本エントリの目的
この度,勉強を兼ねて,ライブラリを使わずにDeep Learning (ディープラーニング) を実装したので,ご紹介致します.言語はPythonです.
ただし,参考にした書籍があります.本エントリでは,その書籍の紹介と,その書籍に記載されたJavaコードを元に,Pythonで再実装したコードについて説明をします.
背景
最近のAIブームの火付け役として,ディープラーニングが注目を浴びていることは,今更ここで述べるほどのことではないと思います.最近この手の本が大量に出版されていることを鑑みても,その注目度の高さが容易に伺えます.
ただ,世の中皆が皆AIを専門に仕事をしているわけではありませんし,むしろそのような方は本当に一部の層に限定されます.多くの人は,
今ディープラーニングに直結した仕事をしているわけではないんだけど,近い将来AIがインフラとして導入されることを考えると無視もできないよなー.
という感覚を持っているのではないでしょうか.てなわけで,取り敢えず勉強してみるかと思う人が多いと思いますし,私もその1人です.
と思っていざ本を手に取ってみると,下記のタイプに二極化しているような傾向(あくまで傾向で,私がいい本を見逃している可能性は十分過ぎるほどあります)を感じていました.
- 数式いっぱいで挫折しちゃいそうな気分になるタイプ
- 概要の説明後はライブラリの使い方で終り消化不良になってしまうタイプ
私は,中身を全く分からずにライブラリを使うことに対して無駄に抵抗感があるので,もうちょっと踏み込んだ本が出ないかな-と,ちょっと様子を見ていました(自分で実装しない辺りが怠慢orz いやほら,自分別にディープラーニングを専門にしてないし ^^;).
良書との出会い
すると,丁度のいい感じの本が出たので,飛びついて一気に読みました.コレが大当たりでした.

簡易ながら超シンプルなモデルで実装するというコンセプト,これが一番理解に役立つと思っている自分の考えにピッタリ合いました!解析的に証明してハイ終わり!なのではなく,手法間の特性の違いを感覚的に掴めるような説明がされていることも,特筆すべき点だと思います.
これを読んだ後,数式展開の飛躍がある部分や,もう少し深いところを知りたいと思いました.そこで,定番の下記書籍を読むと,スッキリ頭に入ってきました.


という訳で,巣籠,Deep Learning Javaプログラミング 深層学習の理論と実装,インプレス,2016.はただライブラリを使うだけでは物足りないけど,いきなり専門書に入るのもハードルが高い,という人が入門向けに読むのに適した書籍だと思います.
Convolutional Neural Networks (CNN) に特化して理解するなら,下記の書籍が群を抜いていると思います.CNNに特化してるとは言え,今回の実装に際する理解には間違いなく寄与しています.

Deep Learning Javaプログラミング 深層学習の理論と実装でもCNNを扱っているので,もちろんこちらでもかなり理解は進みます.この本は,代表的な手法を短時間で俯瞰的に比較するという点で優れていると思います.
ゼロから作るDeep Learningの方は,ニューラルネットワークの基礎の基礎からみっちりと解説しており,あれよという間にCNNまでつながってしまった!という物語みたいな構成になっているという印象です.
Pythonへの移行
Deep Learning Javaプログラミング 深層学習の理論と実装に記載されたJavaのサンプルコードを動かすことはできたのですが,ただ動かすだけじゃつまらないなぁと思いました.そこで今回は,自分でPythonに移行することにしました.
対象は,***Deep Belief Nets (DBN)***と, Stacked Denoising Autoencoders (SDA) です,
なのですごいのは著者の巣籠氏であり,私はタダ乗っかっているだけです.とは言え,何も考えずにただ移行するというのもやや酔狂な行為であろうと思い,下記のルールを儲けました.
- コピペ禁止
- Javaコードをコピペして,Pythonに合致するように書き換えるのは,意味が無いと思いました.
- ただし,自分で実装したPythonコードをコピペして修正するのはありにしました.
- 変数名を変える
- Javaコードと同じ変数名を使うことは原則として禁止しました.同じ変数名にすると,単なる写経になりかねないので,敢えて修飾子をつけました.
- ひと目で変数の意味が分かるようになるという利点もあります.
- ライブラリを使わない
- chainer や TensorFlow と言った定番のライブラリはもちろん,numpyすら使いませんでした.
- 行列を要素レベルまで分解・展開して,各項がどういう意味を持つのか考察すると色々なことが分かる場合があります.
- 単純に移行しやすいという点もあります.
- 計算部に書籍内の数式番号を挿入する(制約ボルツマンマシン部,オートエンコーダ部のみ)
- 今自分がどの数式を実装しているのかを確認することが目的です.
- かつ,あとで見返したときに対応が分かりやすいことも利点です.
ちょっと厳し目の写経,と言ったところです笑.
Python コードの紹介
コード所在
当該コードは,下記で公開しています.
- GitHubリポジトリ
実行方法
各アルゴリズムについて,実行方法は下記のとおりです.
- Deep Belief Nets
cd <cloned path>/DeepLearningWithPython/DeepNeuralNetworks
python DeepBeliefNets.py
- Stacked Denoising Autoencoders
cd <cloned path>/DeepLearningWithPython/DeepNeuralNetworks
python StackedDenoisingAutoencoders.py
ソフトウェア構成については,Deep Learning Javaプログラミング 深層学習の理論と実装 を踏襲しているので,そちらを参照下さい.
結果
次のような3種類の結果が出力されます.
-------------------------------
DBN(or SDA) Regression model evaluation
-------------------------------
Accuracy: 100.0 %
Precision:
class 1: 100.0 %
class 2: 100.0 %
class 3: 100.0 %
Recall:
class 1: 100.0 %
class 2: 100.0 %
class 3: 100.0 %
それぞれの結果の意味は下記のとおりです.
- Accuracy(正解率): 全データ中の正解率
- Precision(精度):
positiveと予測したデータ中の正解率 - Recall(再現率): 正解が
positiveであるデータ中,positiveと予測できた割合
数式で表すと次のようになります.
Accuracy = \frac{TP + TN}{TP + TN + FP + FN} \\
Precision = \frac{TP}{TP + FP} \\
Recall = \frac{TP}{TP + FN}
TP, TN, FP, FN の内訳は下表のとおりです.
| 正と予測 | 負と予測 | |
|---|---|---|
| 正が正解 | True Positive (TP) | False Negative (FN) |
| 負が正解 | False Positive (FP) | True Negative (TN) |
処理の概要
ネットワークモデル
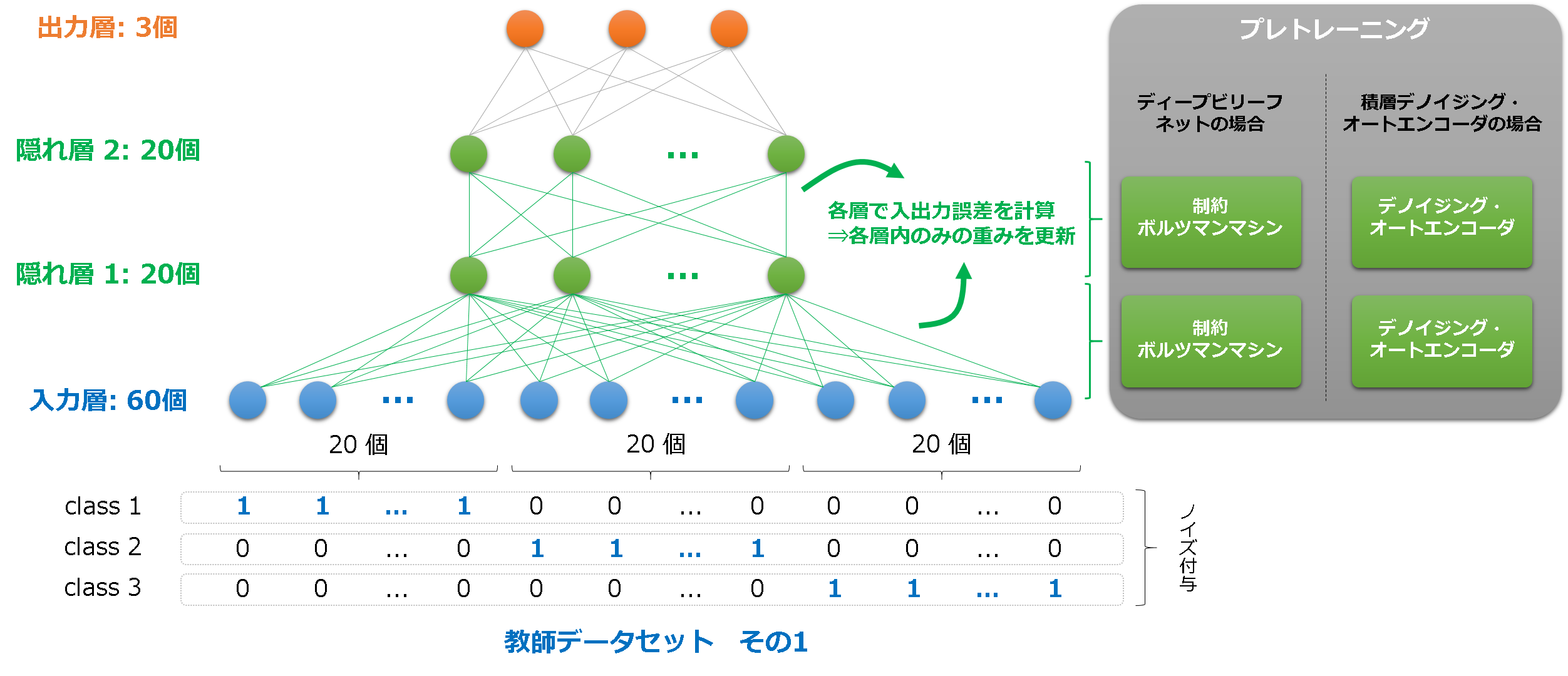
DBN/SDA いずれについても,使用するネットワークのモデルは共通です.
- 入力層ニューロン: 60個
- 3クラスのテストデータを使用します.ノイズを付与して様々な入力データを与えます.
- クラスごとのデータ構成は,後ほど掲載する図でご確認下さい.
- 隠れ層1ニューロン: 20個
- 隠れ層2ニューロン: 20個
- 活性化関数はSigmoid関数としています.
- 出力層ニューロン: 3個
- クラス識別用の層です.ロジスティック回帰を採用しています.
学習フロー
DBN/SDA いずれについても,下記の様に学習をします.
- プレトレーニング
- 各層毎に学習をする.
- DBNならRestricted Boltzmann Machines(RBM), SDAならDenoising Autoencoders(DA)を使う.
- 出力層は学習しない.
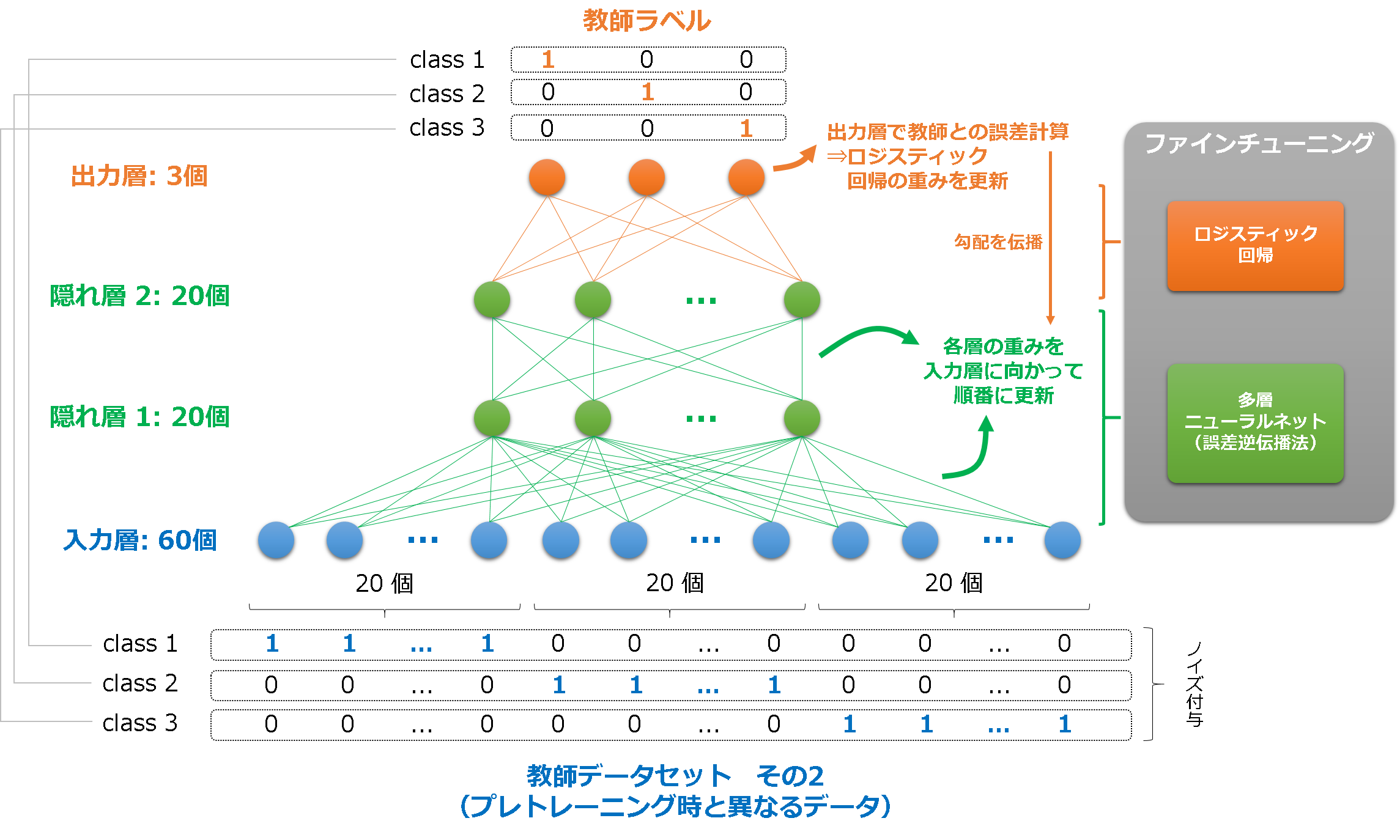
- ファインチューニング
- プレトレーニングのパラメータを初期値とし,普通の多層ニューラルネットによる学習(誤差逆伝搬法)を行う.
- 教師データセットは,プレトレーニング時と異なるものを用いる.(過学習を避けるため)
DBN/SDA のざっくりとした違い
両手法とも,全く同じモデルで,同様に作成したテストデータについて,きちんと学習ができています.異なる方法なのにほぼ同じ結果が得られるというなら,一体どういう違いがあるのか?ということが気になります.
共通点
2層ネットワークの入出力データが一致するようなパラメータを得ることが,両手法の共通点と言えます.DBNの場合はボルツマンマシンというネットワークの特性上,入力データと状態を比較することになるのですが,細かい点に目を瞑れば本質的には同じことをしています.
また,学習段階で様々なノイズを付与したデータを使っておくことで,いざ本番で識別するときにノイズに強くするという点も共通です.そのノイズの与え方に違いが有ると解釈できます.
相違点
DBNの場合は,ニューロンが活性化するかどうかが確率的に決定されます.同じ状態を得ているのに,活性化したりしなかったりするのです.この特性が,学習中のパラメータに自動的にノイズを付与していることに相当します.アルゴリズムが勝手にノイズを付与しているのです.
一方,SDAの場合は,学習データに対して,何らかのノイズを付与した上で,学習器に入力します.アルゴリズムは確定論的に学習を進めるので,それ自身にノイズを付与する特性を有していないためです.
これらの観点から,下記のような特長の違いがあると理解できます.
- DBN
- アルゴリズムが勝手にノイズを付与してくれるので,利用者は入力データを加工する必要がなく,比較的楽に利用できる.
- 活性化関数の出力時にいちいち確率計算しないといけないので,実装が少し大変.
- SDA
- 学習自体は普通のニューラルネットワークの枠組みなので,実装が楽.
- 学習データにノイズを付与するという作業が,利用者側で必要となる.
- ただし,与えたいノイズに何らかの傾向を与えたいのであれば,逆に自由度があるとも言える.
このような特性がどのように学習に影響をあたえるのか,なぜこの方法で初期化を行うと深層ネットワークの学習がうまくいくのかという問いについては,まだ様々な見解があるという段階のようです.私の頭もまだ整理されていないので,ここでとやかく言うのは控えることにします笑 ^^;
おわりに
参考となるサンプルプログラムがあったにせよ,自分の手を動かして実装することで,Deep Learning (ディープラーニング) について少しだけ理解が進みました.
ここに掲載した情報が,少しでもどなたかのお役に立てたら,これ以上の喜びはございません.
まだドロップアウトや,CNNの実装までできていませんが,また気が乗ったときに実装するつもりです ^^