前の記事の通り、「女性顔学習のpix2pix(encoder-decoder版)の出力はみんな女性顔になりました!」の続きです。
今度は猫顔抽出して、猫顔を学習させてそれをいろいろな対象のTest出力画像を見てみました。
当たり前かもですが、みんな猫顔になりました。
そして、pix2pix(u-net版)が過学習であるという有力が証拠が見つかりました。
これは、猫顔以上にウワンにとっては重要なことかもしれません。
そして、これまでの中心テーマであった、「pix2pixは1データで学習できる」ことも併せて検証できました。
まあ、以下これら二つのエビデンスにたどり着くまでの経緯を記載していきます。
まずは猫顔の収集
これが今回一番むつかしそうな事項です。
しかし、実は人の顔と同じアプリで猫や犬の顔を抽出できました。
もちろん、人ほどヒット率というか収集率は上がりませんでしたが、10個集めればOKなので、犬猫併せて10個集めることができました。
早速、猫顔、犬顔の学習
10カテゴリに1個ずつ、猫か犬の顔データを当てました。
そして、学習はpix2pix(encoder-decoder版)で実施
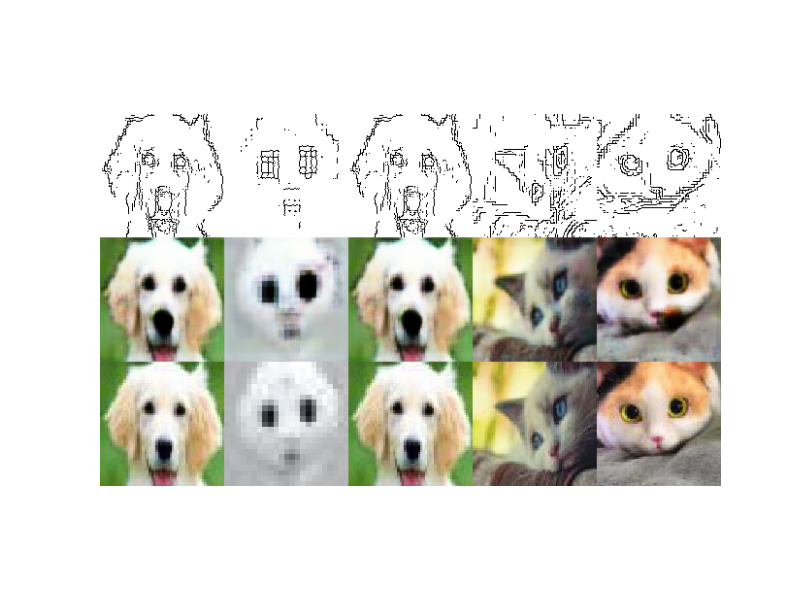
ここで、今回は学習させることが主眼なので、TrainデータもTestデータも同じセットを使いました。ただし、TrainはGray画像、Testは輪郭画像としました。
学習1 Gray画像の学習
train
gray

test
輪郭画像

学習2 輪郭画像の学習
train
輪郭画像

test
gray

学習3 学習のスウィッチ
学習2の後の結果パラメータを使って、gray画像を学習することにしました。これは、テンソルのパラメータは汎用的に学習されていれば、さらに学習しても今までの記憶を失わないだろうという仮説に基づいて実施することにしました。
その結果は以下の通りになりました。
train
gray

test
輪郭画像

仮説が成り立っているようです。両方とも最初の100epochから美しい画像を出力しました。
上の画像はねんのため少し回して500epoch時のものです。
1個データなので、500epochといっても6分くらいしかかっていません。
そして以下ウワンにとっては重要な発見をすることになりました!
pix2pix(u-net版)で学習実施
学習1 輪郭画像の学習
train
輪郭画像

600epochですが、美しい
test
gray

やはり、いまひとつ美しくない
学習2 学習のスウィッチ gray画像の学習
train
gray
100epoch

test
輪郭画像
0epoch
100epoch
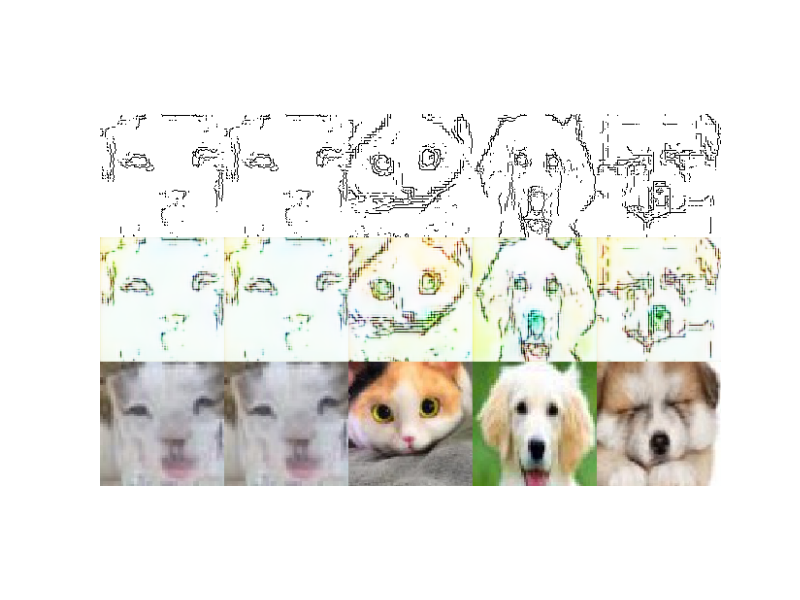
そうです!輪郭画像のTestは、最初は覚えていたのですが、たかだか100epoch1分もたたずに消えてしまいました。
これは、もともと最初にgray画像を学習したときの輪郭画像のTest結果と同一になってしまいました。
ウワンは、この事実こそ、u-net版pix2pixが汎用性がなく過学習であるという事実なのだと考察します。
上記のpix2pix(encoder-decoder版)による猫顔バージョンの適用
男性に適用


飛行機に適用


物体に適用

そして、上記の猫や犬の顔はどうも入力画像のタイプによって、変化しているようです。
これについては、もう少し詳しく見てからご紹介することとします。
まとめ
・pix2pix(u-net版)は過学習である
・pix2pix(encoder-decoder版)は2ペア画像の表裏を学習することにより、効率的に学習できる
・猫・犬顔がいっぱいで、どうやら入力データの種類に依存して変化している
課題
・まとめの最後に記載したことは、どういう法則に依存しているか不明である
・表裏学習した場合の汎用性の制限は、どちらかを学習継続した場合の汎用性と同じ領域か