第三夜は、第二夜に引き続き自前ゲームを登録して学習する。
今回は、以前遊んだ以下の参考のゲームをやってみた。
【参考】
・【dqn】自由な運動を深層強化学習する♬
やったこと
(1)自由な運動をゲーム環境に登録する
(2)ゲームの解説と学習
(1)自由な運動をゲーム環境に登録する
まずは昨夜と同じようにゲーム環境に登録する。
myenv2/__init__.py
from gym.envs.registration import register
register(
id='myenv2-v0',
entry_point='myenv2.env:PointOnLine'
)
(2)ゲームの解説と学習
そして、ゲームは以下のとおり
myenv2/dqn_PoL.py
import sys
import gym
import gym.spaces
import numpy as np
# 直線上を動く点の速度を操作し、目標(原点)に移動させることを目標とする環境
class PointOnLine(gym.Env):
def __init__(self):
self.action_space = gym.spaces.Discrete(3) # 行動空間。速度を下げる、そのまま、上げるの3種
high = np.array([1.0, 1.0]) # 観測空間(state)の次元 (位置と速度の2次元) とそれらの最大値
self.observation_space = gym.spaces.Box(low=-high, high=high) # 最小値は、最大値のマイナスがけ
# 各stepごとに呼ばれる
# actionを受け取り、次のstateとreward、episodeが終了したかどうかを返すように実装
def step(self, action):
# actionを受け取り、次のstateを決定
dt = 0.1
acc = (action - 1) * 0.1
self._vel += acc * dt
self._vel = max(-1.0, min(self._vel, 1.0))
self._pos += self._vel * dt
self._pos = max(-1.0, min(self._pos, 1.0))
# 位置と速度の絶対値が十分小さくなったらepisode終了
done = abs(self._pos) < 0.1 and abs(self._vel) < 0.1
if done:
# 終了したときに正の報酬
reward = 1.0
else:
# 時間経過ごとに負の報酬
# ゴールに近づくように、距離が近くなるほど絶対値を減らしておくと、学習が早く進む
reward = -0.01 * abs(self._pos)
# 次のstate、reward、終了したかどうか、追加情報の順に返す
# 追加情報は特にないので空dict
return np.array([self._pos, self._vel]), reward, done, {}
# 各episodeの開始時に呼ばれ、初期stateを返すように実装
def reset(self):
# 初期stateは、位置はランダム、速度ゼロ
self._pos = np.random.rand()*2 - 1
self._vel = 0.0
return np.array([self._pos, self._vel])
"""
def close(self):
pass
def seed(self, seed=None):
pass
"""
と前夜のコメントと同じように_step(self, action):とかで上書きして動いていましたが、stepでも動いたので変更しました。
ところで、closeとseedはpassいれましたが、これは_stepと記載していたときは無いと怒られましたが、stepと改めたので必要なくなりました。
また、renderも入れたかったのですが、とりあえずもともとのコードの通りで描画は本体側に残しました。
この本体は描画のためのcallbacks以外は、CartPoleのコードとほとんど同じです。
※policy = EpsGreedyQPolicy(eps=0.1) だけ異なりますが、。。。
dqn_PoL.py
import myenv2 # これを読み込んでおく
import numpy as np
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
# env = PointOnLine()
ENV_NAME = 'myenv2-v0' # register で使った ID
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.n
# DQNのネットワーク定義
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
# experience replay用のmemory
memory = SequentialMemory(limit=50000, window_length=1)
# 行動方策はオーソドックスなepsilon-greedy。ほかに、各行動のQ値によって確率を決定するBoltzmannQPolicyが利用可能
policy = EpsGreedyQPolicy(eps=0.1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=100,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
nb_steps=10000
history = dqn.fit(env, nb_steps=nb_steps, visualize=False, verbose=2, nb_max_episode_steps=300)
# 学習の様子を描画したいときは、Envに_render()を実装して、visualize=True にします,
以下描画のためのcallbacksのコード
import rl.callbacks
class EpisodeLogger(rl.callbacks.Callback):
def __init__(self):
self.observations = {}
self.rewards = {}
self.actions = {}
def on_episode_begin(self, episode, logs):
self.observations[episode] = []
self.rewards[episode] = []
self.actions[episode] = []
def on_step_end(self, step, logs):
episode = logs['episode']
self.observations[episode].append(logs['observation'])
self.rewards[episode].append(logs['reward'])
self.actions[episode].append(logs['action'])
cb_ep = EpisodeLogger()
dqn.test(env, nb_episodes=10, visualize=False, callbacks=[cb_ep])
import matplotlib.pyplot as plt
for obs in cb_ep.observations.values():
plt.plot([o[0] for o in obs])
plt.xlabel("step")
plt.ylabel("pos")
plt.pause(3)
plt.savefig('plot_epoch_{0:03d}_dqn.png'.format(nb_steps), dpi=60)
plt.close()
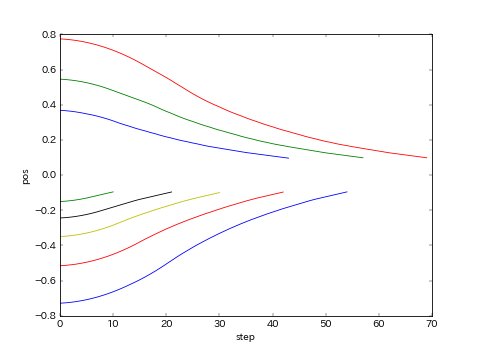
ということで、めでたくゲームを環境に登録して、無事に学習・テストすることが出来ました。
ちなみに、policy = BoltzmannQPolicy()だと収束しませんでした。
まとめ
・自由な運動のゲームを環境に登録して学習できた
・さーて、オリジナルなゲーム出来るかな