 第四夜は、プロジェクトのディレクトリ構成と棋譜ダウンロードについて記述します。
### 説明したいこと
(1)プロジェクトのディレクトリ構成
(2)棋譜ダウンロード
(3)棋譜をクリーニングする
### (1)プロジェクトのディレクトリ構成
ディレクトリ構成は以下のとおりです。こういう構成でディレクトリを作成します。
第四夜は、プロジェクトのディレクトリ構成と棋譜ダウンロードについて記述します。
### 説明したいこと
(1)プロジェクトのディレクトリ構成
(2)棋譜ダウンロード
(3)棋譜をクリーニングする
### (1)プロジェクトのディレクトリ構成
ディレクトリ構成は以下のとおりです。こういう構成でディレクトリを作成します。
PJのディレクトリ
| setup.py
| train_policy.py
| kiflist_train.txt
| kiflist_test.txt
| kiflist_train_1000.txt
| kiflist_test_100.txt
├── model
| model_policy
|── pydlshogi
| |common.py
| |features.py
| |read_kifu.py
| └── network
| policy.py
└── utils
filter_csa.py
make_kifu_list.py
plot_log.py
それぞれのリソースをそれぞれのディレクトリに格納します。
そして以下のコードを実行することにより、プログラムへimportできるようになります。
pip install --no-cache-dir -e .
import setuptools
setuptools.setup(
name = 'python-dlshogi',
version = '0.0.1',
author = '',
packages = ['pydlshogi'],
scripts = [],
)
(2)棋譜ダウンロード
コンピュータ道場対局場から2016年の棋譜をダウンロードします。
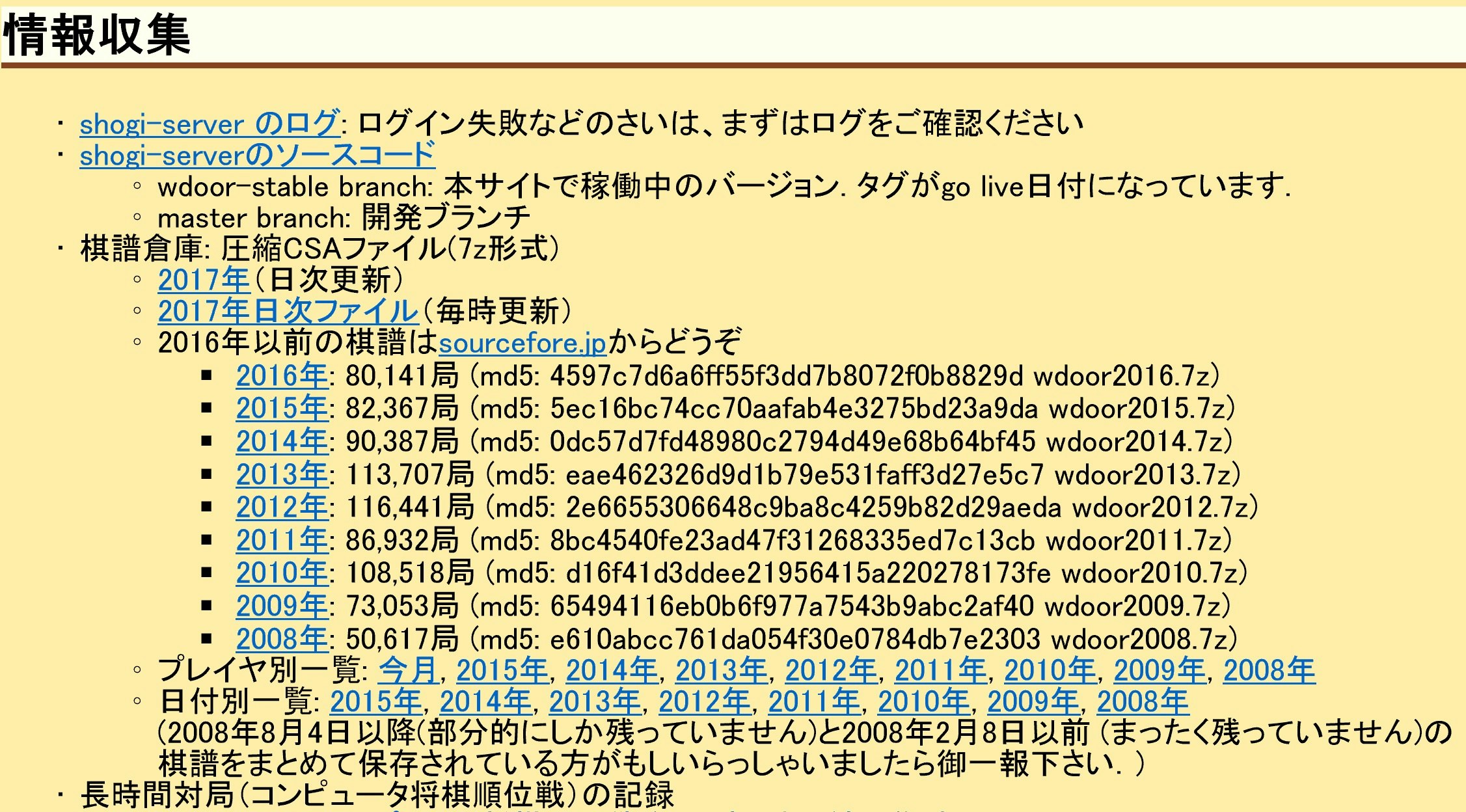
ダウンロードしたファイルは7z形式で圧縮されているので、7-Zipで解凍します。
(3)棋譜をクリーニングする
以下のプログラムで条件以外の棋譜を削除するプログラムを実行します。
※本書では例として以下の条件で棋譜を抽出しています
・投了で終了
・手数50手以上
・対局プログラムのRatingが2500以上
filter_csa.py
import argparse
import os
import re
import statistics
parser = argparse.ArgumentParser()
parser.add_argument('dir', type=str)
args = parser.parse_args()
def find_all_files(directory):
for root, dirs, files in os.walk(directory):
for file in files:
yield os.path.join(root, file)
ptn_rate = re.compile(r"^'(black|white)_rate:.*:(.*)$")
kifu_count = 0
rates = []
for filepath in find_all_files(args.dir):
rate = {}
move_len = 0
toryo = False
for line in open(filepath, 'r', encoding='utf-8'):
line = line.strip()
m = ptn_rate.match(line)
if m:
rate[m.group(1)] = float(m.group(2))
if line[:1] == '+' or line[:1] == '-':
move_len += 1
if line == '%TORYO':
toryo = True
if not toryo or move_len <= 50 or len(rate) < 2 or min(rate.values()) < 2500:
os.remove(filepath)
else:
kifu_count += 1
rates.extend([_ for _ in rate.values()])
print('kifu count :', kifu_count)
print('rate mean : {}'.format(statistics.mean(rates)))
print('rate median : {}'.format(statistics.median(rates)))
print('rate max : {}'.format(max(rates)))
print('rate min : {}'.format(min(rates)))
実行結果は以下のとおりになります。
>python utils\filter_csa.py D:\wdoor2016
kifu count : 29758
rate mean : 3063.189260030916
rate median : 3066.0
rate max : 3825.0
rate min : 2502.0
抽出条件を少し変えると以下のような結果が得られました。
>python utils\filter_csa.py D:\wdoor2016
kifu count : 13990
rate mean : 3228.983166547534
rate median : 3216.0
rate max : 3825.0
rate min : 3000.0
訓練データとテストデータに分割
訓練データとテストデータを以下のとおり、分割します。
なお、分割比は以下の入力で与えます。
parser.add_argument('--ratio', type=float, default=0.9)
import argparse
import os
import random
parser = argparse.ArgumentParser()
parser.add_argument('dir', type=str)
parser.add_argument('filename', type=str)
parser.add_argument('--ratio', type=float, default=0.9)
args = parser.parse_args()
kifu_list = []
for root, dirs, files in os.walk(args.dir):
for file in files:
kifu_list.append(os.path.join(root, file))
# シャッフル
random.shuffle(kifu_list)
# 訓練データとテストデータに分けて保存
train_len = int(len(kifu_list) * args.ratio)
with open(args.filename + '_train.txt', 'w') as f:
for i in range(train_len):
f.write(kifu_list[i])
f.write('\n')
with open(args.filename + '_test.txt', 'w') as f:
for i in range(train_len, len(kifu_list)):
f.write(kifu_list[i])
f.write('\n')
print('total kifu num = {}'.format(len(kifu_list)))
print('train kifu num = {}'.format(train_len))
print('test kifu num = {}'.format(len(kifu_list) - train_len))
読み込んだ棋譜をシャッフルしてから分割しています。
実際動かしてみると以下のような結果が出力され、
make_kifu_list.py
>python utils\make_kifu_list.py D:\wdoor2016 kifulist3000
total kifu num = 13990
train kifu num = 12591
test kifu num = 1399
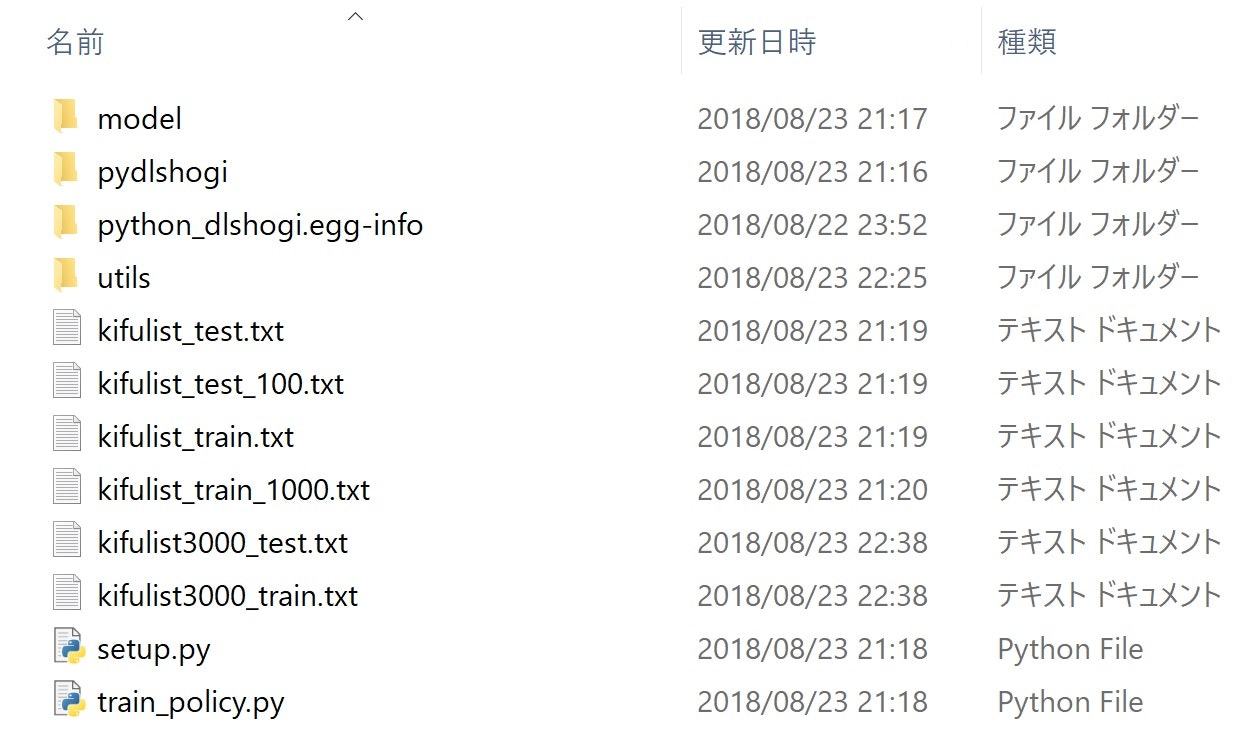
ということで、kifulist3000_test.txtとkifulist3000_train.txtという二つのファイルが新たに作成されました。
まとめ
・プログラム等のディレクトリ構成を作成した
・棋譜をFloodgateからダウンロードした
・棋譜を条件を設定して、訓練データとテストデータを作成した