第六夜は、Chainerrlの環境を構築して、遊んでみた。
簡単なはずだったが、少し苦労した。
【参考】
・chainer/chainerrl
・Docs » API Reference » Agents
・ChainerRLで三目並べを深層強化学習(Double DQN)してみた
やったこと
(0)環境構築
(1)QuickStartを動かしてみた
(2)chainerrl / examples / gym / train_dqn_gym.py を学習してみる
(3)三目並べを試してみる
(0)環境構築
はっきり言って、以下のコマンドで簡単に出来た
pip install chainerrl
あとは上記サイトから右上の緑のところからzipをダウンロードして配置します。
(1)QuickStartを動かしてみた
ChainerRL Quickstart Guide
This is a quickstart guide for users who just want to try ChainerRL for the first time.
If you have not yet installed ChainerRL, run the command below to install it:
pip install chainerrl
If you have already installed ChainerRL, let's begin!
First, you need to import necessary modules. The module name of ChainerRL is chainerrl. Let's import gym and numpy as well since they are used later.
ということで、このjupyter notebookのファイルをコピペして一つにします。
import chainer
import chainer.functions as F
import chainer.links as L
import chainerrl
import gym
import numpy as np
env = gym.make('CartPole-v0')
print('observation space:', env.observation_space)
print('action space:', env.action_space)
obs = env.reset()
env.render()
print('initial observation:', obs)
action = env.action_space.sample()
obs, r, done, info = env.step(action)
print('next observation:', obs)
print('reward:', r)
print('done:', done)
print('info:', info)
class QFunction(chainer.Chain):
def __init__(self, obs_size, n_actions, n_hidden_channels=50):
super().__init__()
with self.init_scope():
self.l0 = L.Linear(obs_size, n_hidden_channels)
self.l1 = L.Linear(n_hidden_channels, n_hidden_channels)
self.l2 = L.Linear(n_hidden_channels, n_actions)
def __call__(self, x, test=False):
"""
Args:
x (ndarray or chainer.Variable): An observation
test (bool): a flag indicating whether it is in test mode
"""
h = F.tanh(self.l0(x))
h = F.tanh(self.l1(h))
return chainerrl.action_value.DiscreteActionValue(self.l2(h))
obs_size = env.observation_space.shape[0]
n_actions = env.action_space.n
q_func = QFunction(obs_size, n_actions)
# Uncomment to use CUDA
q_func.to_gpu(0)
_q_func = chainerrl.q_functions.FCStateQFunctionWithDiscreteAction(
obs_size, n_actions,
n_hidden_layers=2, n_hidden_channels=50)
# Use Adam to optimize q_func. eps=1e-2 is for stability.
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
# Set the discount factor that discounts future rewards.
gamma = 0.95
# Use epsilon-greedy for exploration
explorer = chainerrl.explorers.ConstantEpsilonGreedy(
epsilon=0.3, random_action_func=env.action_space.sample)
# DQN uses Experience Replay.
# Specify a replay buffer and its capacity.
replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6)
# Since observations from CartPole-v0 is numpy.float64 while
# Chainer only accepts numpy.float32 by default, specify
# a converter as a feature extractor function phi.
phi = lambda x: x.astype(np.float32, copy=False)
# Now create an agent that will interact with the environment.
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=500, update_interval=1,
target_update_interval=100, phi=phi)
実はこのupdate_interval=1,target_update_interval=100がかつては、update_frequency=1, target_update_frequency=100だったが、以下のとおり仕様変更されているのでこれに変更する。
update_interval (int) – Model update interval in step
•target_update_interval (int) – Target model update interval in step
n_episodes = 200
max_episode_len = 200
for i in range(1, n_episodes + 1):
obs = env.reset()
reward = 0
done = False
R = 0 # return (sum of rewards)
t = 0 # time step
while not done and t < max_episode_len:
# Uncomment to watch the behaviour
# env.render()
action = agent.act_and_train(obs, reward)
obs, reward, done, _ = env.step(action)
R += reward
t += 1
env.render() #追記;学習途中の様子も描画する
if i % 10 == 0:
print('episode:', i,
'R:', R,
'statistics:', agent.get_statistics())
agent.stop_episode_and_train(obs, reward, done)
print('Finished.')
ということで、学習できました。
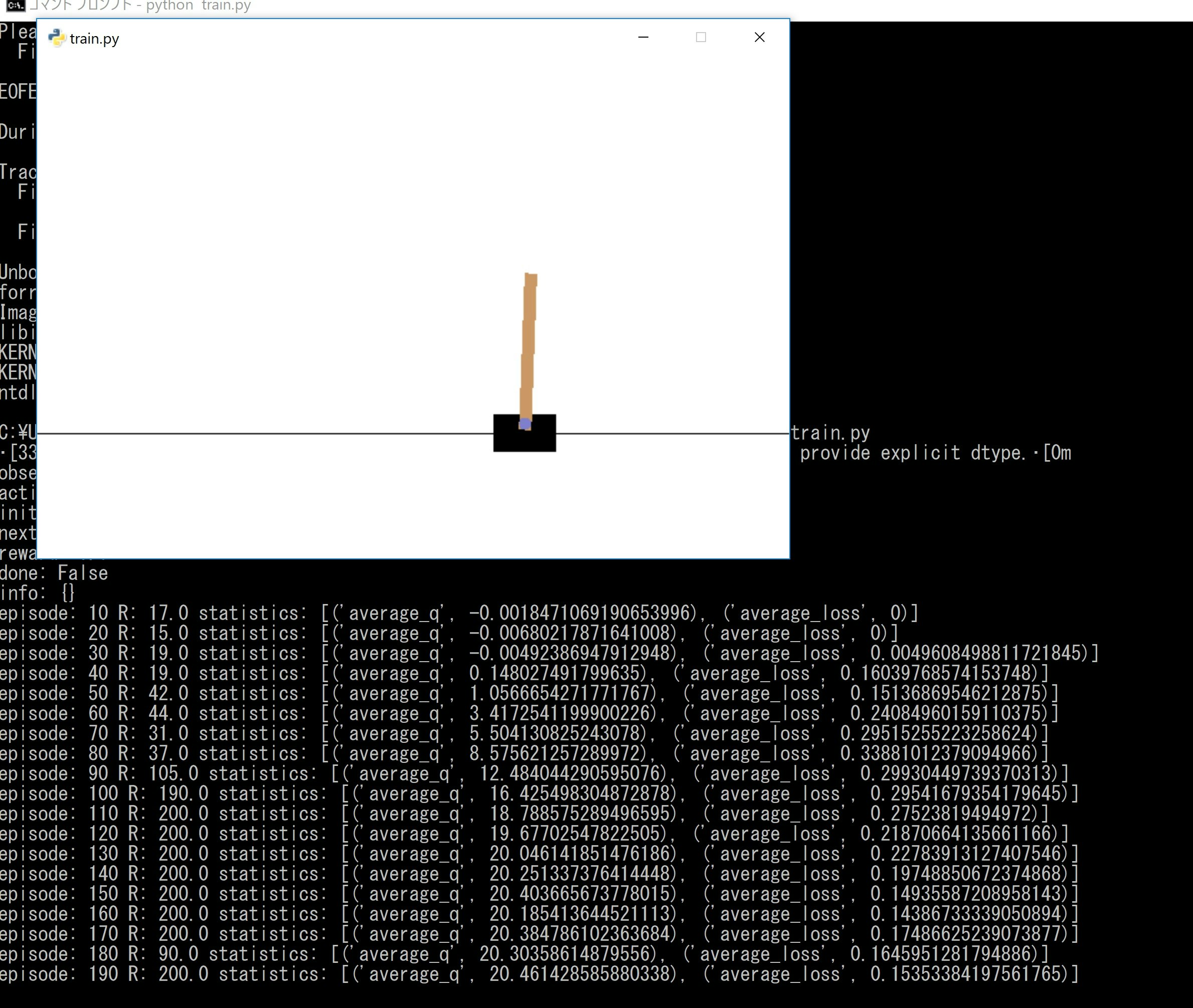
(2)chainerrl / examples / gym / train_dqn_gym.py を学習してみる
これってすんなり動くはずだったのですが、やはり以下二点変更しました。
96 env = chainerrl.wrappers.CastObservationToFloat32(env)
104 env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor)
ここでchainerrl.wrappersでエラーとなりました。
仕方ないので、wrappersの関数をtrain_dqn_gym.pyと同じディレクトリに入れて、以下のように直接呼ぶように変更しました。
from cast_observation import CastObservationToFloat32
from scale_reward import ScaleReward
96 env = CastObservationToFloat32(env)
104 env = ScaleReward(env, args.reward_scale_factor)
そして、このままだとrenderしてくれないので、
for i in range(10):
obs = env.reset()
done = False
R = 0
t = 0
while not done and t < 200:
env.render()
action = agent.act(obs)
obs, r, done, _ = env.step(action)
R += r
t += 1
print('test episode:', i, 'R:', R)
agent.stop_episode()
を最後に追記してenv.render()するようにしました。
python train_dqn_gym.py --env CartPole-v0

python train_dqn_gym.py --env Pendulum-v0
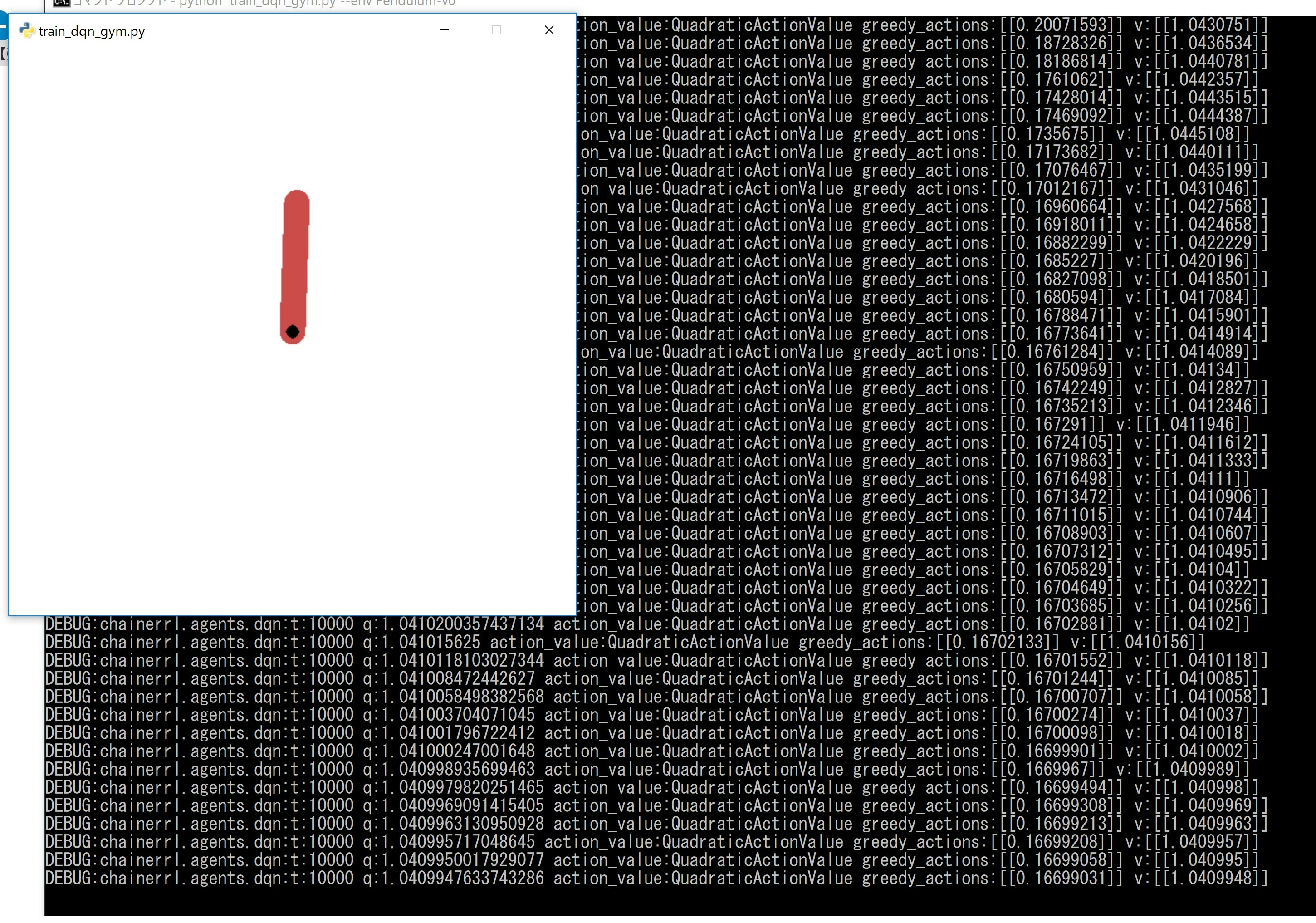
(3)三目並べを試してみる
こちらもほぼコピペで動きました。
変更したのは上記の部分です。
agent_p1 = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=500,target_update_interval=100,
update_interval=1) #, update_frequency=1,target_update_frequency=100
agent_p2 = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=500,target_update_interval=100,
update_interval=1) #, update_frequency=1,target_update_frequency=100
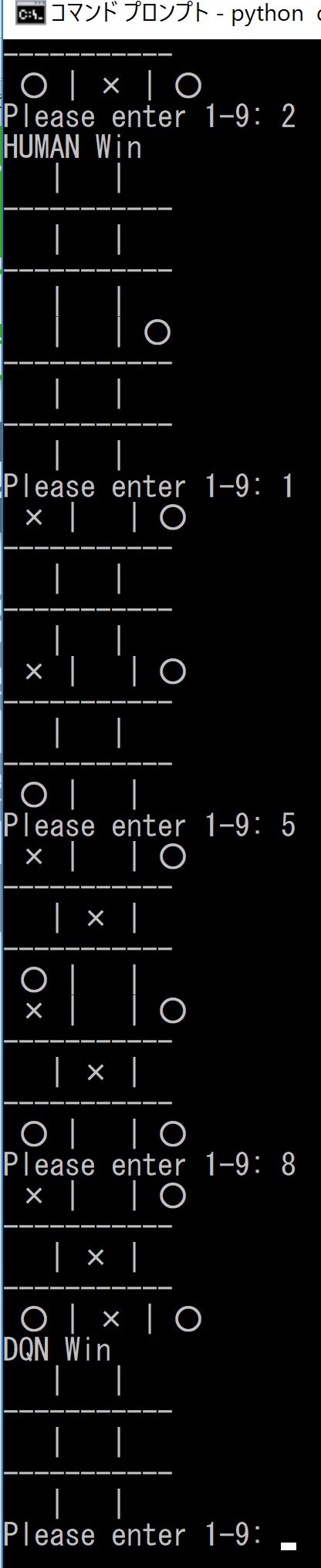
これは、参考記事のとおり、35万回学習するとすごく強くなりました。
つまり、定石と呼べるものを学習したようです。少しでも気を許すと負けてしまいます。
まとめ
・Chainerrlで遊んだ
・いくつか並べて遊んだので、基本的なコードはほぼ理解できた
・自前ゲームをやってみよう作ってみよう