こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は言語モデルLUKEをファインチューニングして、8つの感情を分析できるようにしたいと思います。
今回やりたいことは文章が与えられたとき、8つの感情(喜び、悲しみ、期待、驚き、怒り、恐れ、嫌悪、信頼)のうちどの感情が最も強く含まれているのかを判別できるようにすることです。
つまり、多クラス分類と考えて、分析を行います。
今回作成したモデルはこちら(Hugging Face)で配布していますので、ぜひ利用してみてください。
LUKE

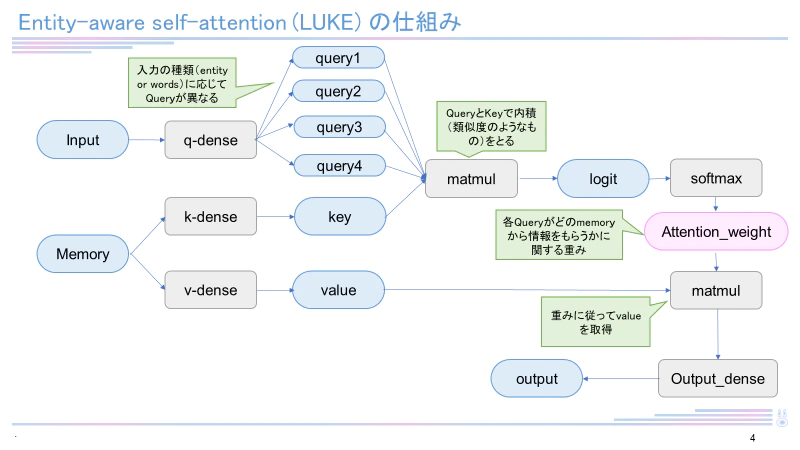
2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
日本語バージョンのLUKE-baseモデルは執筆現在(2022年12月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。LUKEはRoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
環境
pandas 1.4.4
numpy 1.23.4
torch 1.12.1
transformer 4.24.0
Python 3.9.13
sentencepiece 0.1.97
wrimeデータセット
愛媛大学梶原智之先生が作成された感情分析のためのデータセット。テキストの書き手と読み手の両方の立場から感情強度が付与されています。ver1は43200文、ver2は35000文が収録されています。
{
"sentence": "ぼけっとしてたらこんな時間。チャリあるから食べにでたいのに…",
"user_id": "1",
"datetime": "2012/07/31 23:48",
"writer": {
"joy": 0,
"sadness": 1,
"anticipation": 2,
"surprise": 1,
"anger": 1,
"fear": 0,
"disgust": 0,
"trust": 1
},
"reader1": {
"joy": 0,
"sadness": 2,
"anticipation": 0,
"surprise": 0,
"anger": 0,
"fear": 0,
"disgust": 0,
"trust": 0
},
"reader2": {
"joy": 0,
"sadness": 2,
"anticipation": 0,
"surprise": 1,
"anger": 0,
"fear": 0,
"disgust": 0,
"trust": 0
},
"reader3": {
"joy": 0,
"sadness": 2,
"anticipation": 0,
"surprise": 0,
"anger": 0,
"fear": 1,
"disgust": 1,
"trust": 0
},
"avg_readers": {
"joy": 0,
"sadness": 2,
"anticipation": 0,
"surprise": 0,
"anger": 0,
"fear": 0,
"disgust": 0,
"trust": 0
}
}
準備(ライブラリのインストール)
pip install datasets
pip install torch
pip install transformers
pip install sentencepiece
データのロードと学習
from datasets import load_dataset
dataset = load_dataset("shunk031/wrime", name="ver1")
dataset2 = load_dataset("shunk031/wrime", name="ver2")
# DatasetDict({
# train: Dataset({
# features: ['sentence', 'user_id', 'datetime', 'writer', 'reader1', 'reader2', 'reader3', 'avg_readers'],
# num_rows: 40000
# })
# validation: Dataset({
# features: ['sentence', 'user_id', 'datetime', 'writer', 'reader1', 'reader2', 'reader3', 'avg_readers'],
# num_rows: 1200
# })
# test: Dataset({
# features: ['sentence', 'user_id', 'datetime', 'writer', 'reader1', 'reader2', 'reader3', 'avg_readers'],
# num_rows: 2000
# })
# })
print(dataset['train']['avg_readers'][0])
import numpy as np
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-japanese-large-lite")
from tqdm import tqdm
tqdm.pandas()
# データセットを作成するための下準備
data_dict=dataset['train']['sentence']
max_seq_length = 128
data=tokenizer(
data_dict,
truncation=True,
max_length=max_seq_length,
padding="max_length"
)
print('fini')
import torch
import re
tensor_input_ids = torch.tensor(data["input_ids"])
tensor_attention_masks = torch.tensor(data["attention_mask"])
answer=np.zeros((len(dataset['train']),8))
pre=np.zeros(8)
dataset_t=dataset['train']['avg_readers']
for i in range(len(dataset['train'])):
pre=str(dataset_t[i]).split(',')
for j in range(8):
pre[j]=re.sub(r"\D","",pre[j])
max_index=np.argmax(pre)
for j in range(8):
if j==max_index:
answer[i][j]=1
else:
answer[i][j]=0
print('fini')
data_dict_val=dataset['validation']['sentence']
max_seq_length = 128
data_val=tokenizer(
data_dict_val,
truncation=True,
max_length=max_seq_length,
padding="max_length"
)
import torch
tensor_input_ids_val = torch.tensor(data_val["input_ids"])
tensor_attention_masks_val = torch.tensor(data_val["attention_mask"])
answer_val=np.zeros((len(dataset['validation']),8))
dataset_v = dataset['validation']['avg_readers']
for i in range(len(dataset['validation'])):
pre=str(dataset_v[i]).split(',')
for j in range(8):
pre[j]=re.sub(r"\D","",pre[j])
max_index=np.argmax(pre)
for j in range(8):
if j==max_index:
answer_val[i][j]=1
else:
answer_val[i][j]=0
# 正解データの取得
tensor_labels = torch.tensor(answer)
# 正解データの取得
tensor_labels_val = torch.tensor(answer_val)
from torch.utils.data import Dataset
# データセットの作成
class CQADataset(Dataset):
def __init__(self, input,attention,label, is_test=False):
self.input = input
self.attention=attention
self.label=label
self.is_test = is_test
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.input[idx])}
data['attention_mask']= torch.tensor(self.attention[idx])
data['label']= torch.tensor(self.label[idx])
return data
def __len__(self):
return len(self.input)
dataset_train = CQADataset(tensor_input_ids,tensor_attention_masks,tensor_labels)
indices = np.arange(len(dataset_train))
dataset_valid = CQADataset(tensor_input_ids_val, tensor_attention_masks_val, tensor_labels_val)
from transformers import AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
model=AutoModelForSequenceClassification.from_pretrained("studio-ousia/luke-japanese-large-lite", num_labels = 8)
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
#2値分類ならaverage='binary'とする
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'precision': precision,
'recall': recall,
'f1': f1,
}
# トレーニングの設定を記述する
training_config = TrainingArguments(
output_dir = 'C://Users//tomot//desktop//Python//luke_wrime',
num_train_epochs = 3,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
learning_rate = 1e-5,
weight_decay = 0.1,
save_steps = 5000,
eval_steps=15000,
do_eval = True
)
# トレーニング
trainer = Trainer(
model = model,
args = training_config,
tokenizer = tokenizer,
train_dataset = dataset_train,
eval_dataset = dataset_valid,
compute_metrics = compute_metrics, #compute_metrics
)
trainer.train()
trainer.evaluate()
print('saved')
推論の実行
以下のコードを実行することで、文章中に含まれている感情を分析することができます。
from transformers import AutoTokenizer, AutoModelForSequenceClassification, LukeConfig
import torch
tokenizer = AutoTokenizer.from_pretrained("Mizuiro-sakura/luke-japanese-large-sentiment-analysis-wrime")
config = LukeConfig.from_pretrained('Mizuiro-sakura/luke-japanese-large-sentiment-analysis-wrime', output_hidden_states=True)
model = AutoModelForSequenceClassification.from_pretrained('Mizuiro-sakura/luke-japanese-large-sentiment-analysis-wrime', config=config)
text='すごく楽しかった。また行きたい。'
max_seq_length=512
token=tokenizer(text,
truncation=True,
max_length=max_seq_length,
padding="max_length")
output=model(torch.tensor(token['input_ids']).unsqueeze(0), torch.tensor(token['attention_mask']).unsqueeze(0))
max_index=torch.argmax(torch.tensor(output.logits))
if max_index==0:
print('joy、うれしい')
elif max_index==1:
print('sadness、悲しい')
elif max_index==2:
print('anticipation、期待')
elif max_index==3:
print('surprise、驚き')
elif max_index==4:
print('anger、怒り')
elif max_index==5:
print('fear、恐れ')
elif max_index==6:
print('disgust、嫌悪')
elif max_index==7:
print('trust、信頼')
終わりに
今回はwrimeデータセットを用いて感情分析を行ってみました。
ぜひ皆さんも感情分析をしてみてください。
では、ばいにゃん~。