 第十六夜は、ある意味整理するために、ここまで作成した将棋AIのどれが強いか総当たり戦をやってみた。
【重要】どうやらResnetのPGにバグがあったようです。ということで本記事は参考程度に読んでください。[ディープなNetworkモデルについて別記事](https://qiita.com/MuAuan/items/a4eef4f6b4f214a88ed1)にする予定です。
### やったこと
(1)将棋AIのlossと一致率(方策、価値)
(2)総当たり戦の結果
### (1)将棋AIのlossと一致率(方策、価値)
それぞれのNetworkモデルに名称からリンクしています。
以下の収束性を見ると、収束性はバラバラです。そして一致率の良さからはResnetのNo.Batch Normalizationのものがとてもよくて期待が持てます。
また、ほかのものはモンテカルロ木探索を使っていますが、Policyだけは方策ネットワークがいいといった手をそのまま選んでおり、ある意味純粋にDeepLearningを使っていると云えるものです。
第十六夜は、ある意味整理するために、ここまで作成した将棋AIのどれが強いか総当たり戦をやってみた。
【重要】どうやらResnetのPGにバグがあったようです。ということで本記事は参考程度に読んでください。[ディープなNetworkモデルについて別記事](https://qiita.com/MuAuan/items/a4eef4f6b4f214a88ed1)にする予定です。
### やったこと
(1)将棋AIのlossと一致率(方策、価値)
(2)総当たり戦の結果
### (1)将棋AIのlossと一致率(方策、価値)
それぞれのNetworkモデルに名称からリンクしています。
以下の収束性を見ると、収束性はバラバラです。そして一致率の良さからはResnetのNo.Batch Normalizationのものがとてもよくて期待が持てます。
また、ほかのものはモンテカルロ木探索を使っていますが、Policyだけは方策ネットワークがいいといった手をそのまま選んでおり、ある意味純粋にDeepLearningを使っていると云えるものです。
| 名称 | loss | 一致率(方策) | 一致率(価値) | 備考 |
|---|---|---|---|---|
| policy | 1.682677 | 0.4226734 | - | 方策ネットワークのみ |
| Policy_Value;Layer13 | 2.016 | 0.4204578 | 0.67033803 | 13層の方策・価値ネットワークでMCTS |
| Policy_Value;Layer23 | 2.1938 | 0.41157416 | 0.6601796 | 23層のMCTS |
| 1.844657 | 0.4195995 | 0.6717752 | Resnet5block12層 | |
| 1.818387 | 0.40154335 | 0.6761505 | Resnet10block22層 | |
| 2.1583886 | 0.39926776 | 0.6727783 | 1Block4層のResnetを5block;22層 | |
| 1.80566 | 0.4327175 | 0.68042606 | Resnet5block12層だがBatchNormalizationなし |
(2)総当たり戦の結果
だいたいの強さ指標としてLesserKaiを参加させてみました。
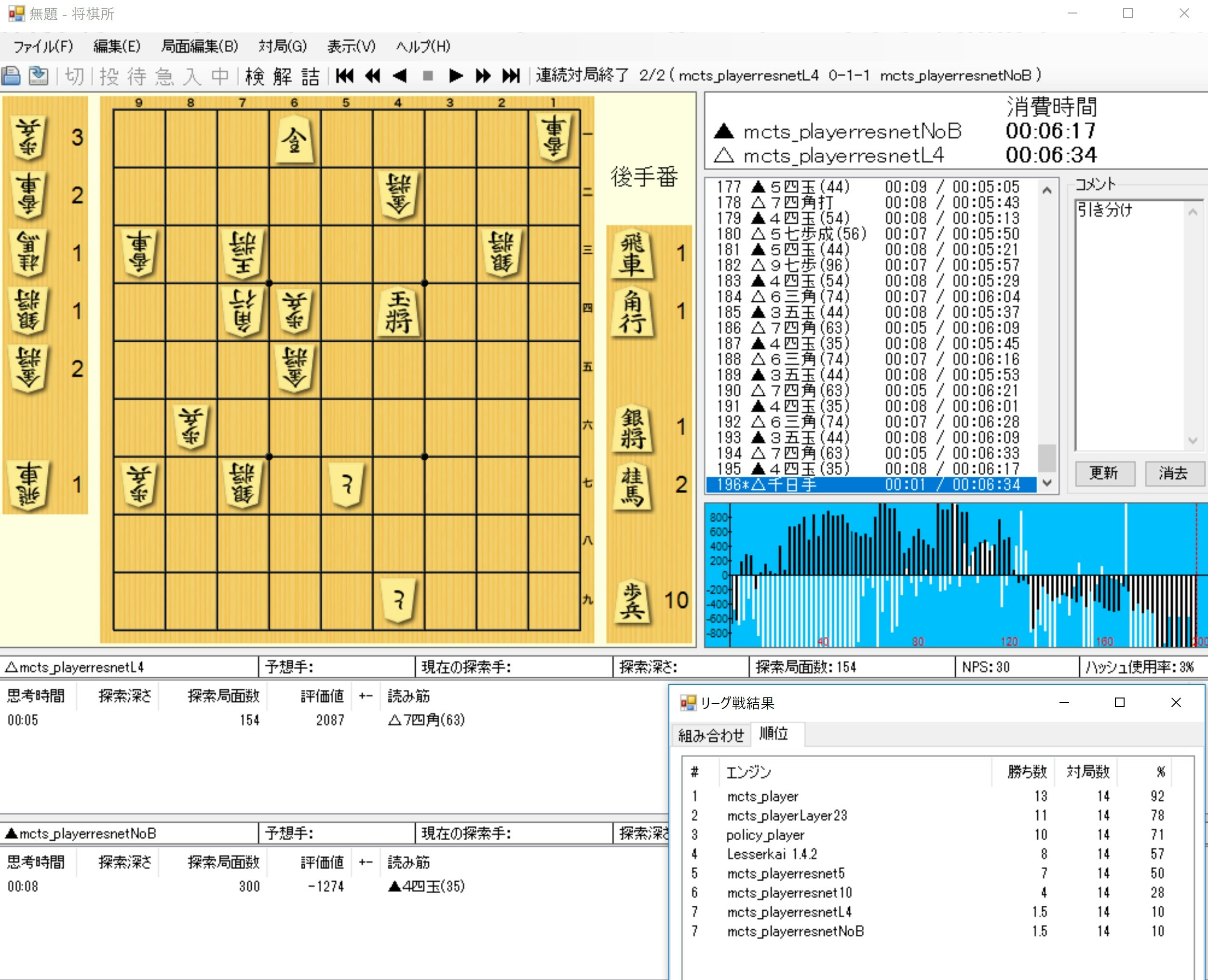
勝敗は以下のとおり、順位が出ました。
なんとなく上記の一致率やLossの値があてにならないのがわかります。
※これすごく重要なことだと思いますが、中身はわかっていません

それぞれの対戦の結果は以下のとおりになりました。
| ---------- | L13 | L23 | policy | LKai | R5 | R10 | RL4 | RNoBN | Win | Draw | Loss | Pt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L13 | - | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 13 | 0 | 1 | 13 |
| L23 | 0 | - | 1 | 2 | 2 | 2 | 2 | 2 | 11 | 0 | 3 | 11 |
| policy | 1 | 1 | - | 2 | 1 | 1 | 2 | 2 | 10 | 0 | 4 | 10 |
| LKai | 0 | 0 | 0 | - | 2 | 2 | 2 | 2 | 8 | 0 | 6 | 8 |
| R5 | 0 | 0 | 1 | 0 | - | 2 | 2 | 2 | 7 | 0 | 7 | 7 |
| R10 | 0 | 0 | 1 | 0 | 0 | - | 1 | 2 | 4 | 0 | 10 | 4 |
| RL4 | 0 | 0 | 0 | 0 | 0 | 1 | - | 0.5 | 1 | 1 | 12 | 1.5 |
| RNoBN | 0 | 0 | 0 | 0 | 0 | 0 | 1.5 | - | 1 | 1 | 12 | 1.5 |
ここでLKaiというのが将棋所に付属しているLesserKaiでレイティングは713ということになっています。ある意味これに勝てて初めて将棋らしくなると云えます。
今回、一番うれしかったのはPolicyがLesserKaiより上にきて、しかもすべてのNetworkモデルと互角以上で、負けなかったことです。
※最終的な目標はこの方策ネットワークによるモデルが一番強くなることです
勝敗の特徴としてはディープなものやResnetの成績が悪いということです。これは棋譜を十分に学習していないからかもしれません。もう少し学習を進めていけば真偽がわかると思います。
※どこかのフェーズで強化学習をする必要があると思っています
まとめ
・自前モデルでコンピュータ将棋選手権をやってみた
・方策ネットワークのPolicyが案外いい結果を出した
・ディープもResnetもあまりいい結果が出なかった
・そもそも一致率やLossの値が強さの指標値になっていない
・最終的な目標はこの方策ネットワークによるモデルが一番強くなることです
・強化学習をしてみよう