本記事の目的
ガウス過程回帰においてガウス分布がどのように機能しているのか、という性質を明らかにすることと、予測において必要な条件付き多次元正規分布の導出の全体をまとめています。
ガウス過程とは
無限次元正規分布のことです。それを回帰に用いる場合は特にガウス過程回帰と呼ばれます。数学的に記載すると、
任意の$N \in \mathbb{N}$に対し、$(\boldsymbol{x_1}, \boldsymbol{x_2}, ...,\boldsymbol{x_N})$について対応する出力 $\boldsymbol{y} = (y_1, y_2, ..., y_N)$ の同時分布が多変量ガウス分布に従うとき、$\boldsymbol{x}$ と $\boldsymbol{y}$ の関係はガウス過程に従う。
となります。
ガウス過程回帰においてはカーネルのハイパーパラメータは存在しますが、学習するパラメータが存在しません。そのためデータに強く適合し辛いという特徴がありますが、表現能力はその他の手法のほうがあると考えられます。
ガウス過程は各点次元のガウス分布なので、次図のように各点 $x_i$に対して平均と分散を用いて予測値に対する確信度を見ることができます。
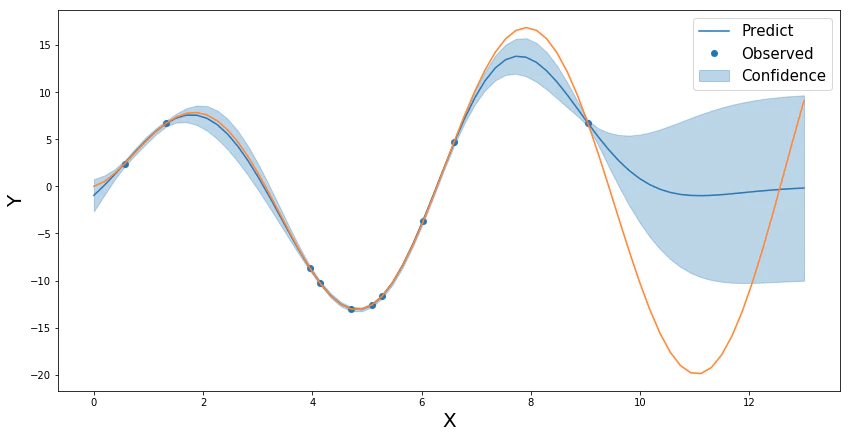
この特徴は応用上有効で、確信度と判明している最大値のバランスをとって次の最適値を探索するというベイズ最適化へと用いられています。
ガウス分布という仮定が作用する部分
まずガウス過程回帰におけるガウス分布の役割を明らかにします。
ガウス過程回帰は非線形関数の重み付き和で次のように表せる線形回帰です。${\hat{y}} = w_0 \phi_0(\boldsymbol{x}) + w_1 \phi_1(\boldsymbol{x}) + \ldots + w_H \phi_H(\boldsymbol{x})$
これをベクトル表記したものが下記です。
\begin{pmatrix}
\hat{y_{1}} \\
\hat{y_{2}} \\
\vdots \\
\hat{y_{N}}
\end{pmatrix}
=
\begin{pmatrix}
\phi_0(\boldsymbol{x_1}) & \phi_1(\boldsymbol{x_1}) & \ldots & \phi_H(\boldsymbol{x_1}) \\
\phi_0(\boldsymbol{x_2}) & \phi_1(\boldsymbol{x_2}) & \ldots & \phi_H(\boldsymbol{x_2}) \\
\vdots & & & \vdots \\
\phi_0(\boldsymbol{x_N}) & \phi_1(\boldsymbol{x_N}) & \ldots & \phi_H(\boldsymbol{x_N}) \\
\end{pmatrix}
\begin{pmatrix}
w_{0} \\
w_{1} \\
\vdots \\
w_{H}
\end{pmatrix}, \\
\begin{align}
\boldsymbol{\hat{y}}
= \boldsymbol{\Phi} \boldsymbol{w}.
\end{align}
この計画行列 $\boldsymbol{\Phi}$は入力$\boldsymbol{x}$が定まれば決まる定数行列なので、$\boldsymbol{w}$をガウス分布と仮定すると$\boldsymbol{\hat{y}}$はガウス分布になります。
これによって出力yの分布がパラメトリックに判明するので、そのパラメータを推測することで出力yの分布を特定できます。
この時、wの従う分布は次のように定義します。
\boldsymbol{w} \sim \boldsymbol{N}(\boldsymbol{0}, \lambda^2 \boldsymbol{I}).
以上を用いると、yの従うガウス分布の平均と期待値は次のように計算できます。
\begin{align}
\mu
&= \mathbb{E}[\boldsymbol{y}] = \mathbb{E}[\boldsymbol{\Phi} \boldsymbol{w}] = \boldsymbol{\Phi} \mathbb{E}[\boldsymbol{w}] = \boldsymbol{0}, \\
\Sigma &= \mathbb{E}[\boldsymbol{y} \boldsymbol{y}^T] - \mathbb{E}[\boldsymbol{y}]\mathbb{E}[\boldsymbol{y}]^T = \mathbb{E}[\boldsymbol{y} \boldsymbol{y}^T] =
\mathbb{E}[(\boldsymbol{\Phi} \boldsymbol{w}) (\boldsymbol{\Phi} \boldsymbol{w})^T] \\
& =
\lambda ^2 \boldsymbol{\Phi} \boldsymbol{\Phi}^T.
\end{align}
以上より、$\boldsymbol{y} \sim \boldsymbol{N}(\boldsymbol{0}, \lambda ^2 \boldsymbol{\Phi} \boldsymbol{\Phi}^T)$となるので、カーネルトリックを用いて $K = \lambda ^2 \boldsymbol{\Phi} \boldsymbol{\Phi}^T$と表すと、最終的に、
\boldsymbol{y} \sim \boldsymbol{N}(\boldsymbol{0}, \boldsymbol{K}).
と表せます。
非線形関数の重みに対してガウス分布を仮定することで出力yの分布がガウス分布となるので、解析的に分布のパラメータを計算することができるようになる。
これがガウス分布という仮定が効いてくる部分です。
さらに表現された分散はカーネルトリックによって非線形関数を特定しなくても計算することができます。その際に必要となるのはカーネルの設計のみで、ハイパーパラメータとしてはその部分のみを推定する必要があります。それによって過適合は抑えられています。
ガウス分布という仮定が作用する部分2
次は誤差に関するものです。先ほどの議論は誤差を考慮していませんでした。これもガウス分布という仮定が作用する部分になります。
誤差を含めるのは単純です。
y_n = f(\boldsymbol{x_n}) + \epsilon_n, \\
\epsilon_n \sim {N}(0, \sigma^2).
これによって目的値の確率分布を$p(\boldsymbol{y}|\boldsymbol{f}) = N(\boldsymbol{f}, \sigma^2 \boldsymbol{I})$と表せます。連鎖則とガウス分布と畳み込みによって、
\begin{align}
p(\boldsymbol{y}|\boldsymbol{X})
& = \int p(\boldsymbol{y, f}|\boldsymbol{X}) d\boldsymbol{f} = \int p(\boldsymbol{y}|\boldsymbol{f}) p(\boldsymbol{f}|\boldsymbol{X}) d\boldsymbol{f} \\
& = \int N(\boldsymbol{y}|\boldsymbol{f}, \sigma^2 \boldsymbol{I}) N(\boldsymbol{f}|\boldsymbol{\mu}, \boldsymbol{K}) d\boldsymbol{f}.
\end{align}
となるので、目的値の確率分布は
p(\boldsymbol{y}|\boldsymbol{X}) = \boldsymbol{N}(\boldsymbol{\mu}, \boldsymbol{K} + \sigma^2 \boldsymbol{I}).
と表せます。
これがガウス分布の仮定が作用する二つ目の部分です。
誤差にガウス分布を仮定することで、ガウス分布同士の畳み込みによって目的分布もガウス分布として再構成できます。
これよって解析的に解を求めることが出来ます。特に最終的な分布がガウス分布であればサンプリングが容易に行えます。この部分に対してはバリエーションがあり、誤差分布に関する仮定はガウス分布以外を選択することがあります。その場合はMCMC等の近似的な推論が必要になります。
ガウス分布の必要性のまとめ
以上をまとめると、ガウス過程においてガウス分布という仮定が作用するのは二つです。
- 非線形関数の重みをガウス分布とすることで、事後分布である予測分布をガウス分布として解析的に計算出来る。
- 誤差分布としてガウス分布を用いることで、誤差項を含めた予測分布をガウス分布として扱うことが出来る。
一点目は必須ですが、二点目は拡張されることがあります。
予測
基本的な理論部分において面倒臭さは予測の部分にあります。
なぜかというと重みwを消去してしまったので、線形回帰のように入力xに重みを作用させるという方法では出力値を出すことが出来なくなりました。
それは条件付き多次元正規分布によって解決できます。条件付き多次元正規分布が表記できれば、先ほどのカーネルトリックによる表記と対応付けることで予測分布を表現できます。
難しいのは、この条件付き多次元正規分布の計算が行間を読むことを前提で書かれていたり、若干の表記ミスがあったりすることです。本記事ではその部分を少し丁寧に説明します。
条件付き多次元正規分布
多次元正規分布を次のようにL次元とD-L次元に分割した時、
\begin{pmatrix}
\boldsymbol{x_1} \\
\boldsymbol{x_2}
\end{pmatrix}
\sim
\boldsymbol{N} \left(
\begin{pmatrix}
\boldsymbol{\mu_1} \\
\boldsymbol{\mu_2}
\end{pmatrix}
,
\begin{pmatrix}
\boldsymbol{\Sigma_{11}} & \boldsymbol{\Sigma_{12}} \\
\boldsymbol{\Sigma_{21}} & \boldsymbol{\Sigma_{22}}
\end{pmatrix}
\right),
その条件付き分布は次のように表せる。
p(\boldsymbol{x_2} | \boldsymbol{x_1}) = N(\boldsymbol{\mu_2} + \boldsymbol{\Sigma_{21} \boldsymbol{\Sigma_{11}^{-1}}} (\boldsymbol{x_1} - \boldsymbol{\mu_1}),
\boldsymbol{\Sigma_{22}} - \boldsymbol{\Sigma_{21} \boldsymbol{\Sigma_{11}^{-1}}} \boldsymbol{\Sigma_{12}}
).
道具
計算の際に次を用います。
- 対称行列の性質
\boldsymbol{\Sigma}^T = \boldsymbol{\Sigma} ,\\
(\boldsymbol{\Sigma}^{-1})^T = \boldsymbol{\Sigma}^{-1}.\\
- 転置の性質(列ベクトル)
\boldsymbol{x}^T \boldsymbol{\Sigma} \boldsymbol{y}
=
\boldsymbol{y}^T \boldsymbol{\Sigma}^T \boldsymbol{x}.
- シェーア補間行列
\boldsymbol{M} = (\boldsymbol{A} - \boldsymbol{B} \boldsymbol{D}^{-1} \boldsymbol{C})^{-1} ,\\
\begin{pmatrix}
\boldsymbol{A} & \boldsymbol{B} \\
\boldsymbol{C} & \boldsymbol{D}
\end{pmatrix} ^{-1}
=
\begin{pmatrix}
\boldsymbol{A}^{-1} + \boldsymbol{A}^{-1} \boldsymbol{B} \boldsymbol{M} \boldsymbol{C} \boldsymbol{A}^{-1} &
- \boldsymbol{A}^{-1} \boldsymbol{B} \boldsymbol{M} \\
- \boldsymbol{M} \boldsymbol{C} \boldsymbol{A}^{-1} & \boldsymbol{M}
\end{pmatrix}
.
事前計算
まず条件付き分布を整理します。
p(\boldsymbol{x_2} | \boldsymbol{x_1})
=
\frac{p(\boldsymbol{x_2}, \boldsymbol{x_1})}{p(\boldsymbol{x_1})}
= C(\boldsymbol{x_1})
p(\boldsymbol{x_2}, \boldsymbol{x_1}).
変数として作用する $\boldsymbol{x_2}$以外は定数として扱います。この $p(\boldsymbol{x_2}, \boldsymbol{x_1})$を $\boldsymbol{x_2}$について整理することで、対応するパラメータを求めます。
多変量ガウス分布は次のように表せますが、
p(\boldsymbol{x})
=
\frac{1}{(2\pi)^{D/2}|\Sigma|^{D/2}} \exp \left\{
-\frac{1}{2}(\boldsymbol{x} - \boldsymbol{\mu})^T \boldsymbol{\Sigma}^{-1}(\boldsymbol{x} - \boldsymbol{\mu})
\right\}.
今回重要なのは指数の肩の部分なので、それを書き下します。
\begin{align}
(\boldsymbol{x} - \boldsymbol{\mu})^T \boldsymbol{\Sigma}^{-1}(\boldsymbol{x} - \boldsymbol{\mu})
&=
\boldsymbol{x}^T \boldsymbol{\Sigma}^{-1} \boldsymbol{x}
- \boldsymbol{x}^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}
- \boldsymbol{\mu}^T \boldsymbol{\Sigma}^{-1} \boldsymbol{x}
+ \boldsymbol{\mu}^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}\\
&=
\boldsymbol{x}^T \boldsymbol{\Sigma}^{-1} \boldsymbol{x}
- 2 \boldsymbol{x}^T \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}
+ C\\
&=
\boldsymbol{x}^T \boldsymbol{A} \boldsymbol{x}
- 2 \boldsymbol{x}^T \boldsymbol{B}
+ C.\\
\end{align}
ここで、$\boldsymbol{A} = \boldsymbol{\Sigma}^{-1}$、 $\boldsymbol{B} = \boldsymbol{A} \boldsymbol{\mu}$ とおいています。
このように書き下し、$p(\boldsymbol{x_2} | \boldsymbol{x_1})$を同様の形式で表した際に対応を比較することで、パラメータ $\hat{\boldsymbol{\Sigma}}^{-1}, \hat{\boldsymbol{\mu}}$を求めます。
条件付き分布の計算
次に条件付き分布を同様に書き下していきます。
まず、計算のために
\boldsymbol{\Sigma}^{-1}
=
\begin{pmatrix}
\boldsymbol{\Sigma}_{11} & \boldsymbol{\Sigma}_{12} \\
\boldsymbol{\Sigma}_{21} & \boldsymbol{\Sigma}_{22}
\end{pmatrix} ^{-1}
=
\begin{pmatrix}
\boldsymbol{\Lambda}_{11} & \boldsymbol{\Lambda}_{12} \\
\boldsymbol{\Lambda}_{21} & \boldsymbol{\Lambda}_{22}
\end{pmatrix}.
とおきます。対応付けは後にシェーアの補間行列を用います。
\begin{align}
p(\boldsymbol{x_2} | \boldsymbol{x_1})
&=
\frac{p(\boldsymbol{x_2}, \boldsymbol{x_1})}{p(\boldsymbol{x_1})}
= C
p(\boldsymbol{x_2}, \boldsymbol{x_1}) \\
&=
C
\exp \left(
- \frac{1}{2}
\left\{
\begin{pmatrix}
\boldsymbol{x_1} - \boldsymbol{\mu_1} \\
\boldsymbol{x_2} - \boldsymbol{\mu_2}
\end{pmatrix} ^T
\begin{pmatrix}
\boldsymbol{\Lambda}_{11} & \boldsymbol{\Lambda}_{12} \\
\boldsymbol{\Lambda}_{21} & \boldsymbol{\Lambda}_{22}
\end{pmatrix}
\begin{pmatrix}
\boldsymbol{x_1} - \boldsymbol{\mu_1} \\
\boldsymbol{x_2} - \boldsymbol{\mu_2}
\end{pmatrix}
\right\}
\right)\\
&=
C
\exp \left(
- \frac{1}{2} \boldsymbol{L}(\boldsymbol{x_2})
\right),\\
\end{align}
指数の中の部分を書き下していきますが、$\boldsymbol{x_2}$に関係がない部分は定数として扱います。
\begin{align}
\boldsymbol{L}(\boldsymbol{x_2})
&=
(\boldsymbol{x_2} - \boldsymbol{\mu_2})^T \boldsymbol{\Lambda}_{22} (\boldsymbol{x_2} - \boldsymbol{\mu_2})
+ (\boldsymbol{x_2} - \boldsymbol{\mu_2})^T \boldsymbol{\Lambda}_{21} (\boldsymbol{x_1} - \boldsymbol{\mu_1}) \\
& \ \ \ \ + (\boldsymbol{x_1} - \boldsymbol{\mu_1})^T \boldsymbol{\Lambda}_{12} (\boldsymbol{x_2} - \boldsymbol{\mu_2})
+ (\boldsymbol{x_1} - \boldsymbol{\mu_1})^T \boldsymbol{\Lambda}_{11} (\boldsymbol{x_1} - \boldsymbol{\mu_1}) \\
&=
(\boldsymbol{x_2} - \boldsymbol{\mu_2})^T \boldsymbol{\Lambda}_{22} (\boldsymbol{x_2} - \boldsymbol{\mu_2})
+ 2 (\boldsymbol{x_2} - \boldsymbol{\mu_2})^T \boldsymbol{\Lambda}_{21} (\boldsymbol{x_1} - \boldsymbol{\mu_1}) + {C} \\
&=
\boldsymbol{x_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{x_2}
- \boldsymbol{x_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2}
- \boldsymbol{\mu_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{x_2}
- \boldsymbol{\mu_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2} \\
& \ \ \ \ + 2(
\boldsymbol{x_2}^T \boldsymbol{\Lambda}_{21} \boldsymbol{x_1}
- \boldsymbol{x_2}^T \boldsymbol{\Lambda}_{21} \boldsymbol{\mu_1}
- \boldsymbol{\mu_2}^T \boldsymbol{\Lambda}_{21} \boldsymbol{x_1}
- \boldsymbol{\mu_2}^T \boldsymbol{\Lambda}_{21} \boldsymbol{\mu_1} ) + C \\
&=
\boldsymbol{x_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{x_2}
- 2\boldsymbol{x_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2}
+ 2\boldsymbol{x_2}^T \boldsymbol{\Lambda}_{21}
(\boldsymbol{x_1} - \boldsymbol{\mu_1}) + C \\
&=
\boldsymbol{x_2}^T \boldsymbol{\Lambda}_{22} \boldsymbol{x_2}
- 2\boldsymbol{x_2}^T (\boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2}
- \boldsymbol{\Lambda}_{21}
(\boldsymbol{x_1} - \boldsymbol{\mu_1})) + C .\\
\end{align}
以上を先ほど書き下した指数の肩の部分と対応付けると、
\begin{align}
(\boldsymbol{x} - \boldsymbol{\mu})^T \boldsymbol{\Sigma}^{-1}(\boldsymbol{x} - \boldsymbol{\mu})
&=
\boldsymbol{x}^T \boldsymbol{A} \boldsymbol{x}
- 2 \boldsymbol{x}^T \boldsymbol{B}
+ C,\\
\end{align}
より、
\boldsymbol{\Lambda}_{22} = \boldsymbol{A} = \hat{\boldsymbol{\Sigma}}^{-1}, \\
\boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2}
- \boldsymbol{\Lambda}_{21}
(\boldsymbol{x_1} - \boldsymbol{\mu_1}) = \boldsymbol{B} = \hat{\boldsymbol{\Sigma}}^{-1} \hat{\boldsymbol{\mu}}.
従って、
\begin{align}
\hat{\boldsymbol{\Sigma}}^{-1}
&= \boldsymbol{\Lambda}_{22}, \\
\hat{\boldsymbol{\mu} }
&=
\boldsymbol{\Lambda}_{22}^{-1} (
\boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2}
- \boldsymbol{\Lambda}_{21}
(\boldsymbol{x_1} - \boldsymbol{\mu_1}) ) .
\end{align}
となります。
最後に$\boldsymbol{\Lambda}$ を $\boldsymbol{\Sigma}$ に戻して完成します。
求める必要があるのは、$\boldsymbol{\Lambda}_{21},\boldsymbol{\Lambda} _{22}$です。
\boldsymbol{\Sigma}^{-1}
=
\begin{pmatrix}
\boldsymbol{\Sigma}_{11} & \boldsymbol{\Sigma}_{12} \\
\boldsymbol{\Sigma}_{21} & \boldsymbol{\Sigma}_{22}
\end{pmatrix} ^{-1}
=
\begin{pmatrix}
\boldsymbol{\Lambda}_{11} & \boldsymbol{\Lambda}_{12} \\
\boldsymbol{\Lambda}_{21} & \boldsymbol{\Lambda}_{22}
\end{pmatrix}.
より、シェーアの補間行列を用いて、
\boldsymbol{\Lambda_{22}} =
\boldsymbol{M} = (\boldsymbol{\Sigma_{22}} - \boldsymbol{\Sigma_{21}} \boldsymbol{\Sigma_{11}}^{-1} \boldsymbol{\Sigma_{12}})^{-1},
\boldsymbol{\Lambda_{21}} =
- \boldsymbol{M} \boldsymbol{\Sigma_{21}} \boldsymbol{\Sigma_{11}}^{-1}.
と表せるので、それを$\hat{\boldsymbol{\Sigma}}^{-1} $、$\hat{\boldsymbol{\mu}}$ へ代入すれば
\hat{\boldsymbol{\Sigma}}^{-1} = \boldsymbol{\Lambda}_{22}
=
(\boldsymbol{\Sigma_{22}} - \boldsymbol{\Sigma_{21}} \boldsymbol{\Sigma_{11}}^{-1} \boldsymbol{\Sigma_{12}})^{-1},
\begin{align}
\hat{\boldsymbol{\mu}}
&=
\boldsymbol{\Lambda}_{22}^{-1} (
\boldsymbol{\Lambda}_{22} \boldsymbol{\mu_2}
- \boldsymbol{\Lambda}_{21}
(\boldsymbol{x_1} - \boldsymbol{\mu_1}) )\\
&=
\boldsymbol{\mu_2}
- \boldsymbol{\Lambda}_{22}^{-1}
\boldsymbol{\Lambda}_{21}
(\boldsymbol{x_1} - \boldsymbol{\mu_1}) \\
&= \boldsymbol{\mu_2} + \boldsymbol{M}^{-1} \boldsymbol{M}
\boldsymbol{\Sigma_{21}} \boldsymbol{\Sigma_{11}}^{-1}(\boldsymbol{x_1} - \boldsymbol{\mu_1}) \\
&= \boldsymbol{\mu_2} +
\boldsymbol{\Sigma_{21}} \boldsymbol{\Sigma_{11}}^{-1}(\boldsymbol{x_1} - \boldsymbol{\mu_1}).
\end{align}
となります。
以上により、
p(\boldsymbol{x_2} | \boldsymbol{x_1}) = N(\boldsymbol{\mu_2} + \boldsymbol{\Sigma_{21} \boldsymbol{\Sigma_{11}^{-1}}} (\boldsymbol{x_1} - \boldsymbol{\mu_1}),
\boldsymbol{\Sigma_{22}} - \boldsymbol{\Sigma_{21} \boldsymbol{\Sigma_{11}^{-1}}} \boldsymbol{\Sigma_{12}}
).
となることが示されました。
ガウス過程による予測のための計算
あとは条件付き多次元正規分布とグラム行列表記を関連付けるだけです。
上記の多次元正規分布の条件付き分布を導出できれば読み進めることは難しくないです。
まずは事前に得られたデータと推測するデータを分けて条件付き分布で表します。その際にグラム行列を用いると次のようになります。
\begin{pmatrix}
\boldsymbol{y} \\
\boldsymbol{y^*}
\end{pmatrix}
\sim
\boldsymbol{N}
\left(
0,
\begin{pmatrix}
\boldsymbol{K} & \boldsymbol{k_*} \\
\boldsymbol{k_*}^T & k_{**}
\end{pmatrix}
\right).
\begin{align}
\boldsymbol{k_*} &= (k(\boldsymbol{x^*}, \boldsymbol{x_1}),
k(\boldsymbol{x^*}, \boldsymbol{x_2}), \ldots,
k(\boldsymbol{x^*}, \boldsymbol{x_N}))^T ,\\
k_{**} &= k(\boldsymbol{x^*}, \boldsymbol{x^*}).
\end{align}
先ほど求めた条件付き正規分布を平均値0で用いると次のようになります。
p(\boldsymbol{y_2} | \boldsymbol{y_1}) = N(\boldsymbol{\Sigma_{21} \boldsymbol{\Sigma_{11}^{-1}}} \boldsymbol{y_1},
\boldsymbol{\Sigma_{22}} - \boldsymbol{\Sigma_{21} \boldsymbol{\Sigma_{11}^{-1}}} \boldsymbol{\Sigma_{12}}
).
グラム行列とこれら $\boldsymbol{\Sigma}$ の対応は下記なので、
\begin{pmatrix}
\boldsymbol{K} & \boldsymbol{k_*} \\
\boldsymbol{k_*}^T & k_{**}
\end{pmatrix}
=
\begin{pmatrix}
\boldsymbol{\Sigma}_{11} & \boldsymbol{\Sigma}_{12} \\
\boldsymbol{\Sigma}_{21} & \boldsymbol{\Sigma}_{22}
\end{pmatrix}.
この対応により、
p(\boldsymbol{y^*} | \boldsymbol{x^*}, \boldsymbol{x}, \boldsymbol{y})
=
\boldsymbol{N} (\boldsymbol{k_*}^T \boldsymbol{K}^{-1} \boldsymbol{y}, \ \
k_{**} - \boldsymbol{k_*}^T \boldsymbol{K}^{-1}\boldsymbol{k_{\ast}}).
となり、ガウス過程による予測を出力できます。
予測のための入力データ $\boldsymbol{x^*}$はグラム行列 $\boldsymbol{k_{\ast}}$ に反映され、既存のデータ $\boldsymbol{x}$はグラム行列 $\boldsymbol{K}$に反映されます。既存のデータ $\boldsymbol{y}$は期待値に反映されますが、分散には反映されません。
備考
一部書籍やネットの記事のみでは行間を読む必要がある部分を埋めたつもりです。
理解の共有や技術的な応用等を色々と議論できると嬉しいので、少しでも興味を持って頂けたらどんな内容でも連絡お待ちしております。
参考
以上、ミスや理解不足等あるかもしれませんが、その際は指摘して頂けると助かります。下記に参考とした書籍等を記載します。