 第十五夜は、満月。。。いろいろ満ちてきてこのシリーズも最後のとどめをしたいところ、脈絡ないけどいろいろモデルを変更して最後の悪あがきをしてみようと思う。それでも方向性は二つ、一つはLayer13が今までで一番強いのでそれを延長する。もう一つはResnetがそれなりに学習が早く一致率が高いのでその可能性を追求する。
### やったこと
(0)最初の13層のモデル
(1)Resnet10Blockでやってみた
(2)Layer23層をPolicy,Valueのマルチタスクに変更
(3)ResnetのBlockを4層に増やしてみた
### (0)最初の13層のモデル
まず、今一番強いモデルは以下の最初の13層モデルです。
第十五夜は、満月。。。いろいろ満ちてきてこのシリーズも最後のとどめをしたいところ、脈絡ないけどいろいろモデルを変更して最後の悪あがきをしてみようと思う。それでも方向性は二つ、一つはLayer13が今までで一番強いのでそれを延長する。もう一つはResnetがそれなりに学習が早く一致率が高いのでその可能性を追求する。
### やったこと
(0)最初の13層のモデル
(1)Resnet10Blockでやってみた
(2)Layer23層をPolicy,Valueのマルチタスクに変更
(3)ResnetのBlockを4層に増やしてみた
### (0)最初の13層のモデル
まず、今一番強いモデルは以下の最初の13層モデルです。
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class PolicyValueNetwork(Chain):
def __init__(self):
super(PolicyValueNetwork, self).__init__()
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
self.l2=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l3=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l4=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l5=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l6=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l7=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l8=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l9=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l10=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l11=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l12=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
# policy network
self.l13=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.l13_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.l13_v=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.l14_v=L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.l15_v=L.Linear(fcl, 1)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = F.relu(self.l3(h2))
h4 = F.relu(self.l4(h3))
h5 = F.relu(self.l5(h4))
h6 = F.relu(self.l6(h5))
h7 = F.relu(self.l7(h6))
h8 = F.relu(self.l8(h7))
h9 = F.relu(self.l9(h8))
h10 = F.relu(self.l10(h9))
h11 = F.relu(self.l11(h10))
h12 = F.relu(self.l12(h11))
# policy network
h13 = self.l13(h12)
policy = self.l13_bias(F.reshape(h13, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h13_v = F.relu(self.l13_v(h12))
h14_v = F.relu(self.l14_v(h13_v))
value = self.l15_v(h14_v)
return policy, value
そして、収束性は以下のとおりでした。
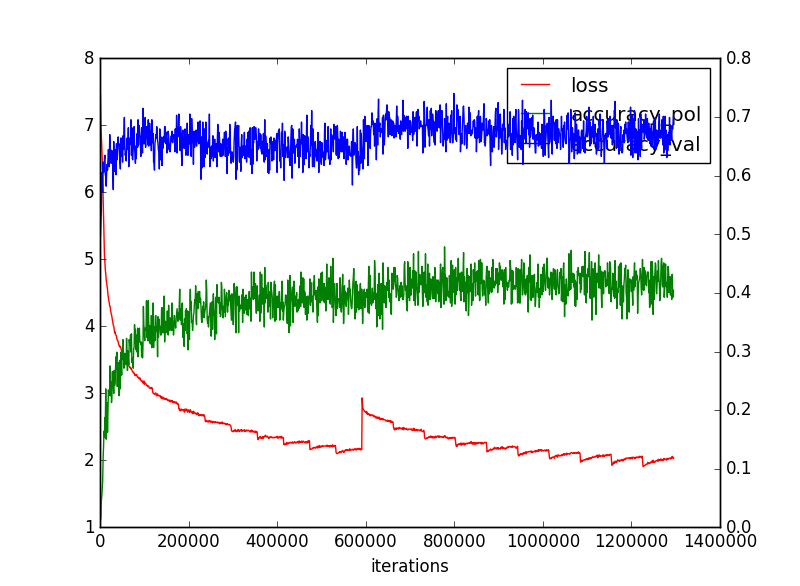
以下ではこれがある意味目標になります。
そして、以下のモデルでは学習データは同じでFloodgateの2016年と2017年の棋譜です。
(1)Resnet10Blockでやってみた
前にも出しましたが、そもそもResnet5Blockは以下のようなモデル
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class Block(Chain):
def __init__(self):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn1 = L.BatchNormalization(ch)
self.conv2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn2 = L.BatchNormalization(ch)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)
class PolicyValueResnet(Chain):
def __init__(self, blocks = 5):
super(PolicyValueResnet, self).__init__()
self.blocks = blocks
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
for i in range(1, blocks):
self.add_link('b{}'.format(i), Block())
# policy network
self.policy=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.policy_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.value1=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.value1_bn = L.BatchNormalization(MOVE_DIRECTION_LABEL_NUM)
self.value2=L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.value3=L.Linear(fcl, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
for i in range(1, self.blocks):
h = self['b{}'.format(i)](h)
# policy network
h_policy = self.policy(h)
u_policy = self.policy_bias(F.reshape(h_policy, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h_value = F.relu(self.value1_bn(self.value1(h)))
h_value = F.relu(self.value2(h_value))
u_value = self.value3(h_value)
return u_policy, u_value
def __init__(self, blocks = 5):
のblocks=10とすると10blockで学習できる。
もちろん、ほかの数字を入れればそのblock数のResnetモデルで学習できる。
一応、5blocksは前後の層を含めると、元々の13層のモデルとほぼ同じような12層のconvolutionを持つモデルになる。
今回はこれを倍の10blockにしてconvolutionが22層になっている。
というわけで、以下のような収束性になった。
上段が5Block、下が10Blockです
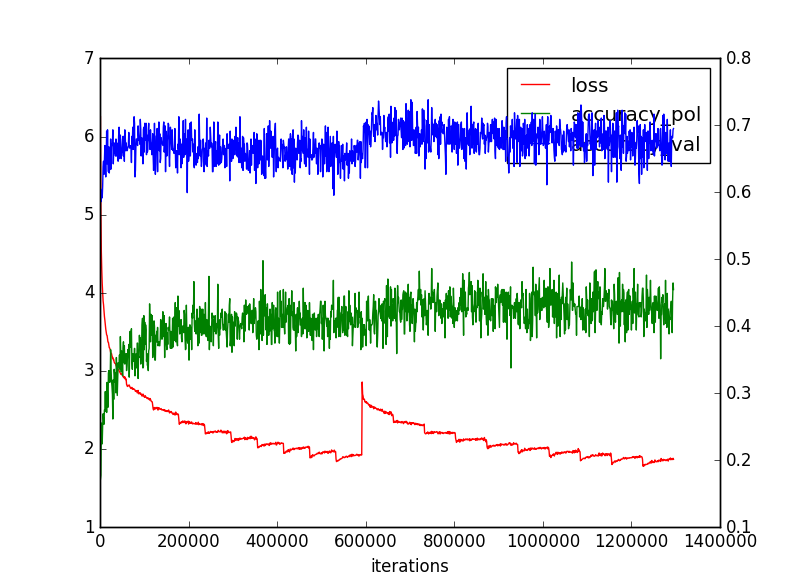
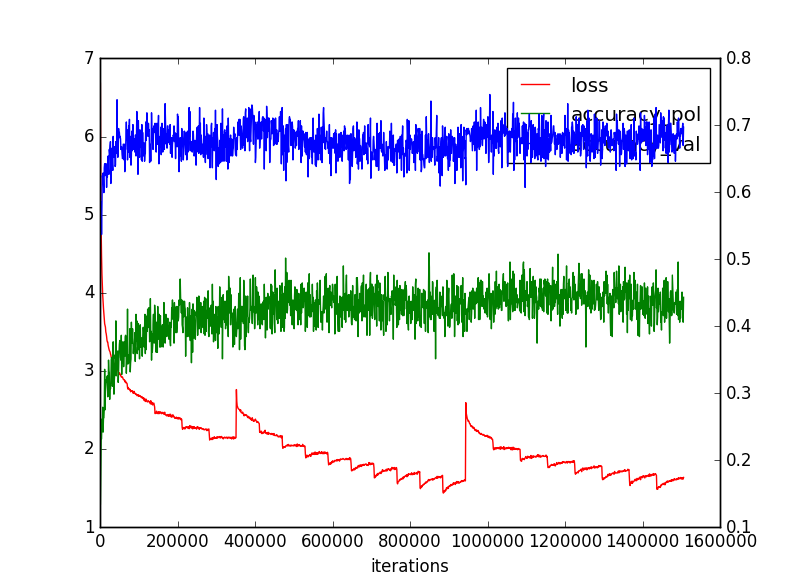
(2)Layer23層をPolicy,Valueのマルチタスクに変更
本書では、この23層のNetworkはPolicyのみの学習で利用しているが、ここではマルチタスクにして同時学習して13層のマルチタスクと比較して強くなるか確認した。
23層のマルチタスクは以下のとおり、もともとのモデルが分かり易いので追加する場合も簡単にできます。
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class PolicyValueNetwork23(Chain):
def __init__(self):
super(PolicyValueNetwork23, self).__init__()
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
self.l2=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l3=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l4=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l5=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l6=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l7=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l8=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l9=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l10=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l11=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l12=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l13=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l14=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l15=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l16=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l17=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l18=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l19=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l20=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l21=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l22=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
# policy network
self.l23=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.l23_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.l23_v=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.l24_v=L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.l25_v=L.Linear(fcl, 1)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = F.relu(self.l3(h2))
h4 = F.relu(self.l4(h3))
h5 = F.relu(self.l5(h4))
h6 = F.relu(self.l6(h5))
h7 = F.relu(self.l7(h6))
h8 = F.relu(self.l8(h7))
h9 = F.relu(self.l9(h8))
h10 = F.relu(self.l10(h9))
h11 = F.relu(self.l11(h10))
h12 = F.relu(self.l12(h11))
h13 = F.relu(self.l13(h12))
h14 = F.relu(self.l14(h13))
h15 = F.relu(self.l15(h14))
h16 = F.relu(self.l16(h15))
h17 = F.relu(self.l17(h16))
h18 = F.relu(self.l18(h17))
h19 = F.relu(self.l19(h18))
h20 = F.relu(self.l20(h19))
h21 = F.relu(self.l21(h20))
h22 = F.relu(self.l22(h21))
# policy network
h23 = self.l23(h22)
policy = self.l23_bias(F.reshape(h23, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h23_v = F.relu(self.l23_v(h22))
h24_v = F.relu(self.l24_v(h23_v))
value = self.l25_v(h24_v)
return policy, value
あとは、収束してくれるかどうか。。。収束してくれると13層が強くなったので強くなるかも。。
結果は以下のとおり
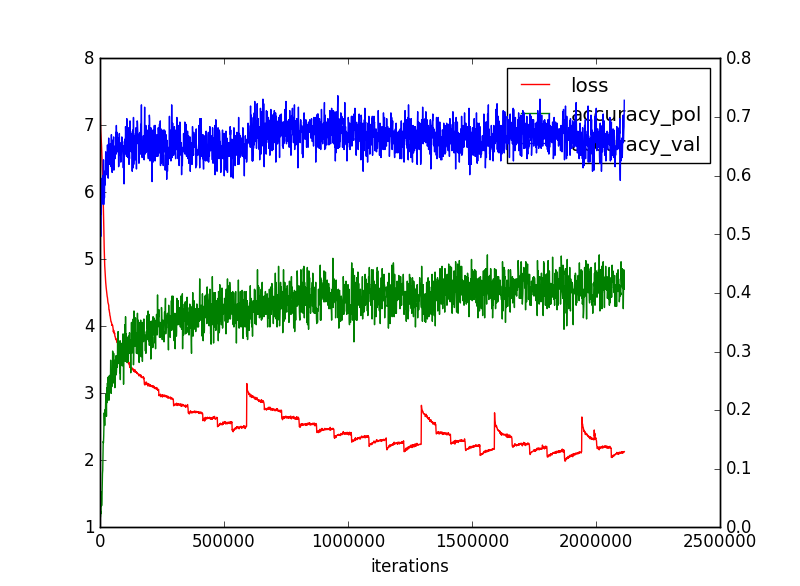
実はこれ最後のところで、以下のようにパラメーターが崩壊しています。
2018/09/09 02:53:23 INFO epoch = 29, iteration = 2112000, loss = 2.1264465, accuracy_pol = 0.43945312,accuracy_val = 0.67578125
2018/09/09 02:54:04 INFO epoch = 29, iteration = 2113000, loss = 2.1251316, accuracy_pol = 0.4296875,accuracy_val = 0.68359375
2018/09/09 02:54:45 INFO epoch = 29, iteration = 2114000, loss = 2.1300569, accuracy_pol = 0.40625,accuracy_val = 0.7285156
2018/09/09 02:55:26 INFO epoch = 29, iteration = 2115000, loss = nan, accuracy_pol = 0.0,accuracy_val = 0.5214844
2018/09/09 02:56:08 INFO epoch = 29, iteration = 2116000, loss = nan, accuracy_pol = 0.0,accuracy_val = 0.5097656
2018/09/09 02:56:49 INFO epoch = 29, iteration = 2117000, loss = nan, accuracy_pol = 0.0,accuracy_val = 0.51171875
2018/09/09 02:57:30 INFO epoch = 29, iteration = 2118000, loss = nan, accuracy_pol = 0.0,accuracy_val = 0.49414062
2018/09/09 02:58:11 INFO epoch = 29, iteration = 2119000, loss = nan, accuracy_pol = 0.0,accuracy_val = 0.5
2018/09/09 02:58:52 INFO epoch = 29, iteration = 2120000, loss = nan, accuracy_pol = 0.0,accuracy_val = 0.5058594
2018/09/09 02:58:55 INFO validate test data
2018/09/09 03:01:18 INFO epoch = 29, iteration = 2120061, train loss avr = nan, test accuracy_pol = 0.00011980524,test accuracy_val = 0.5018642
つまり、ほぼランダムな手を選んでいて、たぶんパラメーターのほとんどがナンセンスな値になってしまったようです。
(3)ResnetのBlockを4層に増やしてみた
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class Block(Chain):
def __init__(self):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn1 = L.BatchNormalization(ch)
self.conv2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn2 = L.BatchNormalization(ch)
self.conv3 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn3 = L.BatchNormalization(ch)
self.conv4 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn4 = L.BatchNormalization(ch)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = F.relu(self.bn2(self.conv2(x)))
h3 = F.relu(self.bn3(self.conv3(x)))
h4 = self.bn4(self.conv4(h3))
return F.relu(x + h4)
class PolicyValueResnet(Chain):
def __init__(self, blocks = 5):
super(PolicyValueResnet, self).__init__()
self.blocks = blocks
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
for i in range(1, blocks):
self.add_link('b{}'.format(i), Block())
# policy network
self.policy=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.policy_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.value1=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.value1_bn = L.BatchNormalization(MOVE_DIRECTION_LABEL_NUM)
self.value2=L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.value3=L.Linear(fcl, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
for i in range(1, self.blocks):
h = self['b{}'.format(i)](h)
# policy network
h_policy = self.policy(h)
u_policy = self.policy_bias(F.reshape(h_policy, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h_value = F.relu(self.value1_bn(self.value1(h)))
h_value = F.relu(self.value2(h_value))
u_value = self.value3(h_value)
return u_policy, u_value
これ結構、教育的だと思う。
そして、ほんとに収束するのかちょっと、。。。もちろん先ほどの23層と同じように22層だし、shortcutになっているから収束性はいいはずだし、Resnetだから精度も上がるはず、ということで期待がもてます。
まだ2016年の学習段階ですが、以下のとおりの収束性です。
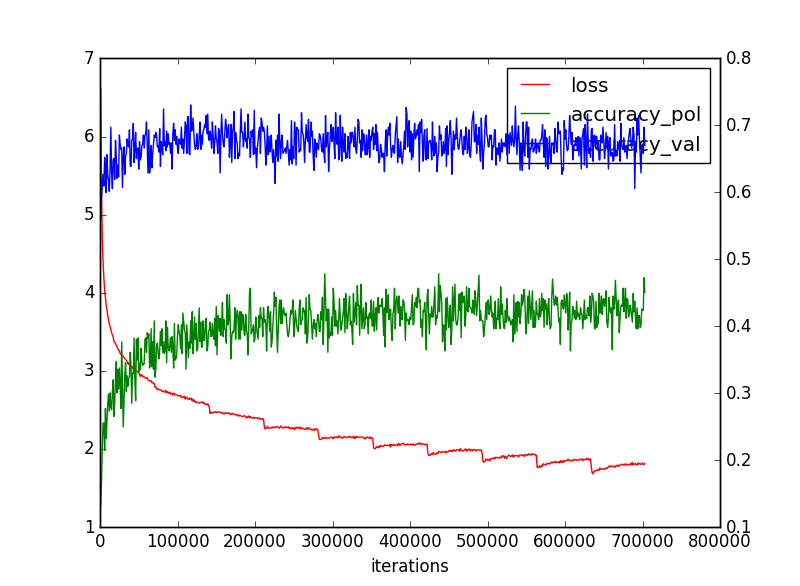
(4)Resnetのさらなる改善について
さらなる試みは、実は上記はoriginalなResnetの構造であるが、これを変更してさらなる改善が期待できるようだ。
以前、WideResidualNetworkを利用したAutoencoderを実施して、高精度なAEを作成したが、その時は参考サイトにあるようなモデル構成であった。
【参考】
・Residual Network(ResNet)の理解とチューニングのベストプラクティス
・AutoEncoder / wide_resnet_AE.py
つまり、どちらも以下の右側の構造が最適だと云っている。
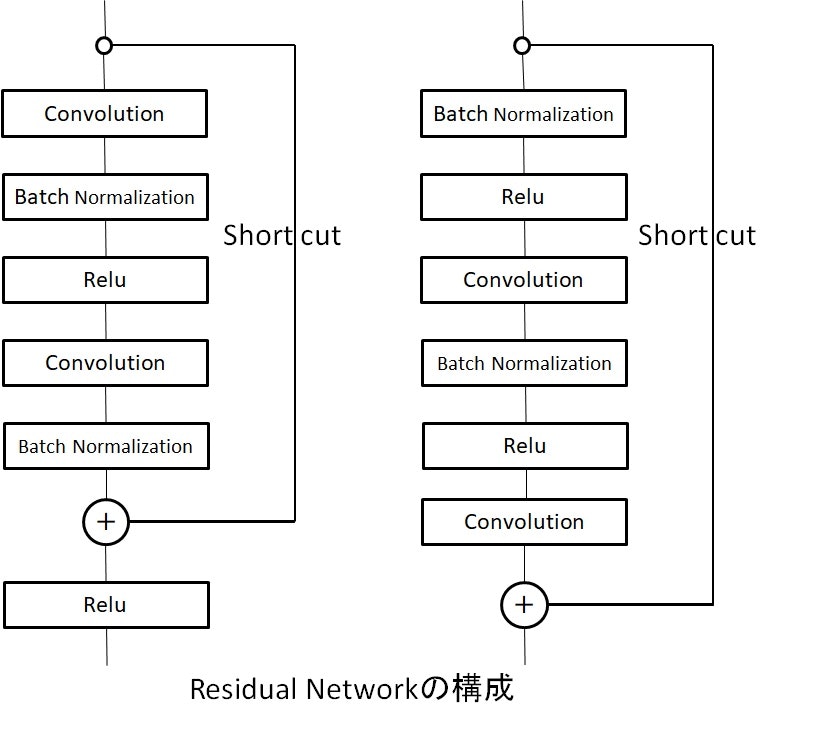
ということで、次回はChainerでも上記の構造で試そうと思う。
いずれにしても、収束性をみるだけでほぼ1昼夜くらいかかるので、かなりしんどいがとにかく、もう少し集中して納得のいくところまで追求しようと思う。
まとめ
・まだまだ途中だが、いわゆる画像で成功しているNetworkモデルを適用して収束性を見た
・将棋AIとしての能力が方策と価値の一致率に依存しているのだろうが、振る舞いが今一つ同期しておらず、何によって決まっているのかが今一つ決定していない