こんにちにゃんです。
水色桜(みずいろさくら)です。
今回はCNN (Convolutional Neural Network) と言語モデルLUKEを組み合わせて正答率の向上を目指したいと思います。
モデルの設計方針としては、CommonsenseQA用にファインチューニングしたLUKEの最終層の特徴量をCNNに入力するという形をとりたいと思います。
言語モデルについて様々な記事を調べていく中で、CNNと組み合わせれば、性能の向上が期待できるという記事を目にしました。
しかし、実際にCNNと組み合わせている記事は私の知る限りではありませんでした。
そこで、今回は実際にCNNとLUKEを組み合わせて、性能面でどのような効果があるのか実証してみようと思います。
まず、今回作成したCNN-LUKEアンサンブルモデルの精度を以下に示します。
30回の学習で95.2%の正答率となっています。
LUKE単体だと8割弱の精度のため、正答率自体は向上しているといえると思います。しかし、学習率を大きくとったため(計算回数節約のため)、若干値が不安定になっています。
では、さっそくコードなどについて解説していきます。
Epoch: 1/30.. Time: 9.60s.. Training Loss: 1.457.. Training Accu: 0.687.. Val Loss: 0.016.. Val Accu: 0.662
Epoch: 2/30.. Time: 9.57s.. Training Loss: 1.223.. Training Accu: 0.732.. Val Loss: 0.015.. Val Accu: 0.741
Epoch: 3/30.. Time: 9.63s.. Training Loss: 1.221.. Training Accu: 0.744.. Val Loss: 0.015.. Val Accu: 0.522
Epoch: 4/30.. Time: 9.54s.. Training Loss: 1.221.. Training Accu: 0.757.. Val Loss: 0.015.. Val Accu: 0.642
Epoch: 5/30.. Time: 9.66s.. Training Loss: 1.220.. Training Accu: 0.728.. Val Loss: 0.015.. Val Accu: 0.805
Epoch: 6/30.. Time: 9.58s.. Training Loss: 1.219.. Training Accu: 0.744.. Val Loss: 0.015.. Val Accu: 0.744
Epoch: 7/30.. Time: 9.58s.. Training Loss: 1.220.. Training Accu: 0.750.. Val Loss: 0.015.. Val Accu: 0.695
Epoch: 8/30.. Time: 9.52s.. Training Loss: 1.221.. Training Accu: 0.729.. Val Loss: 0.015.. Val Accu: 0.633
Epoch: 9/30.. Time: 9.66s.. Training Loss: 1.221.. Training Accu: 0.710.. Val Loss: 0.015.. Val Accu: 0.498
Epoch: 10/30.. Time: 9.71s.. Training Loss: 1.220.. Training Accu: 0.712.. Val Loss: 0.015.. Val Accu: 0.529
Epoch: 11/30.. Time: 9.70s.. Training Loss: 1.228.. Training Accu: 0.744.. Val Loss: 0.015.. Val Accu: 0.616
Epoch: 12/30.. Time: 9.66s.. Training Loss: 1.232.. Training Accu: 0.716.. Val Loss: 0.015.. Val Accu: 0.896
Epoch: 13/30.. Time: 9.68s.. Training Loss: 1.231.. Training Accu: 0.731.. Val Loss: 0.015.. Val Accu: 0.695
Epoch: 14/30.. Time: 9.70s.. Training Loss: 1.230.. Training Accu: 0.768.. Val Loss: 0.015.. Val Accu: 0.708
Epoch: 15/30.. Time: 9.73s.. Training Loss: 1.231.. Training Accu: 0.725.. Val Loss: 0.015.. Val Accu: 0.813
Epoch: 16/30.. Time: 9.92s.. Training Loss: 1.226.. Training Accu: 0.717.. Val Loss: 0.015.. Val Accu: 0.555
Epoch: 17/30.. Time: 9.97s.. Training Loss: 1.229.. Training Accu: 0.749.. Val Loss: 0.015.. Val Accu: 0.556
Epoch: 18/30.. Time: 10.49s.. Training Loss: 1.233.. Training Accu: 0.718.. Val Loss: 0.015.. Val Accu: 0.930
Epoch: 19/30.. Time: 9.92s.. Training Loss: 1.234.. Training Accu: 0.727.. Val Loss: 0.015.. Val Accu: 0.748
Epoch: 20/30.. Time: 10.15s.. Training Loss: 1.232.. Training Accu: 0.704.. Val Loss: 0.015.. Val Accu: 0.765
Epoch: 21/30.. Time: 10.16s.. Training Loss: 1.230.. Training Accu: 0.701.. Val Loss: 0.015.. Val Accu: 0.545
Epoch: 22/30.. Time: 10.08s.. Training Loss: 1.220.. Training Accu: 0.730.. Val Loss: 0.015.. Val Accu: 0.539
Epoch: 23/30.. Time: 10.02s.. Training Loss: 1.234.. Training Accu: 0.734.. Val Loss: 0.015.. Val Accu: 0.749
Epoch: 24/30.. Time: 10.05s.. Training Loss: 1.235.. Training Accu: 0.717.. Val Loss: 0.015.. Val Accu: 0.746
Epoch: 25/30.. Time: 10.02s.. Training Loss: 1.240.. Training Accu: 0.728.. Val Loss: 0.016.. Val Accu: 0.694
Epoch: 26/30.. Time: 9.97s.. Training Loss: 1.238.. Training Accu: 0.713.. Val Loss: 0.015.. Val Accu: 0.710
Epoch: 27/30.. Time: 10.04s.. Training Loss: 1.245.. Training Accu: 0.730.. Val Loss: 0.015.. Val Accu: 0.523
Epoch: 28/30.. Time: 10.01s.. Training Loss: 1.222.. Training Accu: 0.734.. Val Loss: 0.015.. Val Accu: 0.351
Epoch: 29/30.. Time: 10.03s.. Training Loss: 1.222.. Training Accu: 0.731.. Val Loss: 0.015.. Val Accu: 0.601
Epoch: 30/30.. Time: 9.97s.. Training Loss: 1.224.. Training Accu: 0.725.. Val Loss: 0.015.. Val Accu: 0.952
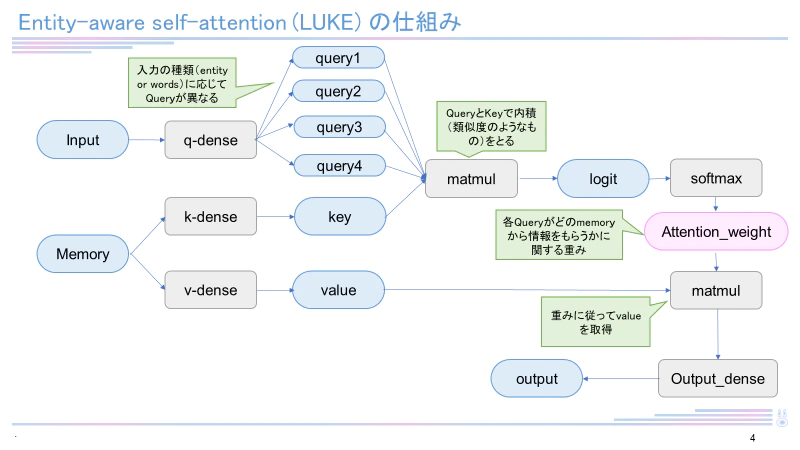
LUKE

2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
日本語バージョンのLUKE-baseモデルは執筆現在(2022年12月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。LUKEはRoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
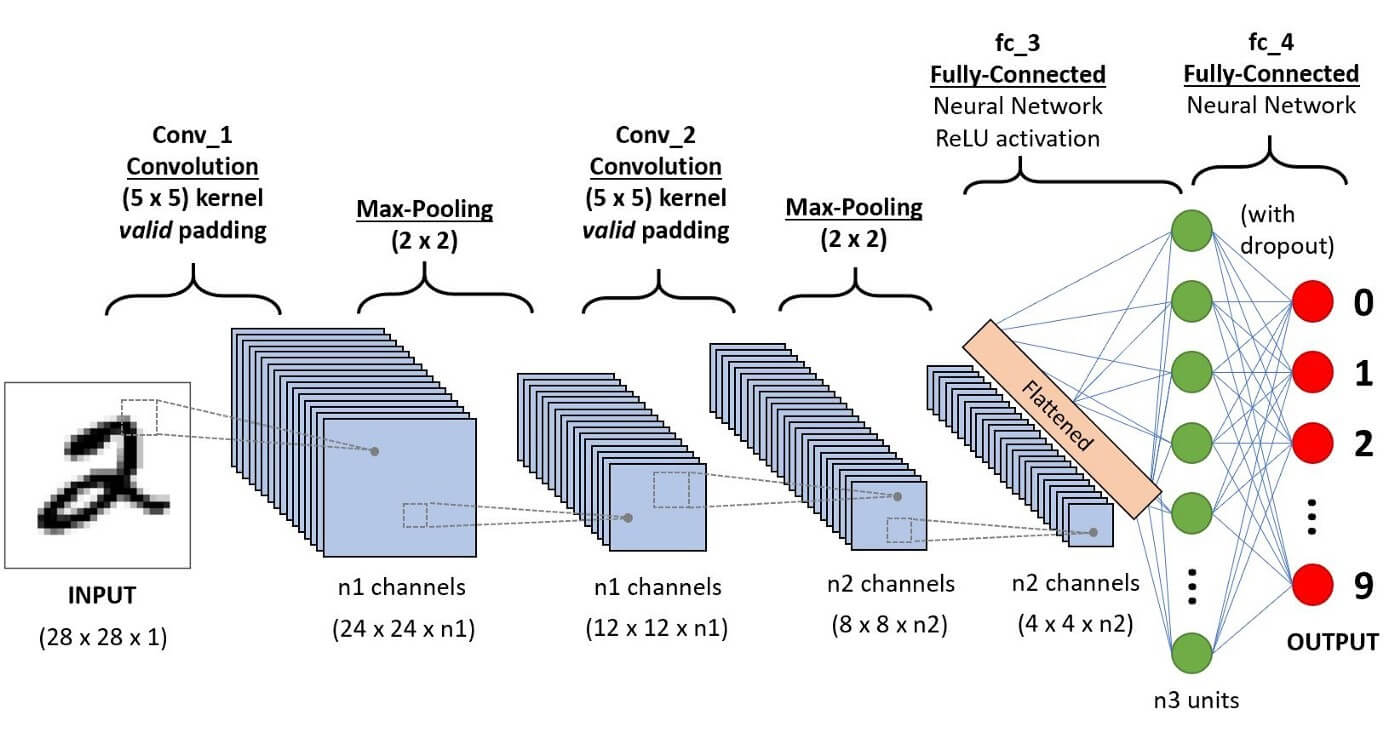
CNN
参考:Stochastic Reconstruction of an Oolitic Limestone by Generative Adversarial Networks
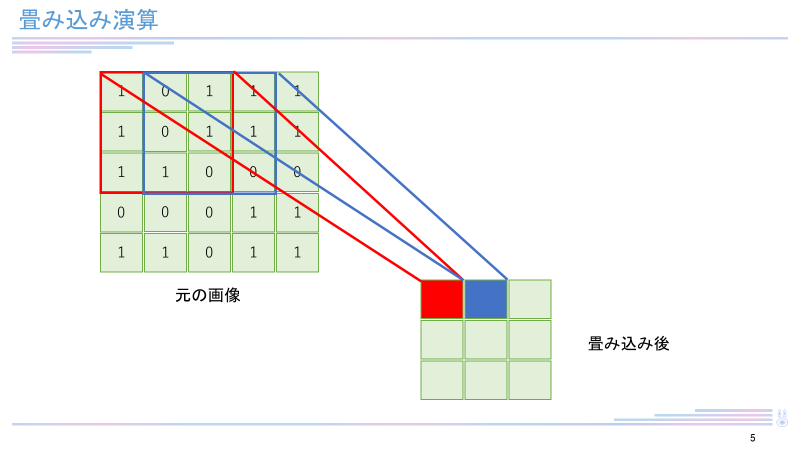
CNN (Convolutional Neural Network) は畳み込み演算を用いたニューラルネットワークアーキテクチャ。主に画像解析分野で用いられている手法です(自然言語処理で用いられている例は稀)。上の図のように「畳み込み(convolution)」と「プーリング(pooling)」「全結合層(Affine)」という3つの層から成ります。畳み込みは下図のように、画像上にフィルタと呼ばれる小領域(下図では赤枠3x3のエリア)をとり、これを1つの特徴量として圧縮(=畳み込み)することを言います。畳み込みを行うことで、位置によらない、画像の特徴を抽出することができます。
プーリング層では、平均もしくは最大値を算出し、それ以外の値は削除します。これによりロバスト性を付与することができるとともに、画像解析における位置依存性を下げることができます。

参考:Stochastic Reconstruction of an Oolitic Limestone by Generative Adversarial Networks
全結合層は通常のニューラルネットワークと同様に線形変換を施します。これにより、最終的に分類したい個数の要素を持ったベクトルへ変換していきます。
評価に用いるデータセット(JGLUE)
yahoo JAPAN株式会社さんと早稲田大学河原研究室の共同研究で構築された、日本語言語理解ベンチマーク。言語モデルの包括的な評価のために作成されました。各データはクラウドソーシングにより収集されています。評価データの種類はMARC-ja(二値分類タスク)、JSTS(文章の類似度計算)、JNLI(文章の関係性判別)、JSQuAD(抜き出し型のQAタスク)、JCommonsenseQA(常識を問う5択の選択問題)があります。今回はこのうちJCommonsenseQAに関して解析を行うので、こちらからあらかじめデータをダウンロードしておいてください。
実装したコード
今回実装した全体のコードを以下に示します。
cnn_luke.py
from transformers import AutoTokenizer, AutoModelForMultipleChoice
import torch
tokenizer = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa')
model = AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa',output_hidden_states=True)
import json
import numpy as np
# JCommonsenseQAの読み込み
dataset_v = [json.loads(line)
for line in open("CommonsenseQA_valid.json", 'r', encoding='utf-8')]
dataset_t=[json.loads(line)
for line in open("CommonsenseQA_train.json", 'r', encoding='utf-8')]
data_t=np.zeros((8900,768))
data_v=np.zeros((1100,768))
acc=0
best_acc=0
for i in range(8900):
question=dataset_t[i]['question']
x1=tokenizer([question,question,question,question,question],[dataset_t[i]['choice0'],dataset_t[i]['choice1'],dataset_t[i]['choice2'],dataset_t[i]['choice3'],dataset_t[i]['choice4']]
,return_tensors='pt',padding=True)
leng=len(x1['input_ids'][0])
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = x1['input_ids']
X2[0, :, :] = x1['attention_mask']
model.eval()
with torch.no_grad(): # 勾配計算なし
all_encoder_layers = model(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
embedding = all_encoder_layers[1][-2].numpy()[0]
t = np.mean(embedding, axis=0)
data_t[i]=t
for i in range(1100):
question=dataset_v[i]['question']
x1=tokenizer([question,question,question,question,question],[dataset_v[i]['choice0'],dataset_v[i]['choice1'],dataset_v[i]['choice2'],dataset_v[i]['choice3'],dataset_v[i]['choice4']]
,return_tensors='pt',padding=True)
leng=len(x1['input_ids'][0])
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = x1['input_ids']
X2[0, :, :] = x1['attention_mask']
model.eval()
with torch.no_grad(): # 勾配計算なし
all_encoder_layers = model(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
embedding = all_encoder_layers[1][-2].numpy()[0]
t = np.mean(embedding, axis=0)
data_v[i]=t
# バッチサイズとエポック数の定義
batch_size = 100
num_epochs = 100
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import pandas as pd
from sklearn.model_selection import train_test_split
label_t=np.zeros(8900)
label_v=np.zeros(1100)
for i in range(8900):
label_t[i]=dataset_t[i]['label']
for i in range(1100):
label_v[i]=dataset_v[i]['label']
# データローダにデータを読み込ませる
train = torch.utils.data.TensorDataset(torch.tensor(data_t), torch.tensor(label_t))
validation = torch.utils.data.TensorDataset(torch.tensor(data_v), torch.tensor(label_v))
train_loader = DataLoader(train, batch_size = batch_size, shuffle = False)
validation_loader = DataLoader(validation, batch_size = batch_size, shuffle = False)
import torch.nn.functional as f
# モデルの作成
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Conv2d(1,32,3,1)
self.bn1=nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32,64,3,1)
self.bn2=nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(2,2)
self.bn3=nn.BatchNorm1d(8960)
self.fc1 = nn.Linear(8960,128)
self.bn4=nn.BatchNorm1d(128)
self.fc2 = nn.Linear(128,5)
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = f.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = f.relu(x)
x = self.pool(x)
x = x.view(-1, 8960)
x = self.bn3(x)
x = self.fc1(x)
x = f.relu(x)
x = self.bn4(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)
model2=CNN()
# 損失関数の定義(cross entropy)
criterion = nn.CrossEntropyLoss()
# オプティマイザの定義(今回はadamW)
learning_rate = 0.1
optimizer = torch.optim.AdamW(model2.parameters(), lr=learning_rate)
import time
# 学習過程でロスと精度を保持するリスト
train_losses, val_losses = [], []
train_accu, val_accu = [], []
for epoch in range(num_epochs):
epoch_start_time = time.time()
# 学習用データで学習
train_loss = 0
correct=0
model2.train()
for images, labels in train_loader:
# 勾配の初期化
optimizer.zero_grad()
# 順伝播
images_tensor=(images.type(torch.float))
outputs = model2(images_tensor.reshape(100, 1, 24, 32))
# ロスの計算と逆伝播
loss = criterion(outputs.squeeze(), labels.long().squeeze())
loss.backward()
optimizer.step()
# 正答数を計算
for i in range(len(images)):
predicted = torch.argmax(outputs[i])
if(predicted-labels[i]<1):
correct += 1
train_loss += loss.item()
train_losses.append(train_loss/8900)
train_accu.append(correct/8900)
# 検証用データでlossと精度の計算
val_loss = 0
correct = 0
model2.eval()
with torch.no_grad():
for images, labels in validation_loader:
# 順伝播
images_tensor=(images.type(torch.float))
outputs = model2(images_tensor.reshape(100, 1, 24, 32))
# ロスの計算
val_loss += criterion(outputs.squeeze(), labels.long().squeeze())
for i in range(len(images)):
# 正答数を計算
predicted = torch.argmax(outputs[i])
if(predicted-labels[i]<1):
correct += 1
val_losses.append(val_loss / 1100)
val_accu.append(correct / 1100)
print(f"Epoch: {epoch+1}/{num_epochs}.. ",
f"Time: {time.time()-epoch_start_time:.2f}s..",
f"Training Loss: {train_losses[-1]:.3f}.. ",
f"Training Accu: {train_accu[-1]:.3f}.. ",
f"Val Loss: {val_losses[-1]:.3f}.. ",
f"Val Accu: {val_accu[-1]:.3f}")
if(val_accu[-1]>best_acc):
torch.save(model2, 'C:\\Users\\desktop\\Python\\luke_cnn\\luke_cnn2.pth')
best_acc=val_accu[-1]
print('saved')
コードの説明
まず、事前学習済みモデルのロードを行います。事前学習済みモデルは私が以前JCommonsenseQA用に作成した'Mizuiro-sakura/luke-japanese-base-commonsenseqa'を用いました。他に特段用いたいモデルがないという方はこちらをお使いください。
from transformers import AutoTokenizer, AutoModelForMultipleChoice
import torch
tokenizer = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa')
model = AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa',output_hidden_states=True)
次に、データセットの読み込みを行います。こちらからダウンロードしておいたJCommonsenseQAファイルを適当な名前に変更して、読み込みます。
import json
import numpy as np
# JCommonsenseQAの読み込み
dataset_v = [json.loads(line)
for line in open("CommonsenseQA_valid.json", 'r', encoding='utf-8')]
dataset_t=[json.loads(line)
for line in open("CommonsenseQA_train.json", 'r', encoding='utf-8')]
data_t=np.zeros((8900,768))
data_v=np.zeros((1100,768))
次に、先ほどロードしたデータセットを事前学習済みモデルへ入力して出力を得ます。今回はこの後CNNに入力する都合、分類結果ではなく、最終層の特徴ベクトルが欲しいので、事前学習済みモデルから最終層の特徴ベクトルを取り出すプログラムを書いています。少し複雑なので、もしよくわからない場合はコピペしてしまってください。
for i in range(8900):
question=dataset_t[i]['question']
x1=tokenizer([question,question,question,question,question],[dataset_t[i]['choice0'],dataset_t[i]['choice1'],dataset_t[i]['choice2'],dataset_t[i]['choice3'],dataset_t[i]['choice4']]
,return_tensors='pt',padding=True)
leng=len(x1['input_ids'][0])
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = x1['input_ids']
X2[0, :, :] = x1['attention_mask']
model.eval()
with torch.no_grad(): # 勾配計算なし
all_encoder_layers = model(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
embedding = all_encoder_layers[1][-2].numpy()[0]
t = np.mean(embedding, axis=0)
data_t[i]=t
for i in range(1100):
question=dataset_v[i]['question']
x1=tokenizer([question,question,question,question,question],[dataset_v[i]['choice0'],dataset_v[i]['choice1'],dataset_v[i]['choice2'],dataset_v[i]['choice3'],dataset_v[i]['choice4']]
,return_tensors='pt',padding=True)
leng=len(x1['input_ids'][0])
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = x1['input_ids']
X2[0, :, :] = x1['attention_mask']
model.eval()
with torch.no_grad(): # 勾配計算なし
all_encoder_layers = model(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
embedding = all_encoder_layers[1][-2].numpy()[0]
t = np.mean(embedding, axis=0)
data_v[i]=t
次に、データローダ(バッチサイズごとに要素を取り出してくれる便利な型。詳しくは他の記事をご覧ください。)に特徴ベクトルを投げます。
# データローダにデータを読み込ませる
train = torch.utils.data.TensorDataset(torch.tensor(data_t), torch.tensor(label_t))
validation = torch.utils.data.TensorDataset(torch.tensor(data_v), torch.tensor(label_v))
train_loader = DataLoader(train, batch_size = batch_size, shuffle = False)
validation_loader = DataLoader(validation, batch_size = batch_size, shuffle = False)
次にCNNを定義します。32枚のフィルタを持った畳み込み層 → 64枚のフィルタを持った畳み込み層 → プーリング層 → 全結合層 → 全結合層 という構成になっています。
途中でBatchNorm2d層が挿入されていますが、これはバッチ正規化と呼ばれる処理で、バッチごとのスケールを合わせることで、解析結果が向上するため、挿入しています。また解析結果の安定化ももたらします。
import torch.nn.functional as f
# モデルの作成
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Conv2d(1,32,3,1)
self.bn1=nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32,64,3,1)
self.bn2=nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(2,2)
self.bn3=nn.BatchNorm1d(8960)
self.fc1 = nn.Linear(8960,128)
self.bn4=nn.BatchNorm1d(128)
self.fc2 = nn.Linear(128,5)
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = f.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = f.relu(x)
x = self.pool(x)
x = x.view(-1, 8960)
x = self.bn3(x)
x = self.fc1(x)
x = f.relu(x)
x = self.bn4(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)
model2=CNN()
# 損失関数の定義(cross entropy)
criterion = nn.CrossEntropyLoss()
# オプティマイザの定義(今回はadamW)
learning_rate = 0.1
optimizer = torch.optim.AdamW(model2.parameters(), lr=learning_rate)
最後に学習の実行と評価を行います。
モデルはval_accu(評価データでの正答率)が最も高いものを保存します。
import time
# 学習過程でロスと精度を保持するリスト
train_losses, val_losses = [], []
train_accu, val_accu = [], []
for epoch in range(num_epochs):
epoch_start_time = time.time()
# 学習用データで学習
train_loss = 0
correct=0
model2.train()
for images, labels in train_loader:
# 勾配の初期化
optimizer.zero_grad()
# 順伝播
images_tensor=(images.type(torch.float))
outputs = model2(images_tensor.reshape(100, 1, 24, 32))
# ロスの計算と逆伝播
loss = criterion(outputs.squeeze(), labels.long().squeeze())
loss.backward()
optimizer.step()
# 正答数を計算
for i in range(len(images)):
predicted = torch.argmax(outputs[i])
if(predicted-labels[i]<1):
correct += 1
train_loss += loss.item()
train_losses.append(train_loss/8900)
train_accu.append(correct/8900)
# 検証用データでlossと精度の計算
val_loss = 0
correct = 0
model2.eval()
with torch.no_grad():
for images, labels in validation_loader:
# 順伝播
images_tensor=(images.type(torch.float))
outputs = model2(images_tensor.reshape(100, 1, 24, 32))
# ロスの計算
val_loss += criterion(outputs.squeeze(), labels.long().squeeze())
for i in range(len(images)):
# 正答数を計算
predicted = torch.argmax(outputs[i])
if(predicted-labels[i]<1):
correct += 1
val_losses.append(val_loss / 1100)
val_accu.append(correct / 1100)
print(f"Epoch: {epoch+1}/{num_epochs}.. ",
f"Time: {time.time()-epoch_start_time:.2f}s..",
f"Training Loss: {train_losses[-1]:.3f}.. ",
f"Training Accu: {train_accu[-1]:.3f}.. ",
f"Val Loss: {val_losses[-1]:.3f}.. ",
f"Val Accu: {val_accu[-1]:.3f}")
if(val_accu[-1]>best_acc):
torch.save(model2, 'C:\\Users\\tomot\\desktop\\Python\\luke_cnn\\luke_cnn2.pth')
best_acc=val_accu[-1]
print('saved')
終わりに
今回はCNNとLUKEの組み合わせによる正答率の向上について書いてきました。
正答率は95.2%でしたが、epochごとに正答率が大きく上下するところを見ると、実際の正答率は8割弱といったところなのではないかと思いました。計算量が増えた割にあまり向上していないなぁといった印象です。
やはり自然言語処理とCNNはあまり相性が良くないのかもしれません(私のモデルの作成の仕方が悪いだけかもしれません)。
ここまでお付き合いいただきありがとうございました。
では、ばいにゃん~。