非常に簡易的な操作で機械学習のモデルを生成できるGoogleの「AutoML Vision」を試してみました。
AutoML Vision
https://cloud.google.com/vision/automl/docs/?hl=ja
コンソールからポチポチと画像をアップロードして、ラベルを付けるだけで、あとは勝手に学習してくれるという素敵なシステムです。
猫を分類したり、魚を分類したり、二郎を分類したりするのが流行りだそうですが、娘が毎週見ている「快盗戦隊ルパンレンジャーVS警察戦隊パトレンジャー」の登場人物をAIで分類できたら「パパかっこいい!」となるのではないかということで、こちらにチャレンジしてみました。
かざすAI図鑑アプリ「LINNÉ LENS」リリース(特許出願中) 第一弾は約4,000種、日本の水族館にいる生き物の9割に対応
https://www.value-press.com/pressrelease/206311
ラーメン二郎とブランド品で AutoML Vision の認識性能を試す
https://cloudplatform-jp.googleblog.com/2018/03/automl-vision-in-action-from-ramen-to-branded-goods.html
画像収集
機械学習で一番大変なのは画像収集なのではないか? とやってみて分かりました。「AutoML Vision」では1ラベルにつき100枚以上、数百枚の画像を推奨しているようでしたが、100枚以下でも機能している事例を読みましたので、今回は1キャラクター50枚を目処にしました。
画像検索から拾ってくるのが定番のようですので、ヤフーとグーグルの画像検索からポチポチ拾っていきました。スクリプトを書いて自動化せよと怒られそうでしたが、「50枚くらいならいけるか・・・」という誘惑に負けました。
拾ってきた画像はサイズも形式もバラバラです。後処理で、複数の人物が同じ画像に収まっているものは、機械学習の妨げになるのではないかということで、トリミングを施しました。
ちなみに今回分類したのは以下の7名です。
登場人物
・夜野 魁利(やの かいり) / ルパンレッド
・宵町 透真(よいまち とおま) / ルパンブルー
・早見 初美花(はやみ うみか) / ルパンイエロー
・朝加 圭一郎(あさか けいいちろう) / パトレン1号
・陽川 咲也(ひかわ さくや) / パトレン2号
・明神 つかさ(みょうじん つかさ) / パトレン3号
・高尾ノエル(たかお のえる) / ルパンエックス / パトレンエックス
執事のおっさんも入れておけば良かった・・・。
それぞれ50枚ずつなので合わせて350枚の画像を用意しました。
AutoML Visionのセットアップ
Google Cloudのアカウントは持っている前提で、以下からプロジェクトを作成(既存のプロジェクトでも問題ないです)。
次に課金を有効に。
「AutoML Vision」のAPIを有効化します。
以上だったような、もう少し手続きがあったような・・・。
機械学習していくぞ
以下のURLから「AutoML Vision」のコンソールが開きます。
中に「Dataset」というものと「Model」というものが見れます。
・Dataset 画像ファイルにラベルを付けたものの集合体
・Model Datasetを機械学習にかけて学習させたもの
まずDatasetを作成し、それを機械学習させてModelを作ります。そのModelにプログラムなどから分類したい画像を渡して、その結果を取得します。
データセットを作る
以下のURLからデータセットを新規作成できます。
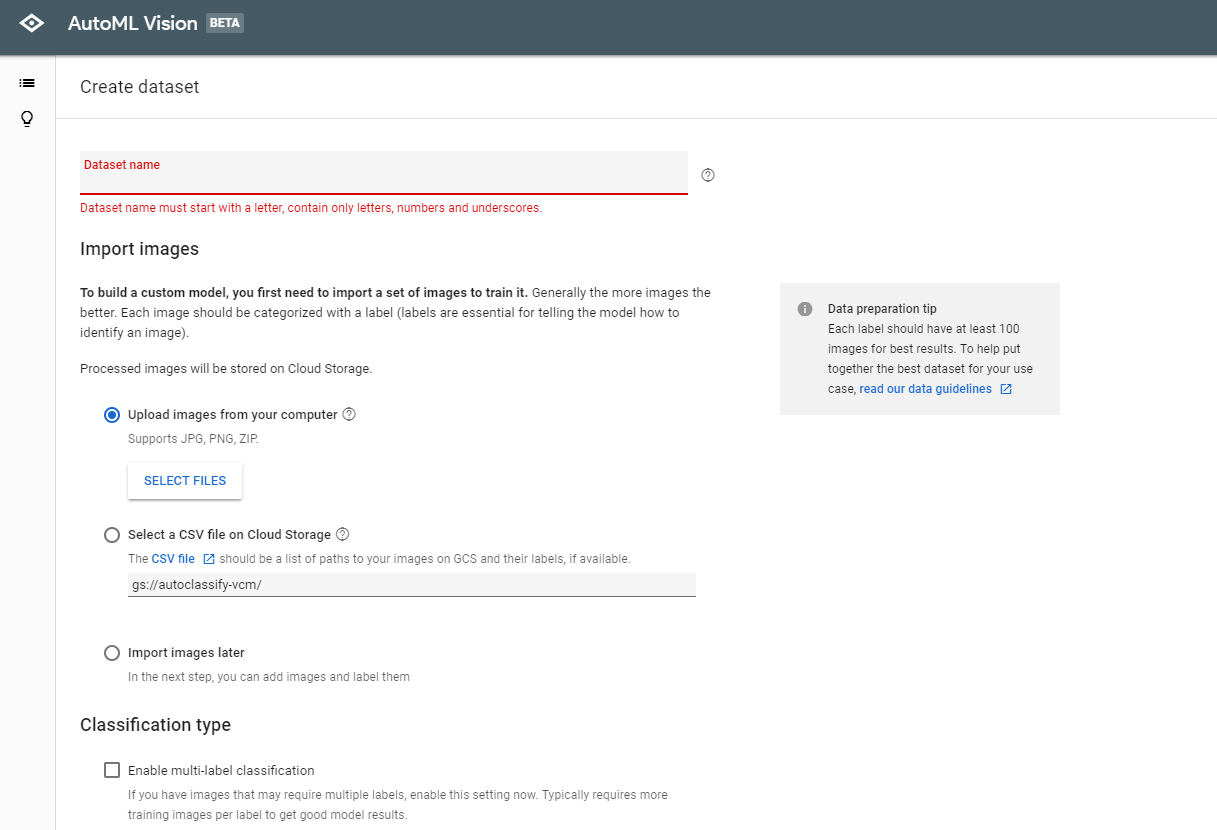
Dataset nameは好きな名前を付けてください。
画像のアップ方法はPCからJPG,PNG,ZIPでアップロードする、CSVを使ってアップロードするなどの方法があります。
Classification typeでは画像に複数のラベルを付けるか否か、という選択がありますが、現状では1画像には1枚のラベルというのが効果的だと書かれています。
画像のアップが終わったら、ラベルを付けていきます。
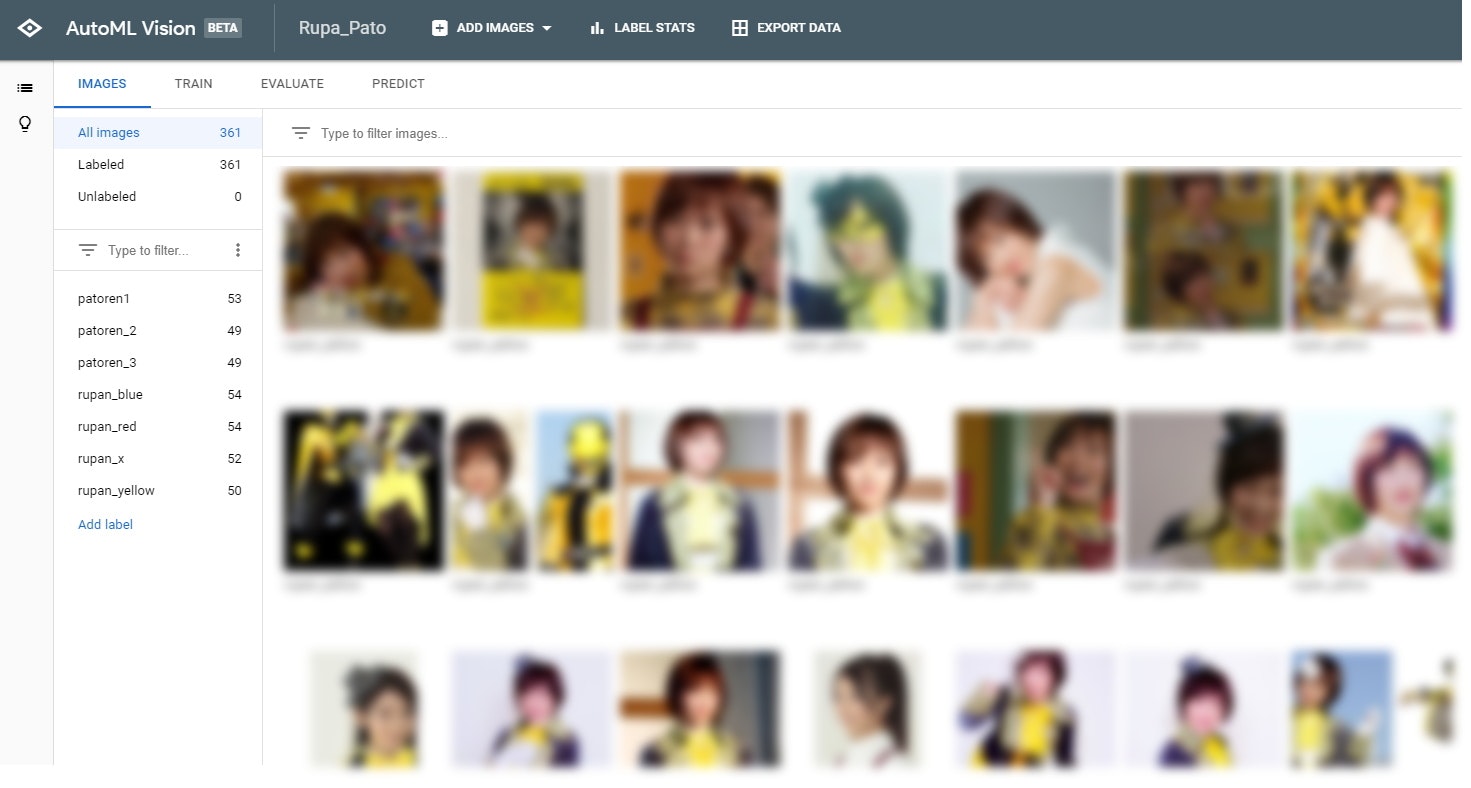
UIはGoogle Photoに似てますね。
左側に「Add Label」というリンクがあるので、ここから使いたいラベルを追加していきます。それから、画像をクリックして、それぞれの画像にラベルを付けます。ラベルはRESTなどで叩いた際の戻り値になってきますので、分かりやすいものを付けておいた方が良いです。
モデルを作る
データセットを用意したら、「TRAIN」というタブを開き「Train New Model」をクリックします。ウインドウが開くので、モデルに名前を付けて、「START TRAINING」をクリックすると学習が始まります。
今回は画像360枚、7つのラベルを設定して学習を行いました。所要時間は1時間程度だったと思います。完了したらEVALUATEのタブから結果を確認できます。
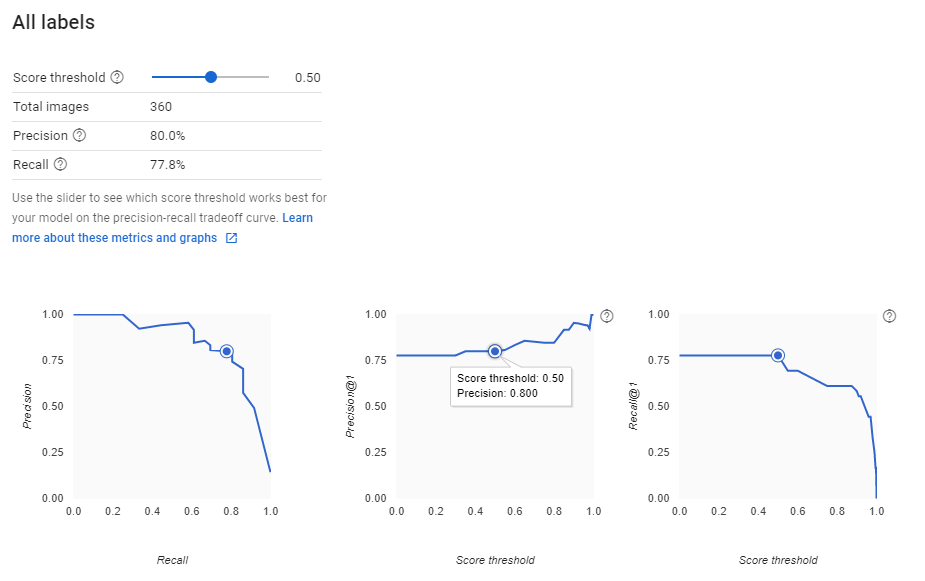
幾つかの指標があります。
・Precision(適合率) 正と判断したデータが、実際に正である割合
・Recall(再現率) 正であるデータが、正と判断された割合
・Score threshold(閾値)
PrecisionとRecallはいずれも高い割合の方がモデルの精度が高いことを示します。ただし、トレードオフの関係にあり、PrecisionとRecallがいずれも高い数値を出す、Score thresholdの数字を探る必要があります(スライダーを動かすだけで簡単にチェックできます)。コンソールやAPIからアクセスする際にも、閾値を設定することになりますので、ここでちゃんとチェックしておきましょう。
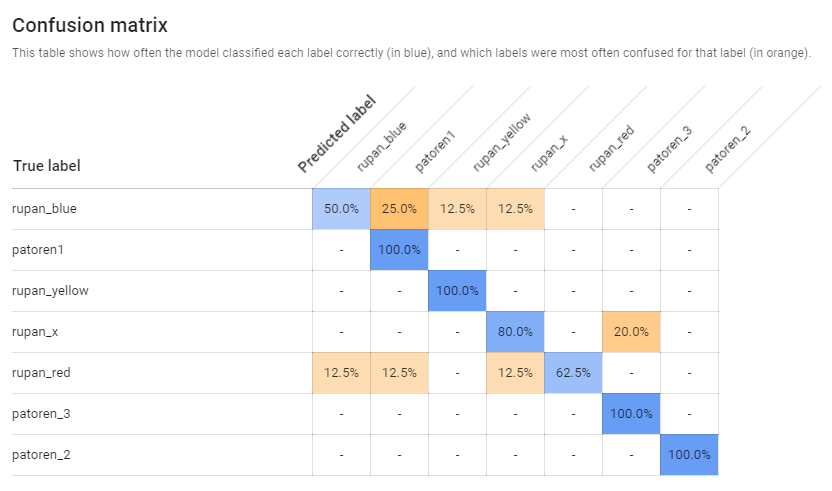
ちなみにこちらはラベル毎の結果。上手くいけば、左上から右下に、斜めに適合率の高い青い数字が出てくるはずです。この結果からはルパンブルーとルパンレッドはなかなか難しかったということが分かります。
コンソールで結果を楽しんでみる
モデルが完成したら「PREDICT」のタブから、簡単に機械学習の結果をチェックできます。
こちらの「UPLOAD IMAGES」のボタンを押すと画像選択画面になり、アップロードした画像を、先程作成したモデルで分類して結果を教えてくれます。

検知したラベルと、その精度を返してくれます。
Pythonのコードも例示されていて、もちろんAPIから叩くこともできます。こちらの方法は追って紹介したいと思います。
やってみて分かったこと
簡単すぎてびっくり
ほぼ機械学習デビューで、AutoMLデビューだったのですが、簡単すぎてびっくりしました。コンソールを使って画像をぽちぽちアップして、コンソールから結果を確認する、これだけであればノンプログラマーでも支障なく出来そうです。(その後、Pythonから結果を取得するのはなかなか苦労がありましたが・・・)
データセット大事
みんなが言うことですがデータ作りがとても大事で、これで精度が大いに変わります。
今回一番の反省点は、ヒーローの変身前と変身後のデータをごっちゃにしてしまったこと。今回はデータ量が少なかったですし、「快盗戦隊ルパンレンジャーVS警察戦隊パトレンジャー」は色が似通ってたりするので、見分けるのは難しいようでした。出来上がったモデルでも、変身前は大方判別できましたが、変身後はかなり間違える・・・という状態です。次回やるなら、変身前、変身後で計14ラベルでやるべきかなと思いました。
この辺のデータ作り、ラベル作りのノウハウはそれなりにありそうですね。
とにかくトライ
「百聞は一見に如かず」という言葉がありますが、実地で試してみると分かることが多いよね、と思いました。言葉や用語からして機械学習は難しそうというイメージを持っていた自分ですが、試して、体験しながら、言葉の意味も多少は理解できたように思います。具体的なユースケースがあまり思い付けてないのですが、触ったところで、多少なりともアイデアも出てきました。
あと楽しんでやれるテーマが必要だなあと。二郎を分類した人はきっと楽しかっただろうし、自分も「子供に凄い!」と言われたいというのが多少モチベーションになってデータ作りもできたので、ここって大事だよなあと改めて思いました。
では。
快盗戦隊ルパンレンジャーVS警察戦隊パトレンジャー
http://www.tv-asahi.co.jp/lvsp/