こんにちにゃんです。
水色桜(みずいろさくら)です。
今回はLUKEをファインチューニングして、Hugging Faceにアップしたので、そのモデルのデモの様子などについて書いていこうと思います。
作成したモデルはこちらのサイト(Hugging Face)にアップしてあります。
コピペして使えるコード(ディレクトリ名は適宜変更してください)も添えてあるのでぜひ使ってみてください。
本記事を使えば、環境構築(pythonなどのインストール)を除けば、たった2ステップでLUKEで感情分析が行えるようになります。
環境
torch 1.12.1
transformers 4.24.0
Python 3.9.13
sentencepiece 0.1.97
transformersのバージョンが古すぎるとMLukeTokenizerが入ってないので注意してください。
LUKE

2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
日本語バージョンのLUKEは執筆現在(2022年12月)も4つのタスクで最高スコアを有しています。RoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
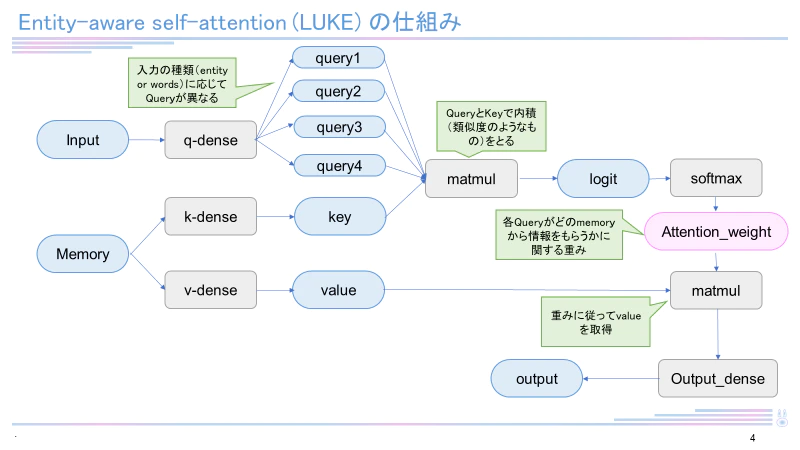
モデルの作成方法
東京工業大学、乾・鈴木研究室の公開している日本語評価極性辞書を用いて、夏目漱石さんの文章(こころ、三四郎、ぼっちゃん、etc)に対してポジティブ・ネガティブのタグ付けを行い、教師データとしました。この教師データをもとに、下記記事と同様の方法でファインチューニングを行い、モデルを作成しました。詳しくは下記の拙著をご覧ください。(分類数を48から2に減らしただけです)
モデルのデモ(たった2ステップで完結!)
追記:短い文章においても精度が高くなるようにモデルを改訂しました(2022年12月27日17時30分)
ステップ1
このサイト(Hugging Face)から、My_luke_model_pn.pthをダウンロードし、任意のディレクトリにおいてください。
ステップ2
その後下記のコードをコピペして、modelを置いたディレクトリを入力してください。あとは実行すれば、感情分析が行えます。
model_exe.py
import torch
from transformers import MLukeTokenizer
from torch import nn
tokenizer = MLukeTokenizer.from_pretrained('studio-ousia/luke-japanese-base-lite')
# この部分を変更してください(modelを置いた場所)
model = torch.load('C:\\[modelのあるディレクトリ]\\My_luke_model_pn.pth')
text=input()
# トークン化します
encoded_dict = tokenizer.encode_plus(
text,
return_attention_mask = True, # Attention maksの作成
return_tensors = 'pt', # Pytorch tensorsで返す
)
pre = model(encoded_dict['input_ids'], token_type_ids=None, attention_mask=encoded_dict['attention_mask'])
SOFTMAX=nn.Softmax(dim=0)
num=SOFTMAX(pre.logits[0])
if num[1]>0.5:
print(str(num[1]))
print('ポジティブ')
else:
print(str(num[1]))
print('ネガティブ')
今日はいろいろな乗り物に乗れて楽しかった
tensor(0.9881, grad_fn=<SelectBackward0>)
ポジティブ
今日は雨が降ってどこにも出かけられなくて最悪だった
tensor(0.0776, grad_fn=<SelectBackward0>)
ネガティブ
終わりに
世界最高精度を達成したことで今話題のLUKEですが、とっつきづらいと感じている方も多いのではないでしょうか?
そこで、今回はたった2ステップで感情分析を行えるようにしてみました。
(個人作成のため企業さんが公開しているモデルほど精度は高くなく、申し訳ないです(スーパーコンピュータが欲しい…>_<))
これを機に、ぜひLUKEを触ってみてください。
素晴らしい技術なので、もっと多くの方にLUKEを知ってほしいと切に願っています。
では、ばいにゃん~。
参考
著者である山田先生には感謝いたします