Amaozon CloudSearchは、比較的簡単な準備で検索を実装することができるフルマネージドサービスです。データのアップロードに関して、単体のデータのアップロードやDynamoDBやS3との連携については探すとすぐに出てきたのですが、数百ファイルからなるGB単位のドキュメントバッチをアップロードする方法は調べても出てこなかったので、書き残します。jsonファイルをローカルからCLIを用いてアップロードしますが、そのコマンドをsubprocessとして呼び出すpythonスクリプトを書きます。
前提
・以下に目を通している
・MacOS
・CLIがインストールされている。
% aws --version
aws-cli/1.23.4 Python/3.8.10 Darwin/21.6.0 botocore/1.25.4
・アップロードする先のCloudSearchはインデックスフィールド作成済み
・アップロードするJSONドキュメントバッチは1つのフォルダ(ここでは「json_folder」)下に存在している
<実行ディレクトリ>
├── json_folder
│ ├── tmp100.json
│ ├── tmp105.json
│ ├── tmp110.json
│ ├── tmp1120.json
│ ├── tmp1125.json
│ ├── tmp1130.json
│ ├── tmp1135.json
│ ├── tmp1140.json
│ ├── tmp1145.json
│ ├── tmp115.json
│ ├── tmp1150.json
│ ├── tmp1155.json
│ ├── tmp1160.json
│ ├── tmp1165.json
│ ├── tmp1170.json
│ ├── tmp1175.json
│ ├── tmp1180.json
│ ├── tmp1185.json
・ ・
・ ・
・CloudSearchのポリシー設定でCLI操作が許可されている。
以下はこのjsonアップロード時のCloudSearchドメインのポリシーです。Acrtionにアップロードの許可が含まれていれば大丈夫です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::00123456789:user/testuser"
},
"Action": "cloudsearch:*"
}
]
}
やり方
以下のpythonスクリプトを用意します。
import os, subprocess
json_files = []
directory = 'json_folder'
current_dir = os.getcwd()
for dirpath, _, filenames in os.walk(directory):
for filename in filenames:
if filename.endswith('.json'):
json_files.append(os.path.join(current_dir,dirpath, filename))
#print(json_files)
for file in json_files:
filepath = os.path.join(dirpath, file)
subprocess.call([
'aws', 'cloudsearchdomain', '--endpoint-url', "http://doc-hogehoge-nkjbre5g4wk45whu5tri28h4w5h.us-east-1.cloudsearch.amazonaws.com",
'--region', 'us-east-1',
'upload-documents', '--content-type',
'application/json', '--documents', filepath
])
エンドポイントのurl、リージョンについてはCloudSearchの各ドメインに合わせてください。
実行するとアップロード処理が開始されます。("adds": 5000というのは各jsonドキュメントバッチ内のレコード数です)
% python upload.py
{
"status": "success",
"adds": 5000,
"deletes": 0
}
{
"status": "success",
"adds": 5000,
"deletes": 0
}
{
"status": "success",
"adds": 5000,
"deletes": 0
}
{
"status": "success",
"adds": 4999,
"deletes": 0
}
{
"status": "success",
"adds": 4999,
"deletes": 0
}
{
"status": "success",
"adds": 5000,
"deletes": 0
}
{
"status": "success",
"adds": 4999,
"deletes": 0
}
{
"status": "success",
"adds": 5000,
"deletes": 0
}
・
・
・
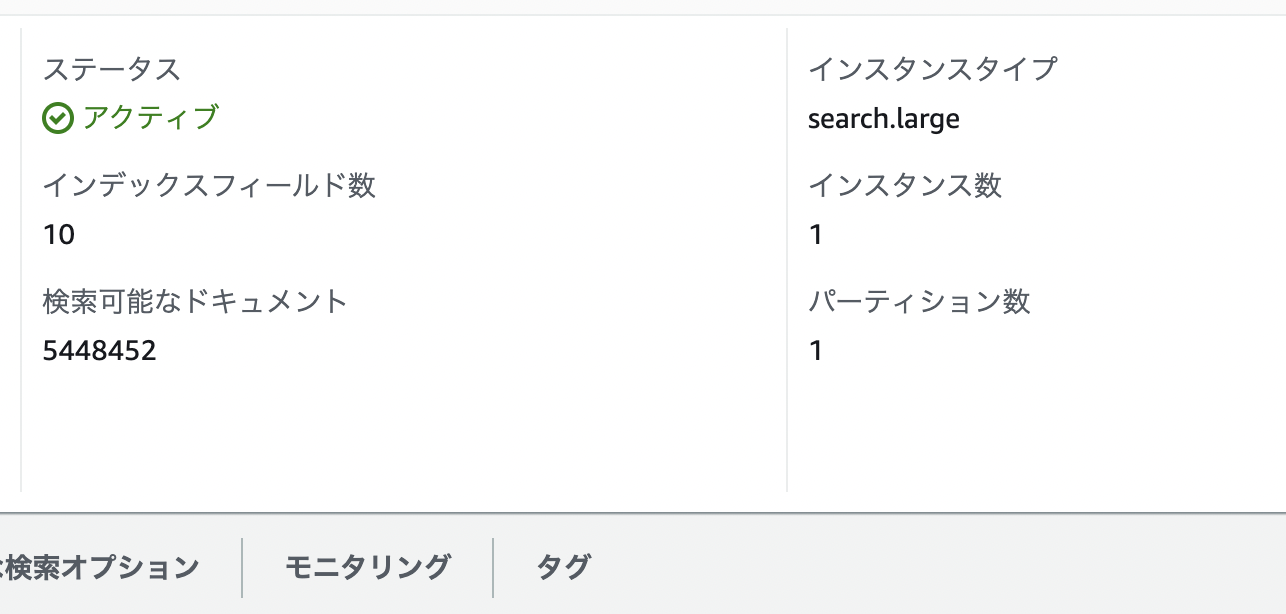
更新後のドメインのコンソール画面の様子
ハマったこと
jsonをアップロードする際に、CLIが以下のエラーを吐き出しました。
1つめ
CloudFront "Field "hogefield" must have array type to have multiple values
これは、インデックスフィールドの設定が誤っていたことが原因でした。
CloudSearchのドメインを作る際に、インデックスフィールドはテストデータから自動作成できます。自分はこのやり方で作成したのですが、本来text-arrayで作成されるはずのインデックスタイプが、textで作成されていました。そのため、型エラーが発生していました。
自動作成されるインデックスフィールドはちゃんと確認しないといけないですね。
2つめ
Error parsing parameter '--documents': Blob values must be a path to a file.
こちらは、書いてる途中のupload.pyを打った際に吐かれたものです。jsonファイルを絶対パスで指定する(current_dir の部分)ことで解消しました。
その他
公式サイトではドキュメントバッチのアップロードは「10秒に1回まで」というようなことが書いてありますが、間隔を開けずとも問題なく処理が終わりました。