【背景】
深層学習のトレーニングには,精度の確保のために大量の教師データが必要な事が知られています。(特に画像認識)
・https://www.youtube.com/watch?v=NKpuX_yzdYs (Andrew Ng 氏の講演動画)
・http://yusuke-ujitoko.hatenablog.com/entry/2017/07/15/004540
例えば,有名なデータセットの枚数は下記ととても多いです。
ImageNet:1400 万枚(~700 枚/クラス)
CIFAR10: 60000 枚(10000 枚/クラス)
MNIST: 65000 千枚(10000 枚/クラス)
特に MNIST に至っては手書きの数字を認識させるのに,1 種類当たりおよそ 1 万枚もの教師画像が存在することに驚きすら感じます。
(もちろん,クラス分類するだけなら SVM などを使えばデータは少なくて済むとは思いますが)
一方で,2014 年から研究が盛んな GAN は,一般に学習が難しいと言われていますが,
画像認識のように教師データの数 (GAN で言うところの Real データ数) と学習の成否の関連はあまり論じられていないように思えます。
GAN の研究で頻出する LSUNベッドルームで 300 万,CelebA で 20 万とこれもまた膨大なデータ数です。
今回,どれだけの Real データと競争させれば Generator がそれらしい画像を生成するようになるのか、MNIST で試してみました。
(画像認識のタスクで必要な教師データの補充に GAN の生成画像を活用できるとよく言われるので,必要な画像のオーダーとしては GAN の方が少ないだろうと予想はできます)
モデル条件
Collection of generative models (https://github.com/hwalsuklee/tensorflow-generative-model-collections) の
GAN.py コードを参考に,データのロード部分だけ変更。
def load_mnist(dataset_name):
x_train = pd.read_csv('x_train_df_10000.csv')
#x_train_df_10000.csv: MNIST のデータから 10000 行分だけ残したファイル
x_train = np.array(x_train)
trX = x_train.reshape(200, 28, 28, 1)
t_train = pd.read_csv('t_train_df_10000.csv')
t_train = np.array(t_train)
X = trX
y = t_train.astype(np.int)
return X, y
結果
学習に用いた MNIST の Real データ数と Generator の生成画像です。


1 万枚での生成画像は 6.5 万枚より少しぼやけているように見えますが,さほど変わりません。

1000 枚では生成が少し遅くなるものの,手書き数字は生成されます。ノイズのようなドットが散見されます。

500 枚の学習では,生成画像が一部崩れていますが,それでも大部分の数字は生成できています。
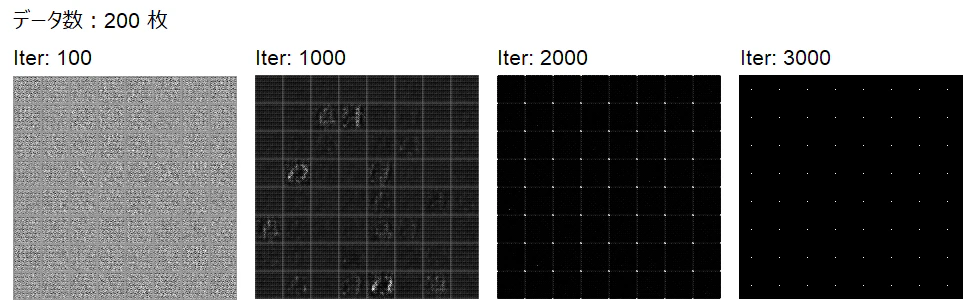
200 枚では,手書き数字が生成されません。閾値は 200 枚と 500 枚の間のようです。
もちろんこれはあくまで 28×28 と画像サイズの小さい MNIST での結果ですので,サイズ の大きな画像になると必要な枚数はもっと増えてくると思います。
GAN の用途は今後色々と提案されて行くと思いますが,実用途においては対象がニッチになる程,Real データの確保が課題の一つになると考えているので,今回興味本位でやってみました。