GANついでに、Conditional-GANもKeras Exampleのモデルを改造してCifar10対応して遊んでみた。
KerasではMNISTのサンプルが参考に掲載されている。これを出発点として改造する。
【参考】
・Keras-GAN/ccgan/ccgan.py
Cifar10はやはりGANの対象としては難しい対象なのかもしれないなぁ~とは思うが、Autoencoderでは綺麗な画像も得られているので、工夫(モデルやサイズなど)次第では綺麗な画像が得られるかもしれない。ということですが、今回はここが不十分ですが、以下のものが得られました。
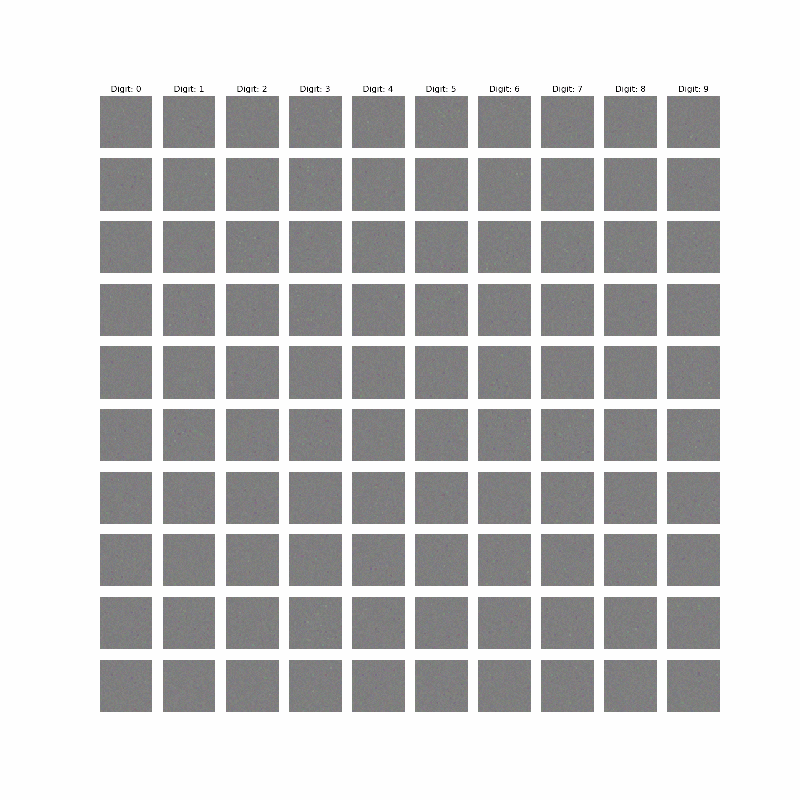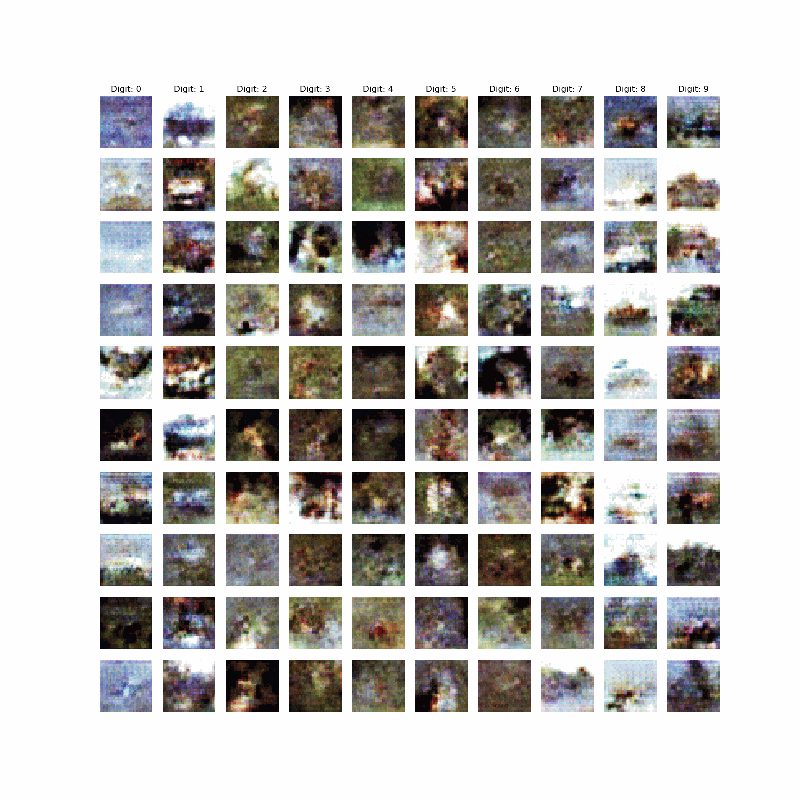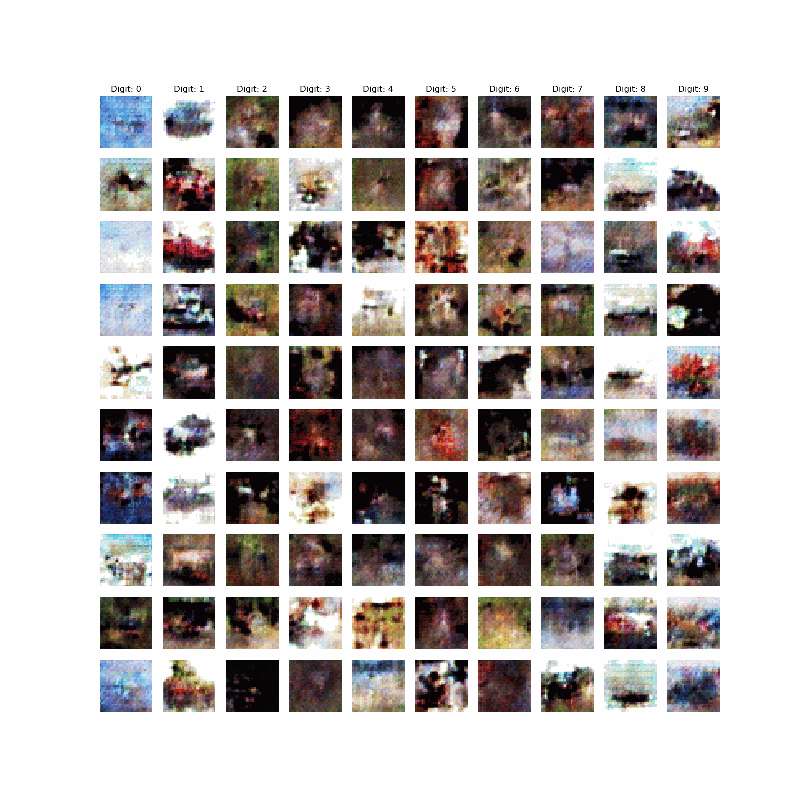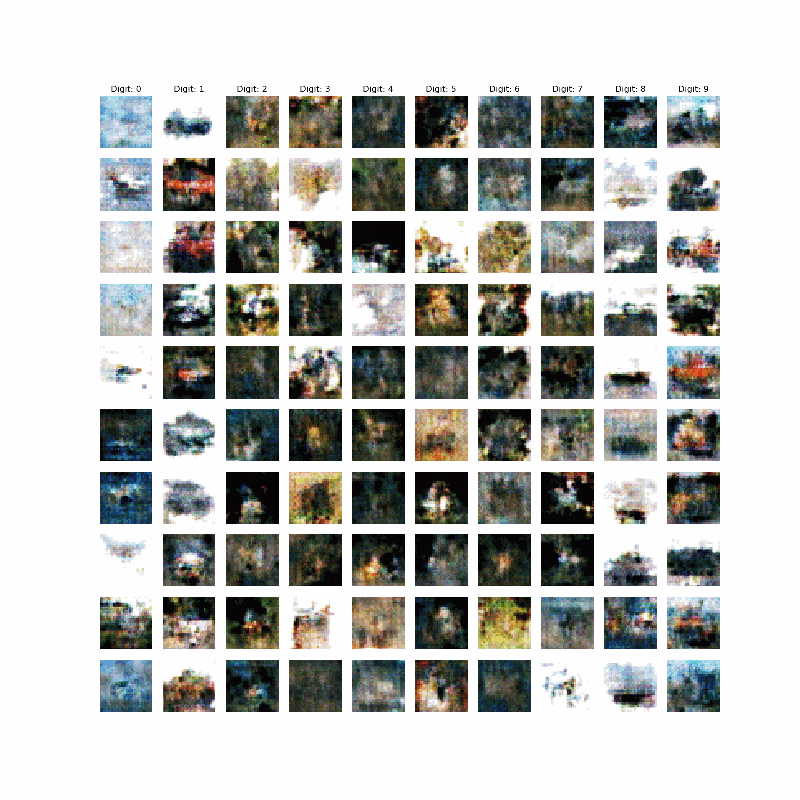
今回やったこと
・CGAN-Kerasのexapleのモデルを変更して画像改善する
・Cifar10が学習できるようにする
・機能追加と出力改善
・CGAN-Kerasのexapleのモデルを変更して画像改善する
上記のExampleを動かして出力された画像をgifアニメーションにすると以下のようになった。

しかし、やはりDenseだけのモデルだとこの程度の精度なのだ。
そこで、以下のようにモデルを変更する。
すなわち、入力と出力は変更せずに中間だけConv2DTransposeを利用してstrides=2でUpconversionして畳み込み学習し、学習(2次元的フィルター)効果を得ようとするものである。
generatorについて、
今回はExampleからの流れで入力については、BatchNormalization(momentum=0.8)とLeakyReLU(alpha=0.2)を利用し、その後はDCGANで効果のあったactivation='relu'と最終段だけactivation='tanh'を利用した。また、層間はBatchNormalization(momentum=0.8)を利用している。
def build_generator(self):
n_colors=1
model = Sequential()
model.add(Dense(196, input_dim=self.latent_dim))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Reshape((7,7,4)))
model.add(Conv2DTranspose(16, (5, 5), activation='relu', strides=2, padding='same'))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2DTranspose(64, (5, 5), activation='relu', strides=2, padding='same'))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(n_colors,(5, 5), activation='tanh', strides=1, padding='same'))
model.add(Reshape(self.img_shape))
model.summary()
以下の部分がConditional-GANの重要な部分です。すなわち、乱数で生成されたnoise以外にlabelを入力として追加しています。
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
そして、Embedding関数により、出力のテンソルの形状をモデルの出力になるように合わせていますが、このことは以下を実行してみると、出力が(1,100)になることからわかります。
from keras.layers import Input, Embedding
from keras.layers import Flatten
from keras.models import Model
import numpy as np
latent_dim = 100
num_classes = 10
noise = Input(shape=(latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(num_classes, latent_dim)(label))
mod = Model(label, label_embedding)
mod.summary()
test_input = np.zeros((1))
print(f'output shape is {mod.predict(test_input).shape}')
以下をみるとテンソル演算の様子がわかると思います。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 1) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 1, 100) 1000
_________________________________________________________________
flatten_1 (Flatten) (None, 100) 0
=================================================================
Total params: 1,000
Trainable params: 1,000
Non-trainable params: 0
_________________________________________________________________
output shape is (1, 100)
【参考】
・python - Keras: Understanding the role of Embedding layer in a Conditional GAN
discriminatorについて
こちらも考え方は同様で、中間はConv2Dを使っている。ここで、この場合もstrides=2を使うとMaxpoolingと同じような効果が得られるが、得られる画像の綺麗さは落ちるような気がする。ということで、以下のような構成にしました。
def build_discriminator(self):
model = Sequential()
model.add(Dense(784, input_dim=np.prod(self.img_shape)))
model.add(Reshape((28,28,1)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, np.prod(self.img_shape))(label))Ge
flat_img = Flatten()(img)
model_input = multiply([flat_img, label_embedding])
validity = model(model_input)
return Model([img, label], validity)
上に比べると、改善しました。

全体コードは以下に置きました
・DCGAN-Keras/CGAN-Keras/cgan_impl.py
・Cifar10が学習できるようにする
コードは以下に置きました。
・DCGAN-Keras/CGAN-Keras/cgan_impl4cifar.py
今回は上記のMNISTとCifar10の入出力の差分を吸収します。
つまり、Generatorを以下のとおりにしました。
基本はほぼ似ていますが、Cifar10は収束性が悪く、Activation('tanh')を使っています。また、最初の部分を除いてBatchNormalization(momentum=0.8)を除きました。
def build_generator(self):
n_colors=self.channels
model = Sequential()
model.add(Dense(1024, input_dim=self.latent_dim))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation('tanh'))
model.add(Reshape((8,8,16)))
model.add(Conv2D(16, (3, 3), activation='tanh', strides=1, padding='same'))
#model.add(BatchNormalization(momentum=0.8))
model.add(Conv2DTranspose(128, (3, 3), activation='tanh', strides=2, padding='same'))
#model.add(BatchNormalization(momentum=0.8))
model.add(Conv2DTranspose(64, (3, 3), activation='tanh', strides=2, padding='same'))
#model.add(BatchNormalization(momentum=0.8))
model.add(Conv2DTranspose(n_colors,(3, 3), activation='tanh', strides=1, padding='same'))
#model.add(BatchNormalization(momentum=0.8))
print('generator')
model.summary()
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
Discriminatorは以下の通りです。
def build_discriminator(self):
n_colors=self.channels
model = Sequential()
model.add(Dense(3072, input_dim=np.prod(self.img_shape)))
model.add(Reshape(self.img_shape))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
print('discriminator')
model.summary()
img = Input(shape=self.img_shape)
print(img.shape)
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, np.prod(self.img_shape))(label))
flat_img = Flatten()(img)
model_input = multiply([flat_img, label_embedding])
validity = model(model_input)
return Model([img, label], validity)
上記のコードで一応最初に示したような画像が得られました。今回は100000epoch回しています。もっと回せばよりよくなりそうですが、。。。今回はやりません。
画像出力コード
def generate(self, epoch):
r, c = 10, 10
noise = np.random.normal(0, 1, (r * c, 100))
sampled_labels = np.arange(0, 100).reshape(-1, 1)
for k in range(0,100000,5000):
print('k',k)
gen_weights=k
self.generator.load_weights('./gen_images_cgan/weights/generator_%d.h5' % gen_weights)
for i in range(100):
sampled_labels[i]=i%10
gen_imgs = self.generator.predict([noise, sampled_labels])
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c,figsize=(16,16))
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(np.clip(gen_imgs[cnt,:,:,:],0,1.))
if i==0:
axs[i,j].set_title("Digit: %d" % sampled_labels[cnt])
axs[i,j].axis('off')
cnt += 1
fig.savefig("./gen_images_cgan/%d_%d.png" % (gen_weights,epoch))
plt.close()
上記のコードで10x10の出力が得られます。すなわち、カテゴリごとに縦に並んでいます。
すなわち、条件によって0~9までのカテゴリごとに出力されるというわけです。
今回はやっていませんが、縦には乱数の値を整理して与えればまた前回のように縦にも何らかの変化を制御できると思われます。
つまり、ここも二次元目の条件(カテゴリ内でも変化が見える)とすることも可能だと考えています。これについては近日中に分かりやすいデータで記事にしたいと思います。
まとめ
・CGAN-Kerasで遊んでみた
・MNISTの出力画像の精度を改善した
・Cifar10に応用してカテゴリ毎画像出力できた
今後以下を実施します。
・第二の未知カテゴリで画像出力を実施する
・複数次元のカテゴリで制御する