はじめに
Alibaba Cloudから2025年4月28日にリリースされたQwen3をMacBook Air M4上のローカル環境で動作させます。
Qwen3は、MoEモデルとDenseモデルがありますが、今回は小パラメータのモデルが用意されているDenseモデルの「Qwen3-8B」「Qwen3-14B」を以下の実行環境で試しました。
実行環境
- MacBook Air M4
- CPU / GPU:10コア
- メモリ:32GB
- LM stadio:0.3.14
- 量子化:Q4_K_M
- GPUオフロード:最大値
Qwen3の導入
詳しい導入方法は割愛しますが、LM stadioのModel Searchから「Qwen3」を検索して、お好きなパラメータのモデルをダウンロードしてください。
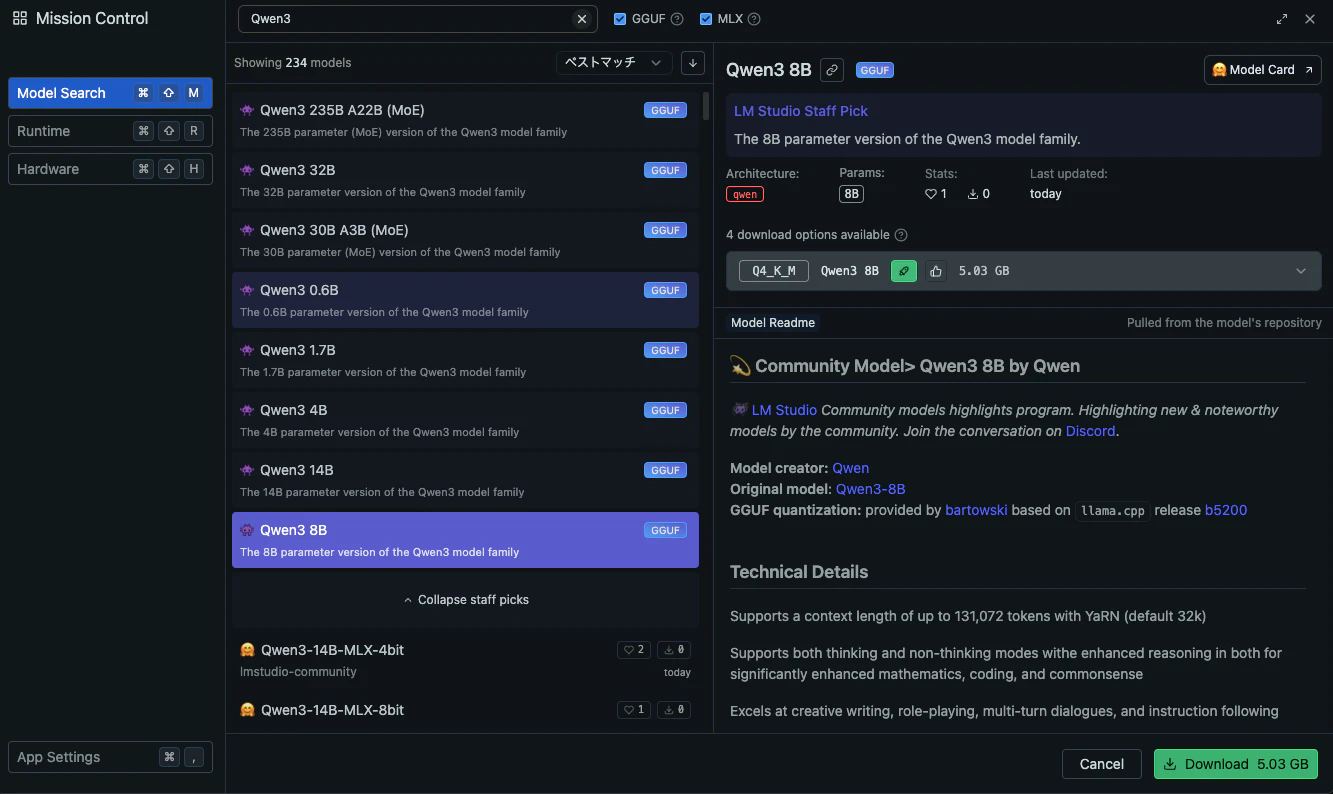
モデルがダウンロードできたら、Load Modelで実行します。

Qwen3の動作確認
Qwen3はハイブリッド推論モードがサポートされているので、「思考モード」と「非思考モード」どちらも試していきます。
Qwen3-8B
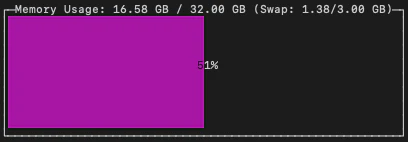
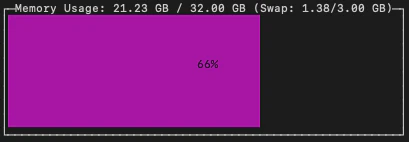
モデルをロードした時点で使用中のメモリが5GBほど増えました。
■メモリ使用量(モデルロード前)
■メモリ使用量(モデルロード後)
GPUオフロードしているモデル層の数を最大にしていたため、回答中のGPU使用率は100%になりました。
■回答前

■回答時

非思考モード
非思考モードにするにはプロンプトの先頭に”/no_think”とつけるだけです。
ストロベリー問題を質問しましたが、間違えています。

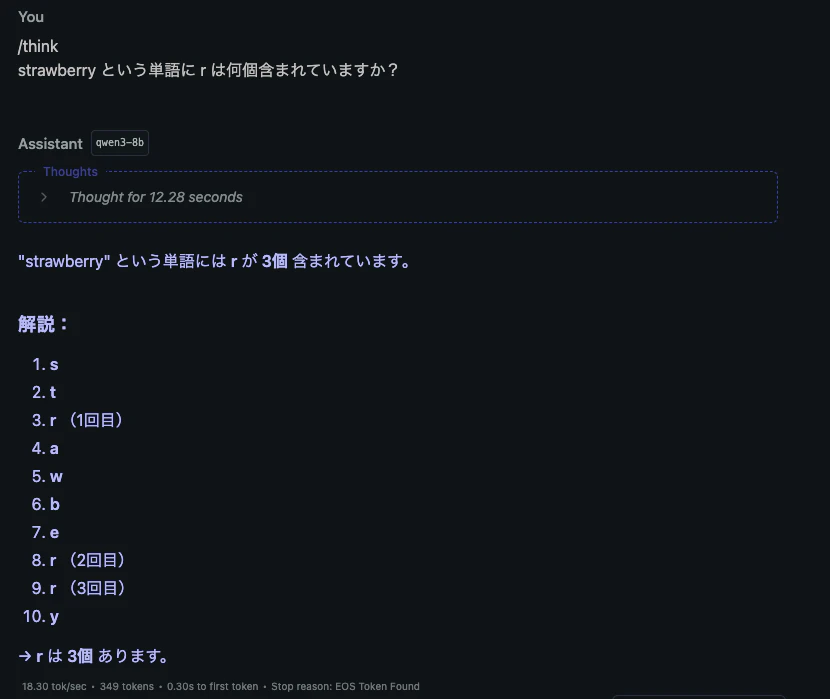
思考モード
思考モードにするにはプロンプトの先頭に”/think”とつけるだけです。
思考モードでは、ストロベリー問題を見事に正解してますね。
Qwen3-14B
モデルをロードした時点で使用中のメモリが7GBほど増えました。
GPU使用量はQwen3-8Bをロードした時より、2GBほど増えてますね。
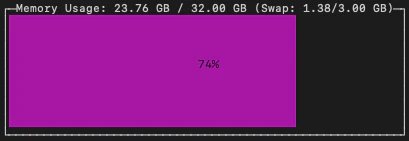
Qwen3-8B同様で回答中のGPU使用率は100%です。
非思考モード
途中不正解かと思いましたが、回答確認をして間違えに気づきましたね。
Qwen3-8Bと違い非思考モードでも見事正解してます。

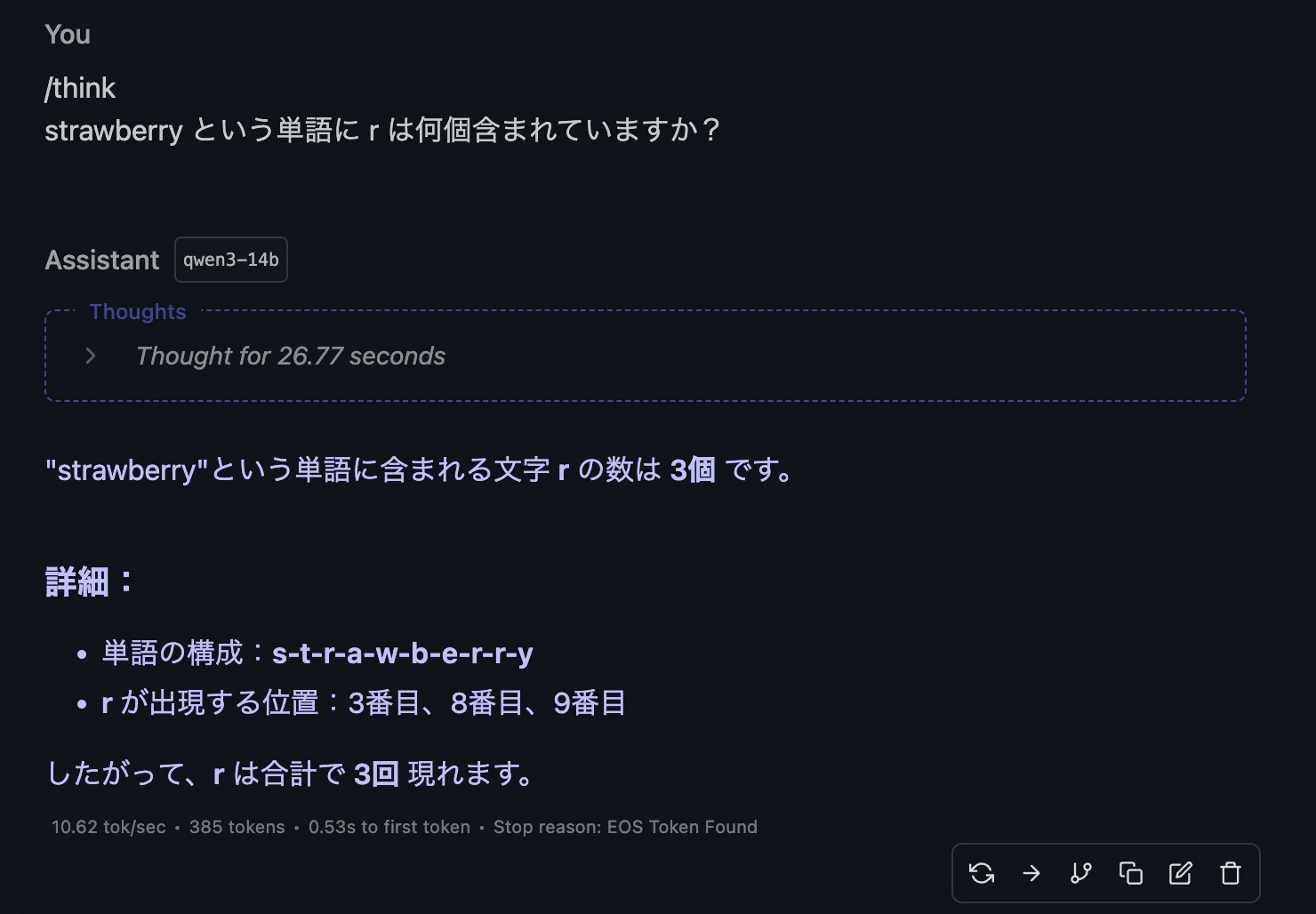
思考モード
こちらは、当たり前のように正解してます。
感想
8B,14Bと比較的小さなパラメータのモデルでもストロベリー問題が解けるようになっており驚きです。
使用した感じでは、日本語能力、コーディング精度ともに高く感じます。
回答速度については、8Bでは18tok/secほど出ており十分使える速度に感じます。
14Bでは10tok/secほどで、使うにしてはやや遅く感じます。
特に思考モードではかなり遅く感じてしました。
MacBook Air M4で実際に使えるのは14Bくらいまでな気がします。
気が向けば、今度はMoEモデルの「Qwen3-30B-A3B」を試してみたいと思います。