本記事内容サマリー
- 為替のデータをクラスタリングしてみました。
- k-means, ユークリッド距離 を用いました。
- 上位足(より長い時間軸の)データを組み合わせると有用そう。
- 上位足を用いると、ラベル(利食い:1、損切り:−1、保有時間による決済:0)の割合の偏りが良化した。
開発環境
- Colaboratory
- scikit-learn
データ準備
2018.01 ~ 2019.04 の USD/JPY を使用し、
5分足での移動平均線のゴールデンクロスのエントリーポイントをサンプルデータとしました。(2482 データ)
- 特徴量:
- エントリーポイント前の約3時間分のデータ(ohlc)
- RSI
ラベリング
ラベル付けは、以下のルールで行いました。
| Result | Label |
|---|---|
| Profit | 1 |
| Loss | -1 |
| 保有時間による決済 | 0 |
| 今回は、大体3等分されるように損切りと利食いのラインを設定しました。 |
クラスタリング
期待した結果
以下のグラフの様に、クラスタ毎に”利食い”/”損切り”/”保有時間による決済”がそれぞれキレイに分かれることを期待しました。
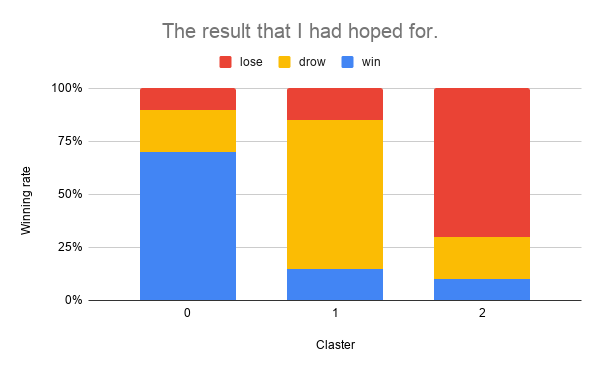
これだと、クラスタ2の場合はダマシと判断して、トレードを見送ることができますね。
結果
scikit-learn の TimeSeriesKMeans を用いてクラスタリングし、各クラスタのラベルの割合を図示し、勝率順にソートしました。
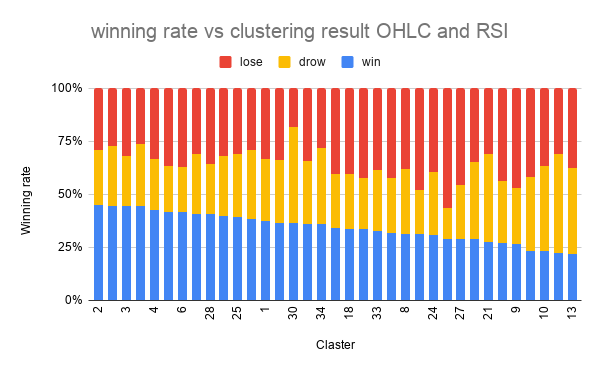
いまいち。。
勝率最大のクラスタで、45%、最小のクラスタで、22% でした。
元がほぼ3等分(33%)なので、少しは分けれてはいそうですが、もう少しキレイに分かれて欲しいところです。
上位足を追加
改善を目指し、以下のより長い時間足の情報を特徴量に加えることにしました。
- 30分足でオシレーター系のインジケーター
- 2時間足でトレンドフォロー型のインジケーター
その結果が以下です。
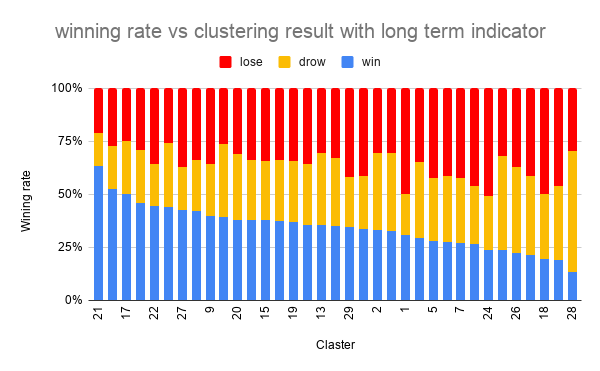
勝率最大のクラスタで、63%、最小のクラスタで、14% でした。
上位足の情報を加えることで、大分良化しました。
上位足の情報が有用であることが改めて確認できたので良かったのではないでしょうか。
これくらいの結果であれば、ダマシを回避するのは難しそうですが、ポジションの数量の調整には使えそうだと個人的には思いました。
記事を読んでいただきありがとうございました。