主双対アルゴリズム1を使用して LASSO (least absolute shrinkage and selection operator) 回帰を実装してみた.
扱う問題
\min_{w}{\frac1n\|Xw-y\|_1 + \alpha\|w\|_1}
ここで $X\in\mathbb{R}^{n\times m},\ y\in\mathbb{R}^n$ は入力データセット,$w\in\mathbb{R}^m$ は決定変数,$\alpha$ は正則化パラメータである.
\|w\|_1 = \max_{-1\leq p\leq1}\left<w, p\right>
より,先の最適化問題は,
\min_w{\max_{-1 \leq (p, q) \leq 1}{\frac1n\left<Xw-y, q\right> + \alpha\left<w, p\right>}}
とかける.
主双対アルゴリズム
近接点法を用いて交互に最小化・最大化問題を解く.
\left\{
\begin{align}
&w^{k+1} = \mathop{\mathrm{arg~min}}\limits_{w}{\left\{\frac1n\left<Xw-y, q^k\right> + \alpha\left<w, p^k\right> + \frac12\|w - w^k\|_X^2\right\}}\\
&\bar{w}^{k+1} = 2w^{k+1} - w^k\\
&(p^{k+1}, q^{k+1}) = \mathop{\mathrm{arg~max}}\limits_{-1 \leq (p, q) \leq 1}{\left\{\frac1n\left<X\bar{w}^{k+1}-y, q\right> + \alpha\left<\bar{w}^{k+1}, p\right> - \frac12\|(p, q) - (p^k, q^k)\|_Y^2\right\}}
\end{align}
\right.
ここで,
K = \left(\frac1nX^\top\hspace{-1pt}, \alpha I\right)^\top\hspace{-1pt}\\
\|x\|_X^2 = \left<x, T^{-1}x\right>\\
T = \mathrm{diag}(\tau)\quad \mathrm{where}\quad \tau_j=\frac{1}{\sum_{i}|K_{i,j}|^{2-\beta}}\\
\|y\|_Y^2 = \left<y, \Sigma^{-1}y\right>\\
\Sigma = \mathrm{diag}(\sigma)\quad \mathrm{where}\quad \sigma_i=\frac{1}{\sum_{j}|K_{i,j}|^{\beta}}
である.これより,更新式は
\left\{
\begin{align}
&w^{k+1} = w^k - T\left(\frac1nX^\top\hspace{-1pt}q^k + \alpha p^k\right)\\
&\bar{w}^{k+1} = 2w^{k+1} - w^k\\
&(p^{k+1}, q^{k+1}) = \mathrm{proj}_{[-1, 1]}\left((p^k, q^k) + \Sigma\left(\alpha\bar{w}^{k+1}, \frac1n(X\bar{w}^{k+1} - y)\right)\right)
\end{align}
\right.
となる.
ソースコード
Python で実装.
- MacOS Mojave : 10.14.3
- Python : 3.7.3
- numpy : 1.16.4
ソースコードや実行した notebook は Github に.
from typing import Tuple, List
import numpy as np
from tqdm import trange
class Lasso:
"""
Lasso regression model using the preconditioned primal dual algorithm
"""
def __init__(self,
alpha: float = 1.0,
beta: float = 0.5,
max_iter: int = 1000,
extended_output: bool = False):
"""
Parameters
----------
alpha : float
A regularization parameter.
beta : float in [0.0, 2.0]
A parameter used in step size.
max_iter : int
The maximum number of iterations.
extended_output : bool
If True, return the value of the objective function of each iteration.
"""
np.random.seed(0)
self.alpha = alpha
self.beta = beta
self.max_iter = max_iter
self.extended_output = extended_output
self.coef_ = None
self.objective_function = list()
def _step_size(self, X: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
n_samples, n_features = X.shape
abs_X = np.abs(X)
tau = np.sum(abs_X ** self.beta, axis=0)
tau += self.alpha ** self.beta
tau = 1 / tau
sigma = np.empty(n_samples + n_features, dtype=X.dtype)
sigma[:n_samples] = np.sum(abs_X ** (2 - self.beta), axis=1)
sigma[n_samples:] = self.alpha ** (2 - self.beta)
sigma = 1. / sigma
return tau, sigma
def fit(self, X: np.ndarray, y: np.ndarray) -> None:
"""
Parameters
----------
X : array, shape = (n_samples, n_features)
y : array, shape = (n_samples, )
"""
n_samples, n_features = X.shape
n_samples_inv = 1 / n_samples
bar_X = X * n_samples_inv
bar_y = y * n_samples_inv
tau, sigma = self._step_size(bar_X)
# initialize
res = np.zeros(n_features, dtype=X.dtype)
dual = np.zeros(n_samples + n_features, dtype=X.dtype)
dual[:n_samples] = np.clip(-sigma[:n_samples] * y * n_samples_inv, -1, 1)
# objective function
if self.extended_output:
self.objective_function.append(
np.sum(np.abs(bar_y)) + self.alpha * np.sum(np.abs(res))
)
# main loop
for _ in trange(self.max_iter):
w = res - tau * (bar_X.T.dot(dual[:n_samples]) + self.alpha * dual[n_samples:])
bar_w = 2 * w - res
dual[:n_samples] = dual[:n_samples] + sigma[:n_samples] * (bar_X.dot(bar_w) - bar_y)
dual[n_samples:] = dual[n_samples:] + sigma[n_samples:] * bar_w * self.alpha
dual = np.clip(dual, -1, 1)
res = w
if self.extended_output:
self.objective_function.append(
np.sum(np.abs(bar_X.dot(w) - bar_y)) + self.alpha * np.sum(np.abs(res))
)
self.coef_ = res
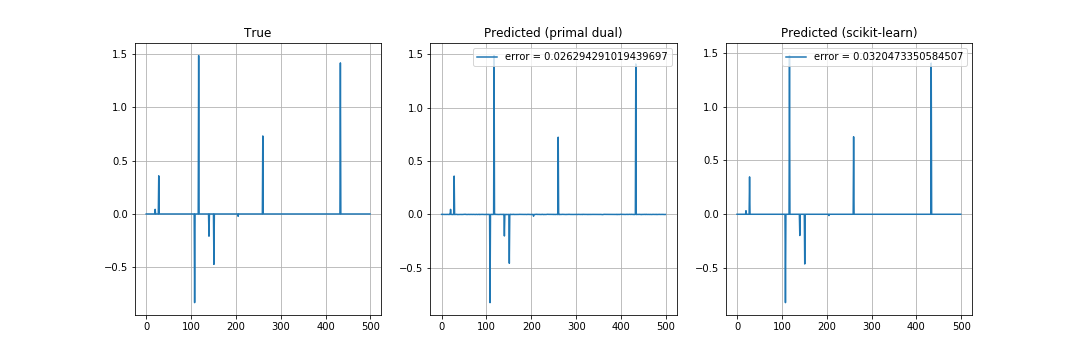
実行結果.
$X,\ w$ を乱数で与え,$w$ の復元を見ている.復元誤差 (error) は $\alpha$ に依存するが,実装した Lasso は収束が遅く scikit-learn のが良さそう.
-
Thomas Pock and Antonin Chambolle 2012 "Diagonal preconditioning for first order primal-dual algorithms in convex optimization" 2011 International Conference on Computer Vision https://ieeexplore.ieee.org/abstract/document/6126441 ↩