも笑顔です。
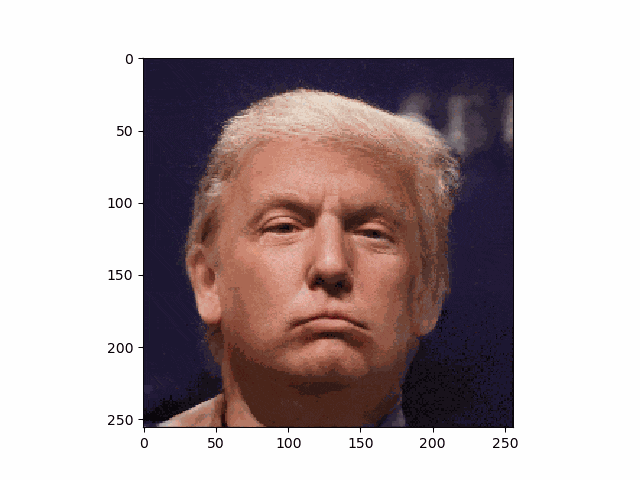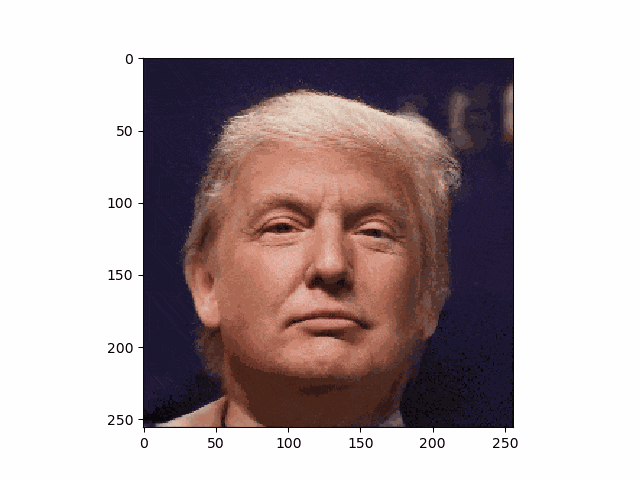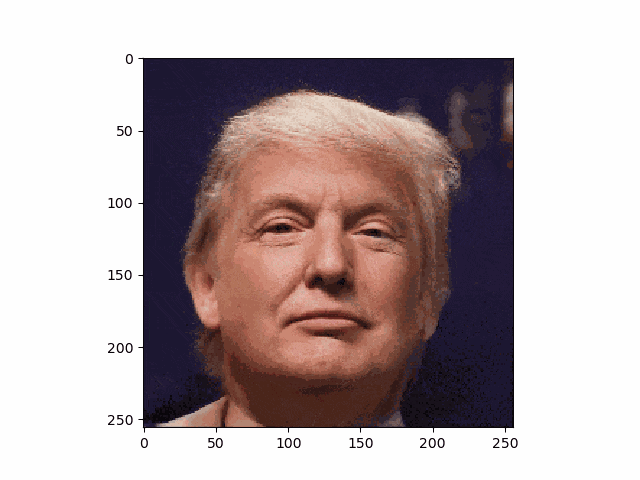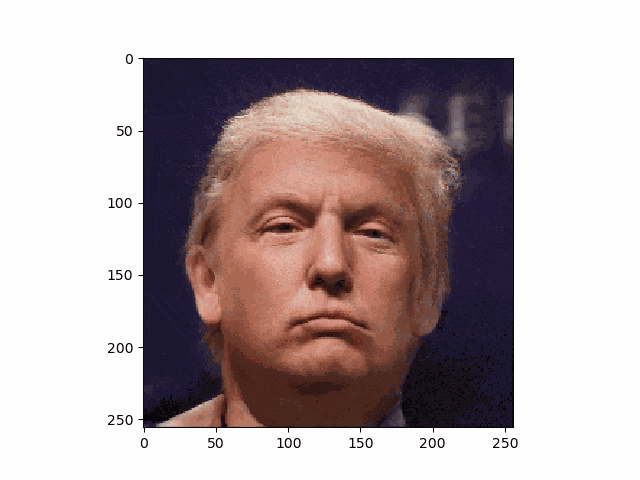
・アニメ顔画像もやってみる
上記のとおり、アニメ顔画像はnpyは生成出来たのでこれを使って、笑顔に挑戦です。
結果は以下のとおり、まあ笑ってる。。。かな
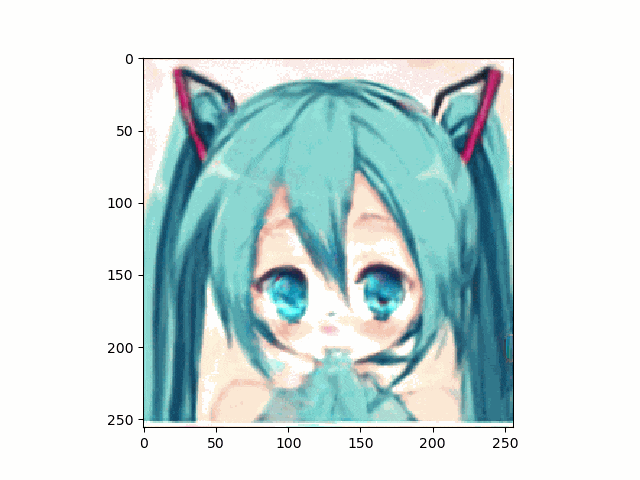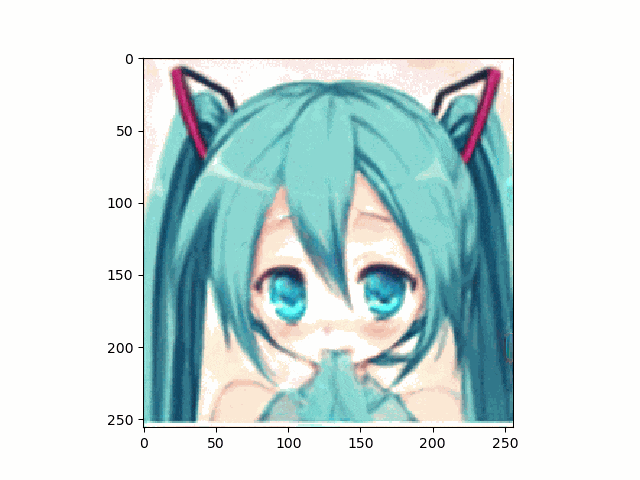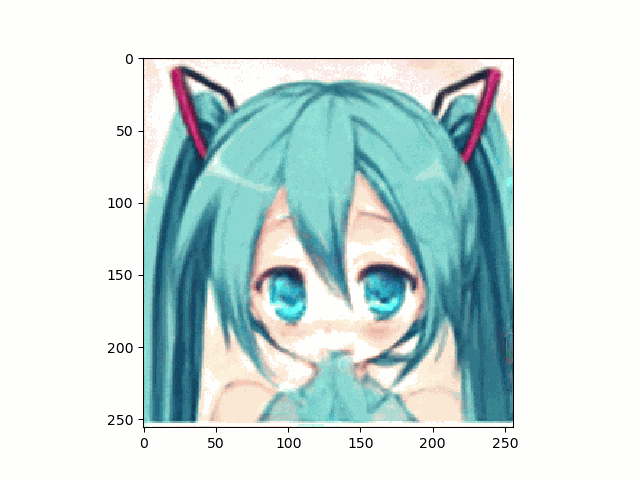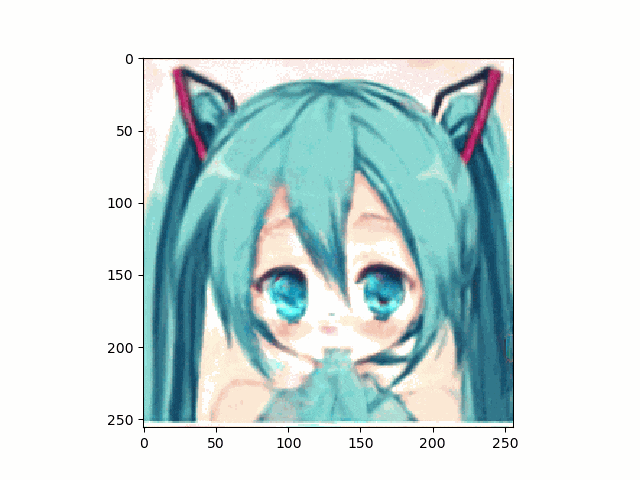
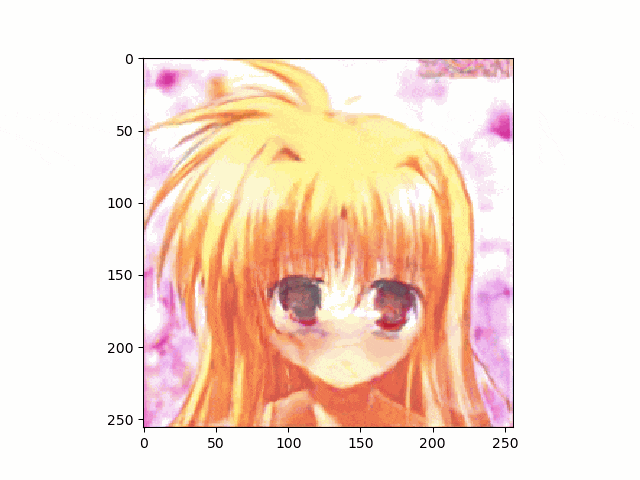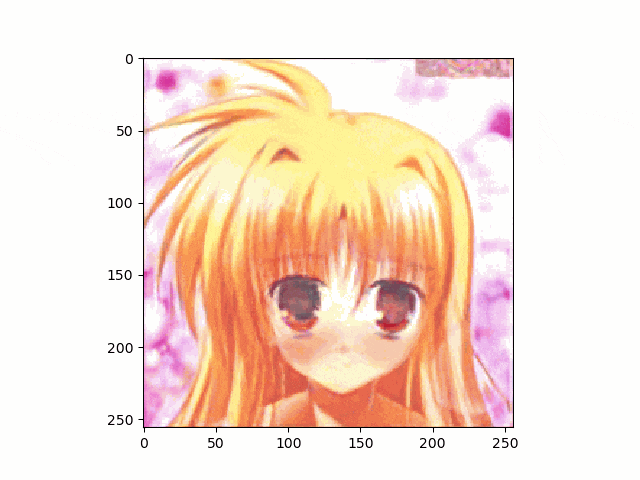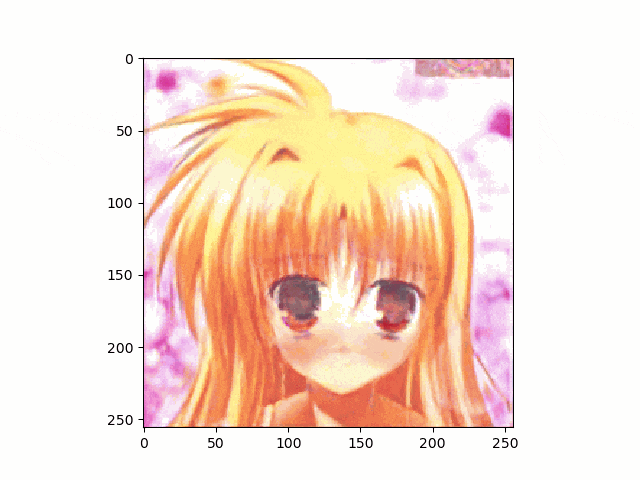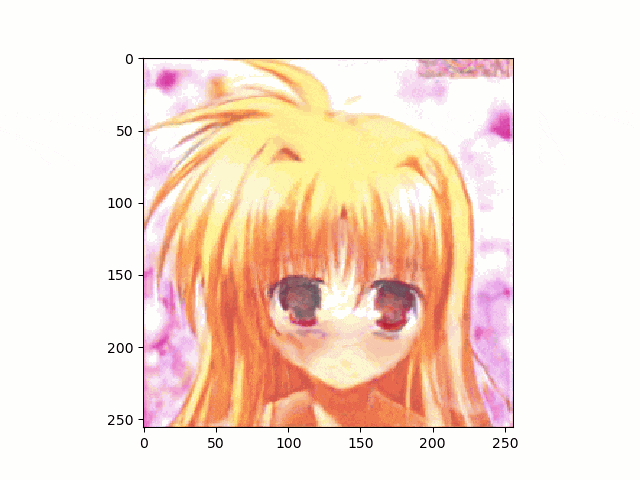
。。。しかし、問題は口が、。。。らしいものしかないってことですね
まとめ
・アニメ画像の学習をやってみた
・自前学習の「まゆゆもアニメも微笑んだ」に挑戦してみた
・だいたい出来たが、もう少し口のあるアニメ画像でやってみようと思う
・アニメ画像のいわゆるTrainingをやってみよう
・そもそもsmile.npyと同じように動作用のnpyを作成したい