こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は現状最強の言語モデルLukeをファインチューニングして、JCommonsenseQAを解いてみようと思います。
作成したモデルはこちら(Hugging Face)で公開しています。
初心者でも簡単に使えるようにサンプルコードも配布しているので、ぜひ使ってみてください。
なお、CommonsenseQAを解ける日本語モデルでHugging Faceに公開されているものは執筆現在では他に存在しません。(新規性です!)
以上の理由から今回の試みは非常に意義のあることであると自負しています。
では、さっそくファインチューニングの方法などについて書いていきます。
環境
pandas 1.4.4
numpy 1.23.4
torch 1.12.1
transformer 4.24.0
Python 3.9.13
sentencepiece 0.1.97
LUKE

2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
日本語バージョンのLUKE-baseモデルは執筆現在(2022年12月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。LUKEはRoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
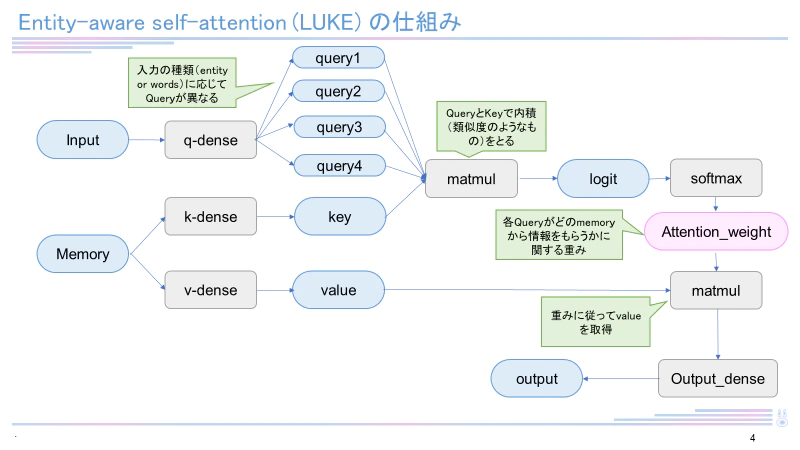
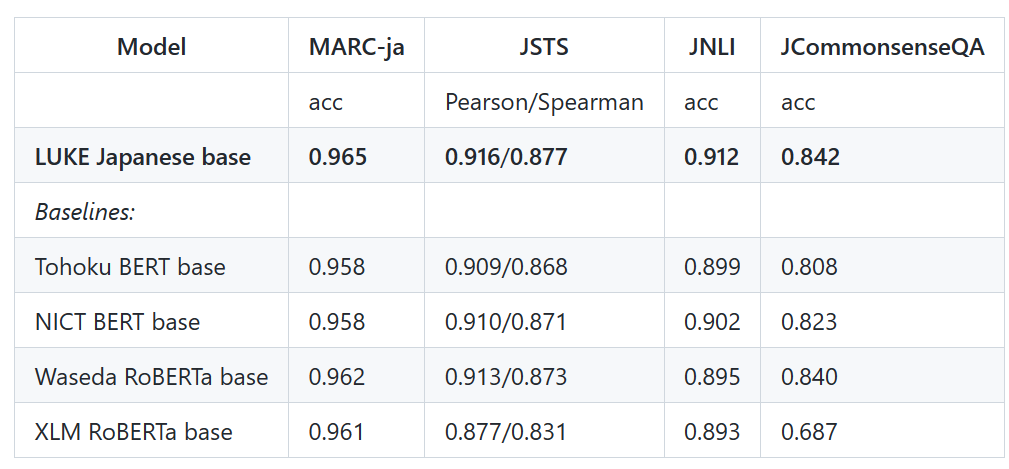
データセット
今回、デーアセットはyahoo japanさんが公開しているJGLUEのうち、JCommonsenseQAを用いました。
このデータセットは下記の例のように、質問文と5つの選択肢、回答が含まれているデータセットです。
このデータセットを用いることで、常識を問う選択式の質問に応答できるようになります。
{"q_id": 8939, "question": "電子機器で使用される最も主要な電子回路基板の事をなんと言う?", "choice0": "掲示板", "choice1": "パソコン", "choice2": "マザーボード", "choice3": "ハードディスク", "choice4": "まな板", "label": 2}
{"q_id": 8940, "question": "田んぼが広がる風景を何という?", "choice0": "畑", "choice1": "海", "choice2": "田園", "choice3": "地方", "choice4": "牧場", "label": 2}
{"q_id": 8941, "question": "しゃがんだりする様を何という?", "choice0": "腰を下す", "choice1": "座る", "choice2": "仮眠を取る", "choice3": "寝る", "choice4": "起きる", "label": 0}
学習
下記のコード(luke_commonsenseqa_train.py)を実行してモデルの学習を行いました。学習には非常に時間がかかるため、読者の皆さんは学習は飛ばして、こちら(Hugging Face)を使うことを強くお勧めいたします。
luke_commonsenseqa_train.py
import pandas as pd
import json
# JCommonsenseQAの読み込み
dataset_t = [json.loads(line)
for line in open("CommonsenseQA_train.json", 'r', encoding='utf-8')]
dataset_v = [json.loads(line)
for line in open("CommonsenseQA_valid.json", 'r', encoding='utf-8')]
# dictからdataframeに変換
train_df = pd.DataFrame.from_dict(dataset_t)
val_df = pd.DataFrame.from_dict(dataset_v)
all_df = pd.concat([train_df, val_df], ignore_index=True, axis=0)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-japanese-base")
from tqdm import tqdm
tqdm.pandas()
# データセットを作成するための下準備
def preprocess_function(examples):
context_name = "question"
ending_names = [f"choice{i}" for i in range(5)]
max_seq_length = 64
first_sentences = [[context] * 5 for context in examples[context_name]]
second_sentences = [
[f"{examples[end][i]}" for end in ending_names] for i in range(len(examples[context_name]))
]
first_sentences = sum(first_sentences, [])
second_sentences = sum(second_sentences, [])
# トークナイズ(エンコーディング・形態素解析)する
tokenized_examples = tokenizer(
first_sentences,
second_sentences,
truncation=True,
max_length=max_seq_length,
padding="max_length"
)
return {k: [v[i:i+5] for i in range(0, len(v), 5)] for k, v in tokenized_examples.items()}
data = preprocess_function(all_df)
import torch
tensor_input_ids = torch.tensor(data["input_ids"])
tensor_attention_masks = torch.tensor(data["attention_mask"])
# 正解データの取得
labels = all_df["label"].to_list()
tensor_labels = torch.tensor(labels)
import numpy as np
from torch.utils.data import Dataset, Subset
# データセットの作成
class CQADataset(Dataset):
def __init__(self, input,attention,label, is_test=False):
self.input = input
self.attention=attention
self.label=label
self.is_test = is_test
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.input[idx])}
data['attention_mask']= torch.tensor(self.attention[idx])
data['label']= torch.tensor(self.label[idx])
return data
def __len__(self):
return len(self.input)
dataset = CQADataset(tensor_input_ids,tensor_attention_masks,tensor_labels)
indices = np.arange(len(dataset))
# 訓練データ、評価データに分割
train_dataset = Subset(dataset, indices[:int(len(train_df)*1.0)])
val_dataset = Subset(dataset, indices[-len(val_df):])
from transformers import AutoModelForMultipleChoice
from transformers import Trainer, TrainingArguments
model=AutoModelForMultipleChoice.from_pretrained("studio-ousia/luke-japanese-base")
# トレーニングの設定を記述する
training_config = TrainingArguments(
output_dir = '//desktop//Python//luke_commonsenseqa',
num_train_epochs = 5,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
weight_decay = 0.1,
do_eval = True,
save_steps = 50,
)
# トレーニング
trainer = Trainer(
model = model,
args = training_config,
tokenizer = tokenizer,
train_dataset = train_dataset,
eval_dataset = val_dataset
)
trainer.train()
# モデルの保存
torch.save(model, '\\desktop\\Python\\luke_commonsenseqa\\My_luke_model_common.pth')
print('saved')
モデルの精度
モデルの精度は
80.07149240393296
でした。
従来のSOTAに迫る高い精度でした。
デモ(実行の様子)
サンプルコード
from transformers import AutoTokenizer, AutoModelForMultipleChoice
import torch
import numpy as np
# modelのロード
tokenizer = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa')
model = AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa')
# 質問と選択肢の代入
question = '電子機器で使用される最も主要な電子回路基板の事をなんと言う?'
choice1 = '掲示板'
choice2 = 'パソコン'
choice3 = 'マザーボード'
choice4 = 'ハードディスク'
choice5 = 'まな板'
# トークン化(エンコーディング・形態素解析)する
token = tokenizer([question,question,question,question,question],[choice1,choice2,choice3,choice4,choice5],return_tensors='pt',padding=True)
leng=len(token['input_ids'][0])
# modelに入力するための下準備
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = token['input_ids']
X2[0, :, :] = token['attention_mask']
# modelにトークンを入力する
results = model(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
# 最も高い値のインデックスを取得する
max_result=torch.argmax(results.logits)
print(max_result)
実行結果
tensor(2)
終わりに
今回はJCommonsenseQAを解くためにLUKEをファインチューニングする方法について書いてきました。
しっかり体系化されたサンプルコードがなかったため、執筆現在、CommonsenseQAを解けるモデルは日本語では公開されていませんでした。
そこで、試行錯誤の結果JCommonsenseQAを解けるコードを作成できたので、公開してみました。
この記事が役に立ち、今後ほかのモデルでも、CommonsenseQA用にファインチューニングしたモデルが出ることを祈っています。
では、ばいにゃん~。