3ヶ月で出来たもの
まずは蠢く内臓の成果物から、これが今回作ったポリープ検出AIです!
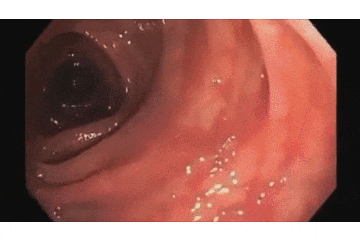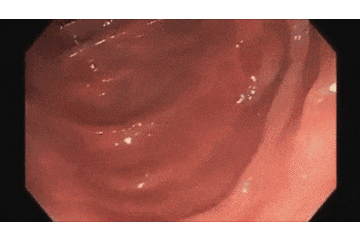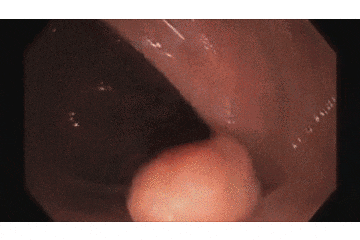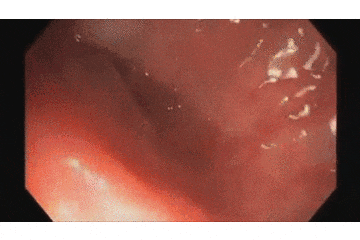
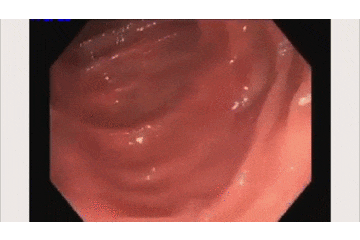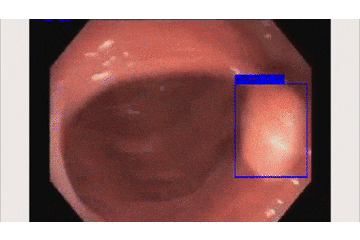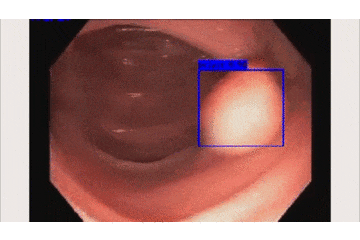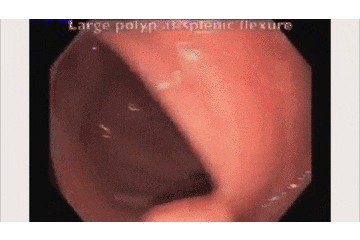
上の映像が元の内視鏡の動画で、
下が今回開発した検出AIの動作動画です。
青い枠で「ポリープだよ!」と主張してくれてますね!
3ヶ月の学習の流れ
基礎的な機械学習手法のスクラッチ
まずは数学的な理解から始めました。
手法ごとの数式を読んで、それを実装に落としていきます。
- 線形回帰
- 重回帰
- 主成分分析
- Kmeans
- 決定木
- SVM
悶え苦しんだのですが、
この時期に数式に対するアレルギーがほぐれていきました!
最初は2乗誤差の微分変形を理解するのに苦労した思い出があります。
このときに一番参考になった書籍は
「やさしく学ぶ 機械学習を理解するための数学のきほん」
です
これで機械学習の更新の概念が腹落ちしました。オススメ!
kaggleへの挑戦
定番のタイタニックや
良質なコンペのホームクレジットに挑戦しました。
ここではコンペで競うことは目的ではありません。
EDA(データの眺め方)
前処理
モデル構築 skleran
精度の確認
など
データサイエンスの基礎力をつけていきました。
これによって、データを扱う上での流れを体得できました。
CNN・RNN スクラッチ
ゼロから作るDeep Learningを参考にしつつスクラッチで実装します。
ここではモデルだけではなく、
・イテレーションやエポックを回す部分
・精度検証の部分
も実装しました。
今ではどの引数が何を求めて何が返されるのかイメージがスッキリできます。
これによって
tensorflowや
PyTorchといったどんなフレームワークでも
ドキュメントを読めるようになったので、対応できるようになりました!
論文精読
画像系統・物体検出に興味があったので
U-Net
faster-RCNN
YOLO
SSD
RefineDet
などを読んでまとめていきます。
最初は面食らいましたが、実際はそんなに大したものではありません!
今までの練習でCNNの前提知識と数式への対応方法を知っているので、読めるようになってました。
もしここで、論文にまだ抵抗があったら基本の王道の論文の日本語のまとめ記事を読んで理解しましょう!
↓王道論文はこういう日本語記事が多く出てるのでおすすめです
【論文紹介】YOLOの論文を読んだので要点をまとめてみた
さて、ここからは今回どうやって検出AIをつくったかを紹介します。
なにか役に立ちそうなもののモックアップを作りたかったので
ディープラーニングの活用が注目されている業界の医療の画像診断をやってみようと思いました!
今回の製作の流れ
すでに動いているものを使う
車輪の再発明は無駄なので、巨人の肩に乗ります。
今回は内視鏡の動画でポリープの検出をリアルタイムにしたかったので
YOLOv3を採用しました!
https://github.com/qqwweee/keras-yolo3
速度・精度を基準に何を使うかを選定しましたが、
小さい物体の検出精度が他の手法より良いので決めました!
データ準備
ポリープの画像を集める必要があります。
グーグル画像検索で一つ一つ探そうと思っていたところ、
ちょうどいいデータセットがありました!
The Kvasir Dataset
これを学習用データにするために整えていきます。
アノテーション
BBox-Label-Tool
このツールをつかってアノテーションファイルをつくります。
ここで生成したファイルをもとに、
yolo-kerasのread.meで指定された形式に変換します。
ここで自作のスクリプトを書いて変換し、train.txtを作成します。
今回は500枚の学習データを用意しました。
学習
train.pyを実行し100epochほど回します。
GPUは1080tiを使ったので
2時間ほどで生成できました!
推論
yolo_video.pyにて実行すると出来た!
これからやりたいこと
精度のために必要なデータを収集したい
医療では疾患の見落としが命にかかわるので、Recall(見落とし率)を重視したモデルに仕上げたいです。
そのためには検出に適したデータを集める必要があります。
今回はデータセットの用意が便宜上有りものを使いましたが
見落としがちな初期ステージの画像や、症例の少ないものの画像データがほしいです。
最適なデータ増幅の手法を追いたい
内視鏡ごとの特徴や光の当たり具合で検出精度は変わります。
これを補完するようなデータ増幅の手法を実装していきたいです。
具体的には、
・輝度・コントラストを変更したデータ
・Cutoutの手法や
・DropBlockの手法をやって
精度が上がるかを検証して実運用可能なレベルに持っていきたいです。
最新の物体検出の手法を追いたい
AAAI2019(AIの学会)に採択された新しい手法のM2Detを試したいです。
これはYOLOv3よりも小さい物体の認識精度が向上しているようです。
これを使えば、もっと疾患の見落としが減るかもしれません。
さいごに
最初は数式も論文も苦手で、ほんとにできるのか不安でいっぱいでした。
しかし、実際にプロトタイプを手法の選択・データの生成からできるようになって達成感でいっぱいです。
DeepLearningやってみたいけど一歩が踏み出せない
どんな手順で学んでいけばいいかわからない
何ができるようになるのか分からない
そういった方の背中をこの記事でそっと押せたら幸いです。