前回記事でAutoencoder利用して、簡単な色付けをやってみた。
今回は、深堀してさらに綺麗な色付けを出来るか遊んでみたので、まとめておく。
アイディアのほとんどは、以下の参考①、そして理論的な話は参考②を参考としています。
【参考】
①Image Colorization with Convolutional Neural Networks
②色空間の変換(4) YCbCr/YPbPr 色空間
結果は、cifar10に対して、以下のような絵が得られました。
| 1 |
|---|
出力画像(生成後規格化)
|
入力画像
|
規格化元画像
|
元画像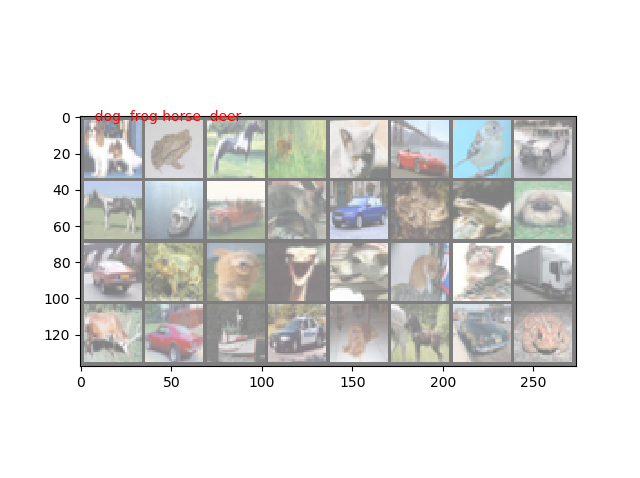
|
やったこと
・色空間ってなんだ
・変換関数を試してみる
・pytoachでやってみる
・色空間ってなんだ
これについては、参考②でも書いておりますが、実際の画像は参考③を見るとある程度想像つくと思います。参考②③では、いろいろな色空間に変換して、それぞれのチャンネルの頻度を見て、明るさ調整をしています。
【参考】
③【画像処理】暗視カメラ出来たかも♬
④【画像処理】静止画・カメラ動画の輝度ヒストグラム調整と明度自動調整をやってみる♬
今回は、これをグレー画像とそれ以外の色付け要素に分解して、グレー画像をもとに色付け要素だけを学習して、元のグレー画像に重畳する。このようにして、カラー画像を復元しようというものです。絵に描くと、以下の通りです。
(参考①から引用)

参考①では、色空間としてCIELABを利用しています。
しかし、同じものを利用するのも発展性が無いということで、参考②を頼りに別の色空間を利用することとしました。
色空間は、元々rgbであれば3チャンネルで、色の表現方法はそのほかにも以下の参考のようにいろいろ提案・利用されています。この多様性は、見え方や表現方法の違いから多くの派生が生まれているようです。
【参考】
⑤色空間
⑥Lab色空間
⑦YUV
そして、参考⑥によれば、今回色付けで参考にした上図の根拠は、以下のようです。
「Lab色空間は人間の視覚を近似するよう設計されている。知覚的均等性を重視しており、L成分値は人間の明度の知覚と極めて近い。したがって、カラーバランス調整を正確に行うために出力曲線を a および b の成分で表現したり、コントラストの調整のためにL成分を使ったりといった利用が可能である」
ということで、LとABを分離し、上記のような学習から色塗りを実施しています。
参考①では、以下のように記載しています。
「This colorspace contains exactly the same information as RGB, but it will make it easier for us to separate out the lightness channel from the other two (which we call A and B). 」
一方で、参考②のような話もあります。つまり、
「テレビ・ビデオや画像のJPEG圧縮に使われる色空間に YCbCr がある。このうち,Y は輝度信号,Cb と Cr は色差信号を表す。YCbCr は,色空間というよりも信号の伝送・記録方式というほうがいいかもしれない。YCbCr と似たものに YPbPr がある。これらの違いについては,
1.YPbPr はアナログ信号を表し,YCbCr はデジタルデータを表す [海外での解釈?]
2.YCbCr は標準テレビ (SDTV) の信号を表し,YPbPr はハイビジョン (HDTV) の信号を表す [日本での解釈?]
という解釈があって混乱しているが,ここでは 1. の解釈 (YPbPr はアナログ,YCbCr はデジタル) に従うことにする。」
参考⑦より、いづれにしても以下の通りで、テレビなどでは以下の方式ということです。
「YUVやYCbCrやYPbPrとは、輝度信号Yと、2つの色差信号を使って表現される色空間。」
ということで、今回は、YCbCrを採用することとしました。
現存の白黒画像は、本来白黒映像か白黒写真由来のものだろうと想像し、その場合はこのYCbCrで表現できると考えました。
※以下で見るように基本的にはLABでもYCbCrもどちらも関数一個でrgbから変換できるので、対象によって学習を変えればいいし、そもそもLとYを比較するとあまり主張するほどの違いはないようです。
・変換関数を試してみる
ここでは、opencvの以下の変換関数を利用しました。
RGB画像のYCbCrとLABへの変換関数と逆関数は以下のとおりです。
なお、試した結果が膨大になってしまったことと、気づきが別途あったので近日中に別記事とします。
| 関数 | 適用 |
|---|---|
| cv2.cvtColor(image0, cv2.COLOR_BGR2RGB) | jpgやpngの画像データをRGB形式に変換※PILのImage.open()で読み込むと変換できない |
| cv2.cvtColor(image1, cv2.COLOR_BGR2YCR_CB) | jpgやpngの画像データをYCrCb形式に変換 |
| Y, Cr, Cb = cv2.split(orgYCrCb) | YCrCb形式の画像を要素Y,Cr,Cbに分離 |
| YCC = cv2.merge((Y,Cr,Cb)) | 要素Y,Cr,Cbを合成する |
| cv2.cvtColor(YCC, cv2.COLOR_YCR_CB2BGR) | YCrCb形式の画像YCCをBGR形式に変換 |
| cv2.cvtColor(image1, cv2.COLOR_BGR2LAB) | jpgやpngの画像データをLAB形式に変換 |
| L, A, B = cv2.split(orgLAB) | LAB形式の画像を要素L,A,Bに分離 |
| LAB = cv2.merge((L,A,B)) | 要素L,A,Bを合成する |
| cv2.cvtColor(LAB, cv2.COLOR_LAB2BGR) | LAB形式の画像LABをBGR形式に変換 |
また、pytorchのtorchvision.transformsの変換関数、および親和性の高いPILの以下の関数を利用します。pytorchの変換は、torch-tensorまたは、PIL形式のファイルを変換します。
| 1 | 2 |
|---|---|
| ts = transforms.ToPILImage() | PIL形式に変換 |
| ts2 = transforms.ToTensor() | torch.tensorに変換 |
| ts3 = transforms.Grayscale() | grayscaleに変換 |
| ts3 = transforms.Normalize(mean,std) | 平均meanと標準偏差stdに規格化する |
| image_=ts(image0).convert('L') | grayscaleに変換 |
| image_g=ts3(ts(image0)) | PIL形式に変換した後、graysclaleに変換 |
| Y_ = ts(Y).convert('RGB') | 1chデータYをPIL形式に変換した後、RGB形式に変換 |
・pytoachでやってみる
参考①のnetworkとvgg16を組み合わせた以下のおまけのnetworkで学習してみました。
ほぼ、前回の参考⑧と同様ですが、以下の変更を実施しています。
※始める前の見通しでは非常に簡単なお話だと思っていましたが、かなり突っ込んでしまったので、あっさり記載します
①Y,CrCbで学習する
②Networkを変更する
【参考】
⑧【pytorch-lightning入門】自前datasetで~Denoising, Coloring, Normalization, そして拡大カラー画像生成で遊んでみた♬
Dataloaderの準備①Y,CrCbで学習するためにデータ準備
まず、dataset及びDataloaderは以下のとおりとしました。
今回も、既存のCifar10のデータを利用します。
ここで画像処理をどの段階でやるのが効率的か悩みましたが、最終的に以下の通りとしました。
※現時点では、さらにいろいろ遊んでみると精度が上がるし、以下の記述も変更すべきとなる可能性があると思っています
1.BGRからYCrCb空間に変換する
2.YとCrCb成分を別々に提供する
3.当初、同一関数でreturn Y, CCのように渡していましたが、挙動が怪しいので別関数としました
4.どこまでの処理をデータ読込とこの関数で実施するのかを悩みましたが、二つの関数で共通な画像サイズ拡大と規格化は最初のデータ読込時に実施することとしました。つまりこの関数ではその後の処理のみをすることとしました(なので、一部無駄コードを残しています)
5.画像の値域制御のための処理(img = img / 2 + 0.5;unnormalize処理)は、画像が綺麗に見える値(ここでは1/4;通常plt.imshowの描画範囲から1/2だが規格化すると超える場合がある)を採用しています
6.Yについては、当初元画像からgray変換実施してgray画像を返していたが、後ほど合成するので同時処理して、gray変換するように変更した。たぶん、こちらが正解だろうと思う。なお、元画像が同一ならばgrayとYそして、L(参考①のCIELAB空間のL)は、(見栄えの確認だが)同一だということを確認した
Datasetのコードに提供するためのrgb2YCrCb変換のコード
class rgb2YCrCb(object):
def __init__(self):
self.ts = torchvision.transforms.ToPILImage()
self.ts2 = transform=transforms.ToTensor()
mean, std =[0.5,0.5,0.5], [0.25,0.25,0.25]
self.ts3 = torchvision.transforms.Normalize(mean, std)
pass
def __call__(self, tensor):
tensor = tensor / 4 + 0.5 # unnormalize
orgYCrCb = cv2.cvtColor(np.float32(self.ts(tensor)), cv2.COLOR_BGR2YCR_CB)
Y, Cr,Cb = cv2.split(orgYCrCb)
CC = cv2.merge((Cr,Cb))
CC = np.array(CC).reshape(2,32*2,32*2) #(2,32*2,32*2)
#print(CC.shape)
return np.array(CC)
def __repr__(self):
return self.__class__.__name__
class rgb2YCrCb_(object):
def __init__(self):
self.ts = torchvision.transforms.ToPILImage()
self.ts2 = transform=transforms.ToTensor()
mean, std =[0.5,0.5,0.5], [0.25,0.25,0.25]
self.ts3 = torchvision.transforms.Normalize(mean, std)
pass
def __call__(self, tensor):
#tensor = self.ts3(self.ts2(self.ts(tensor))) / 4 + 0.5 # unnormalize
tensor = tensor / 4 + 0.5 # unnormalize
orgYCrCb = cv2.cvtColor(np.float32(self.ts(tensor)), cv2.COLOR_BGR2YCR_CB)
Y, Cr,Cb = cv2.split(orgYCrCb)
CC = cv2.merge((Cr,Cb))
Y = np.array(Y).reshape(1,32*2,32*2) #(1,32*2,32*2)
#print(Y.shape)
return Y
Cifar10を処理後提供するためのDatasetのコード
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, data_num, train_=True, transform1 = None, transform2 = None, train = True):
self.transform1 = transform1
self.transform2 = transform2
self.ts = torchvision.transforms.ToPILImage()
self.ts2 = transforms.ToTensor()
mean, std =[0.5,0.5,0.5], [0.25,0.25,0.25] #(0.485, 0.456, 0.406), (0.229, 0.224, 0.225) 後者はtorchvisionで掲載されているImagenetの平均、標準偏差だが前者を採用
self.ts3 = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std),
])
self.train = train_
self.data_dir = './'
self.data_num = data_num
self.data = []
self.label = []
# download
CIFAR10(self.data_dir, train=True, download=True)
self.data =CIFAR10(self.data_dir, train=self.train, transform=self.ts3)
def __len__(self):
return self.data_num
def __getitem__(self, idx):
out_data = self.data[idx][0]
out_label_ = self.data[idx][1]
out_label = torch.from_numpy(np.array(out_label_)).long()
if self.transform1:
out_data1 = self.transform1(out_data)
if self.transform2:
out_data2 = self.transform2(out_data)
return out_data, out_data1, out_data2, out_label
VGG16でencodeし、BnとReluで強化したdecoderのコード
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
num_classes = 10
self.block1_output = nn.Sequential (
nn.Conv2d(1, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block2_output = nn.Sequential (
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block3_output = nn.Sequential (
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block4_output = nn.Sequential (
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.block5_output = nn.Sequential (
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512*4*4, 512), #512 * 7 * 7, 4096),
nn.ReLU(True),
#nn.Dropout(),
nn.Linear(512, 32 ), #4096, 4096),
nn.ReLU(True),
#nn.Dropout(),
nn.Linear(32, num_classes) #4096
)
def forward(self, x):
x1 = self.block1_output(x)
x2 = self.block2_output(x1)
x3 = self.block3_output(x2)
x4 = self.block4_output(x3)
x = self.block5_output(x4)
x0 = x.view(x.size(0), -1)
y = self.classifier(x0)
return x4, y
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.decoder = nn.Sequential(
nn.ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.ConvTranspose2d(in_channels = 256, out_channels = 128,
kernel_size = 2, stride = 2, padding = 0),
nn.BatchNorm2d(128),
nn.ReLU(),
#nn.ConvTranspose2d(in_channels = 128, out_channels = 64,
# kernel_size = 2, stride = 2),
nn.ConvTranspose2d(in_channels = 128, out_channels = 16,
kernel_size = 2, stride = 2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.ConvTranspose2d(in_channels = 16, out_channels = 2,
kernel_size = 2, stride = 2)
)
def forward(self, x):
#x = x.reshape(32,256,4,4)
x = self.decoder(x)
return x
data_num = 50000
cifar10_full =ImageDataset(data_num, train=True, transform1=trans1, transform2=trans2)
n_train = int(len(cifar10_full)*0.95)
n_val = int(len(cifar10_full)*0.04)
n_test = len(cifar10_full)-n_train -n_val
cifar10_train, cifar10_val, cifar10_test = torch.utils.data.random_split(cifar10_full, [n_train, n_val, n_test])
trainloader = DataLoader(cifar10_train, shuffle=True, drop_last = True, batch_size=32, num_workers=0)
valloader = DataLoader(cifar10_val, shuffle=False, batch_size=32, num_workers=0)
testloader = DataLoader(cifar10_test, shuffle=False, batch_size=32, num_workers=0)
2.データ処理trans1とtrans2などを定義
以下のように処理が複雑になったので、最初に変換処理を定義しています。
ts = transforms.ToPILImage()
ts2 = transforms.ToTensor()
mean, std =[0.5,0.5,0.5], [0.25,0.25,0.25]
ts3 = transforms.Normalize(mean, std)
ts4 = transforms.Resize((64,64))
trans2 = transforms.Compose([
transforms.Resize((64,64)),
rgb2YCrCb(), #CrCb
])
trans1 = transforms.Compose([
transforms.Resize((64,64)),
rgb2YCrCb_(), #Y
])
学習コードの順番は前回と同様です。
main()の処理順は
・変換処理準備
・Dataloader読込、
・学習準備
・学習
・テスト
・学習済checkpointの保存
・結果確認のための初期画像出力
・学習済モデル読込, freeze(), eval()
・最後に、生成画像などを出力しています
epoch毎に生成したいので、for文で回しています
学習コードのmain()コード
def main():
ts = transforms.ToPILImage()
ts2 = transforms.ToTensor()
mean, std =[0.5,0.5,0.5], [0.25,0.25,0.25]
ts3 = transforms.Normalize(mean, std)
ts4 = transforms.Resize((64,64))
trans2 = transforms.Compose([
transforms.Resize((64,64)),
rgb2YCrCb(), #CrCb
])
trans1 = transforms.Compose([
transforms.Resize((64,64)),
rgb2YCrCb_(), #Y
])
data_num = 50000
cifar10_full =ImageDataset(data_num, train=True, transform1=trans1, transform2=trans2)
n_train = int(len(cifar10_full)*0.95)
n_val = int(len(cifar10_full)*0.04)
n_test = len(cifar10_full)-n_train -n_val
cifar10_train, cifar10_val, cifar10_test = torch.utils.data.random_split(cifar10_full, [n_train, n_val, n_test])
trainloader = DataLoader(cifar10_train, shuffle=True, drop_last = True, batch_size=32, num_workers=0)
valloader = DataLoader(cifar10_val, shuffle=False, batch_size=32, num_workers=0)
testloader = DataLoader(cifar10_test, shuffle=False, batch_size=32, num_workers=0)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #for gpu
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)
pl.seed_everything(0)
# model
autoencoder = LitAutoEncoder()
autoencoder = autoencoder.to(device) #for gpu
print(autoencoder)
summary(autoencoder.encoder,(1,32*2,32*2))
summary(autoencoder.decoder,(512,4,4))
#summary(autoencoder,(1,32*2,32*2))
trainer = pl.Trainer(max_epochs=1, gpus=1, callbacks=[MyPrintingCallback()]) ####epoch
sk = 0
for i in range(100):
trainer.fit(autoencoder, trainloader, valloader)
print('training_finished')
results = trainer.test(autoencoder, testloader)
print(results)
if sk%10==0:
dataiter = iter(trainloader)
_,images, images_, labels = dataiter.next()
print(images.shape, images_.shape)
images0 = []
for i in range(32):
print(i, images[i].shape, images_[i].shape)
YCC_ = cv2.merge((np.array(images[i]).reshape(64,64),np.array(images_[i]).reshape(64,64,2)))
images0_ = cv2.cvtColor(YCC_, cv2.COLOR_YCR_CB2BGR)
images0.append(ts2(images0_/255.))
# show images
imshow(torchvision.utils.make_grid(images0), 'cifar10_results',text_ =' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4))) #3
# print labels
print(' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4)))
path_ = './simple_coloring/'
PATH = path_+'example_cifar4Ln100_{}.ckpt'.format(sk)
trainer.save_checkpoint(PATH)
pretrained_model = autoencoder.load_from_checkpoint(PATH)
pretrained_model.freeze()
pretrained_model.eval()
latent_dim,ver = "Gray2Clolor", "1_{}".format(sk) #####save condition
dataiter = iter(testloader)
images0,images, images1, labels = dataiter.next() #original, Y, CrCb, label
# show images
imshow(torchvision.utils.make_grid(images.reshape(32,1,32*2,32*2)/255.),path_+'1_Y_cifar10_{}_{}'.format(latent_dim,0),text_ =' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4)))
# show images0
imshow(torchvision.utils.make_grid(images0.reshape(32,3,32,32)),path_+'2_original_cifar10_{}_{}'.format(latent_dim,0),text_ =' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4)))
# show images0
imshow(torchvision.utils.make_grid(ts4(images0).reshape(32,3,32*2,32*2)),path_+'3_original_normx2_cifar10_{}_{}'.format(latent_dim,0),text_ =' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4)))
# show images1
#imshow(torchvision.utils.make_grid(images1.reshape(32,3,32*2,32*2)),'normalized_images1_cifar10_{}_{}'.format(latent_dim,ver),text_ =' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4)))
encode_img,_ = pretrained_model.encoder(images[0:32].to('cpu').reshape(32,1,32*2,32*2)) #3
decode_img = pretrained_model.decoder(encode_img)
decode_img_cpu = decode_img.cpu()
images2 = []
for i in range(32):
print(i, images[i].shape, decode_img_cpu[i].shape)
YCC_ = cv2.merge((np.array(images[i].reshape(64,64)),np.array(decode_img_cpu[i].reshape(64,64,2))))
images2_ = cv2.cvtColor(YCC_, cv2.COLOR_YCR_CB2BGR)
images2.append(ts3(ts2(images2_/255.)))
#images2.append(ts2(images2_/255.))
imshow(torchvision.utils.make_grid(images2), path_+'4_preds_cifar10_{}_{}'.format(latent_dim,ver),text_ =' '.join('%5s' % autoencoder.classes[labels[j]] for j in range(4)))
sk += 1
if __name__ == '__main__':
start_time = time.time()
main()
print('elapsed time: {:.3f} [sec]'.format(time.time() - start_time))
| VGG16+decoder |
|---|
出力画像(生成後規格化)
|
入力画像
|
規格化元画像
|
規格化元拡大画像
|
| 拡大してみると、馬の絵でも外郭は最初の絵よりは滑らかになり全体はよく再現しているように見える。しかし、規格化元拡大画像と比較すると背中辺りのテカリが協調されすぎていて、不自然である。 |
| この傾向は、他の画像でも散見され、まだまだ改善が必要なようだ。 |
| VGG16+decoder |
|---|
出力画像(生成後規格化)
|
入力画像
|
規格化元画像
|
規格化元拡大画像
|
テストとして別画像の色塗り
別画像は、以下の参考⑦のWikipediaのページのものを利用させていただいた。
【参考】
⑦(再掲)YUV
cifar10を100epoch学習したモデルで色塗り
色塗りは、何(文字通り学習データ)をどのように(networkの種類)、どの程度(epoch数)学習したかによって変化する。
以下に、二つの例を示す。
※残念ながら、元絵とは比較にならない悪い状況である(これはどうやら解像度に依存してようだ)が、塗りだけを比較すれば違いが分かると思う
※どちらも、草の緑が全く再現できてない
| VGG16+decoder |
|---|
生成画像
|
入力グレー画像
|
元画像
|
| VGG16+decoder2 |
|---|
 |
まとめ
・画像を輝度を表すグレー画像と色差を表すCrCbに分割し、YからCrCbを学習することにより、色塗りで遊んでみた
・前回のグレーから全体を学習する手法と比較すると、精度向上が図れた
・networkをVGG16とdecoderにBn, Reluを導入したモデルで比較的よい学習結果を得た
・色空間については、別途報告する
・精度が不十分で、学習データの(配色の)統一や解像度の向上をするとさらなる改善が見込めるような気がする
おまけ
decoder()は、3種類記載しているが、実質利用しているものは、decoder()のみでdecoder2, decoder3は切り替えて利用する。
>python simple_coloring_YCC.py
Files already downloaded and verified
cuda:0
LitAutoEncoder(
(encoder): Encoder(
(block1_output): Sequential(
(0): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block2_output): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block3_output): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block4_output): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block5_output): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
(classifier): Sequential(
(0): Linear(in_features=8192, out_features=512, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=512, out_features=32, bias=True)
(3): ReLU(inplace=True)
(4): Linear(in_features=32, out_features=10, bias=True)
)
)
(decoder): Decoder(
(decoder2): Sequential(
(0): ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2))
(1): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2))
(2): ConvTranspose2d(128, 16, kernel_size=(2, 2), stride=(2, 2))
(3): ConvTranspose2d(16, 2, kernel_size=(2, 2), stride=(2, 2))
)
(decoder): Sequential(
(0): ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): ConvTranspose2d(128, 16, kernel_size=(2, 2), stride=(2, 2))
(7): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
(9): ConvTranspose2d(16, 2, kernel_size=(2, 2), stride=(2, 2))
)
(decoder3): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Upsample(scale_factor=2.0, mode=nearest)
(4): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU()
(10): Upsample(scale_factor=2.0, mode=nearest)
(11): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): ReLU()
(14): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU()
(17): Upsample(scale_factor=2.0, mode=nearest)
(18): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(19): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(20): ReLU()
(21): Conv2d(32, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): Upsample(scale_factor=2.0, mode=nearest)
)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 64, 64] 640
BatchNorm2d-2 [-1, 64, 64, 64] 128
ReLU-3 [-1, 64, 64, 64] 0
Conv2d-4 [-1, 64, 64, 64] 36,928
BatchNorm2d-5 [-1, 64, 64, 64] 128
ReLU-6 [-1, 64, 64, 64] 0
MaxPool2d-7 [-1, 64, 32, 32] 0
Conv2d-8 [-1, 128, 32, 32] 73,856
BatchNorm2d-9 [-1, 128, 32, 32] 256
ReLU-10 [-1, 128, 32, 32] 0
Conv2d-11 [-1, 128, 32, 32] 147,584
BatchNorm2d-12 [-1, 128, 32, 32] 256
ReLU-13 [-1, 128, 32, 32] 0
MaxPool2d-14 [-1, 128, 16, 16] 0
Conv2d-15 [-1, 256, 16, 16] 295,168
BatchNorm2d-16 [-1, 256, 16, 16] 512
ReLU-17 [-1, 256, 16, 16] 0
Conv2d-18 [-1, 256, 16, 16] 590,080
BatchNorm2d-19 [-1, 256, 16, 16] 512
ReLU-20 [-1, 256, 16, 16] 0
Conv2d-21 [-1, 256, 16, 16] 590,080
BatchNorm2d-22 [-1, 256, 16, 16] 512
ReLU-23 [-1, 256, 16, 16] 0
MaxPool2d-24 [-1, 256, 8, 8] 0
Conv2d-25 [-1, 512, 8, 8] 1,180,160
BatchNorm2d-26 [-1, 512, 8, 8] 1,024
ReLU-27 [-1, 512, 8, 8] 0
Conv2d-28 [-1, 512, 8, 8] 2,359,808
BatchNorm2d-29 [-1, 512, 8, 8] 1,024
ReLU-30 [-1, 512, 8, 8] 0
Conv2d-31 [-1, 512, 8, 8] 2,359,808
BatchNorm2d-32 [-1, 512, 8, 8] 1,024
ReLU-33 [-1, 512, 8, 8] 0
MaxPool2d-34 [-1, 512, 4, 4] 0
Conv2d-35 [-1, 512, 4, 4] 2,359,808
BatchNorm2d-36 [-1, 512, 4, 4] 1,024
ReLU-37 [-1, 512, 4, 4] 0
Conv2d-38 [-1, 512, 4, 4] 2,359,808
BatchNorm2d-39 [-1, 512, 4, 4] 1,024
ReLU-40 [-1, 512, 4, 4] 0
Conv2d-41 [-1, 512, 4, 4] 2,359,808
BatchNorm2d-42 [-1, 512, 4, 4] 1,024
ReLU-43 [-1, 512, 4, 4] 0
Linear-44 [-1, 512] 4,194,816
ReLU-45 [-1, 512] 0
Linear-46 [-1, 32] 16,416
ReLU-47 [-1, 32] 0
Linear-48 [-1, 10] 330
================================================================
Total params: 18,933,546
Trainable params: 18,933,546
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 26.26
Params size (MB): 72.23
Estimated Total Size (MB): 98.50
----------------------------------------------------------------
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ConvTranspose2d-1 [-1, 256, 8, 8] 524,544
BatchNorm2d-2 [-1, 256, 8, 8] 512
ReLU-3 [-1, 256, 8, 8] 0
ConvTranspose2d-4 [-1, 128, 16, 16] 131,200
BatchNorm2d-5 [-1, 128, 16, 16] 256
ReLU-6 [-1, 128, 16, 16] 0
ConvTranspose2d-7 [-1, 16, 32, 32] 8,208
BatchNorm2d-8 [-1, 16, 32, 32] 32
ReLU-9 [-1, 16, 32, 32] 0
ConvTranspose2d-10 [-1, 2, 64, 64] 130
================================================================
Total params: 664,882
Trainable params: 664,882
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.03
Forward/backward pass size (MB): 1.56
Params size (MB): 2.54
Estimated Total Size (MB): 4.13
----------------------------------------------------------------
GPU available: True, used: True
TPU available: None, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
2021-02-07 19:03:18.472890: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2021-02-07 19:03:18.472992: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
| Name | Type | Params
------------------------------------
0 | encoder | Encoder | 18.9 M
1 | decoder | Decoder | 3.1 M
------------------------------------
22.0 M Trainable params
0 Non-trainable params
22.0 M Total params