こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は言語商会・長岡技術科学大学、山本先生の日本語感情表現辞書( https://www.jnlp.org/GengoHouse/snow/d18 )を用いて夏目漱石さんの「こころ」(青空文庫( https://www.aozora.gr.jp/
))の感情分析を行っていきたいと思います。
山本先生のコーパスは単語に対して被験者の3人が48の感情のうちどの感情を感じたかが記されています。このコーパスを用いることで、文章に含まれている最も強い感情を特定することが可能です。
解析結果は次のような感じです。
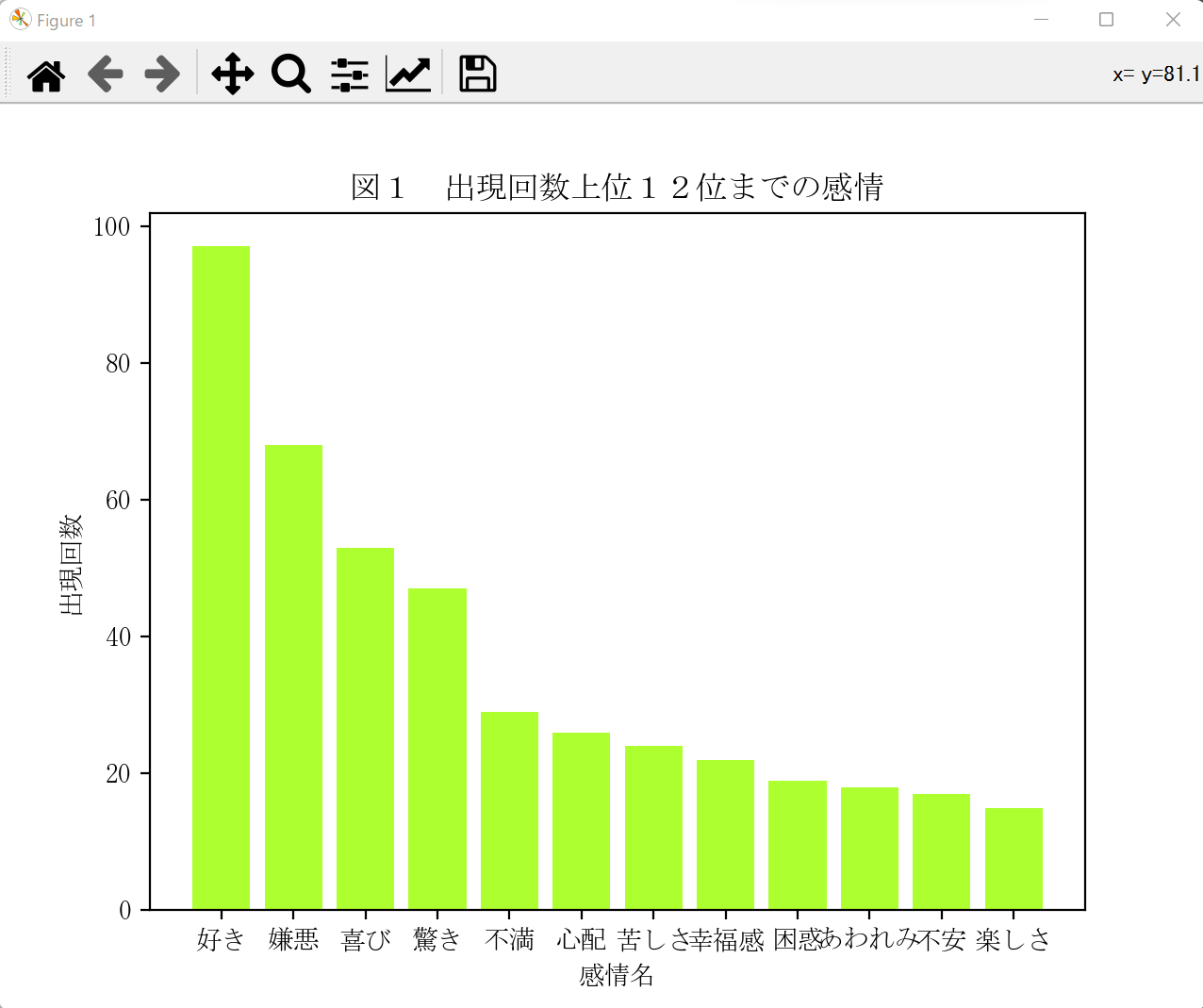
内訳を見ると、好きという感情が最も多く出現していることがわかります。ネタバレになってしまうので詳しくは言えませんが、「こころ」という文章の内容を鑑みると適切な内訳であると感じました。
前置きはこのくらいにしてプログラムの構成について話していきます。
文章の形態素解析には自然言語処理ライブラリGiNZAを用いました。GiNZAはリクルートさんと国立国語研究所さんが開発したものであり、高精度な解析が可能なライブラリです。
形態素解析で単語に分割した後、言語商会・長岡技術科学大学山本先生の日本語感情表現辞書( https://www.jnlp.org/GengoHouse/snow/d18 )に検索をかけます。そして、単語ごとに含まれている感情を抽出し、文全体の感情を計測します。
では早速ソースコードを見てみましょう。
import spacy
import tkinter as tk
import re
import statistics as st
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family']='MS Mincho'
# tkinterを用いてGUIを作成
root = tk.Tk() # ウィンドウを作成
root.title(u'GiNZAによるコメントの感情分析プログラム') # タイトルの定義
root.geometry('500x500') # ウィンドウサイズを定義
frame=tk.Frame(root,bg='red') # テキストボックスなどを載せるフレームを定義
frame.pack() # フレームを設置
sc=tk.Scrollbar(frame) # スクロールバーの定義
sc.pack(side='right',fill='y') # スクロールバーを設置
msgs=tk.Listbox(frame,width=70,height=27,x=0,y=0,yscrollcommand=sc.set,bg='black',fg='white') # テキストボックスの定義
msgs.pack(side='left',fill='both',pady=4) # テキストボックスの設置
msgs.insert('end','分析したいファイル名を入力してください。') # テキストの表示
nlp = spacy.load('ja_ginza_electra') # GiNZAのロード
t=1
def feel(): #ボタンを押したらこの関数を実行
global t #ラベルの位置を決めるための変数
s=textF.get() #入力したテキストを取得
msgs.insert('end',s) #テキスト(ラベル)を設定
t=t+1
textF.delete(0,'end') #テキストボックスの文字を削除
sss=[] # 感情を保持する配列
with open(s,encoding='utf-8') as g1: # テキストファイルの読み込み
g2=g1.read() # テキストファイルを変数に格納
g3=g2.split('\n') # \nで区切る
for j in range(len(g3)):
doc=nlp(g3[j]) #GiNZAによる入力したテキストの解析
words=[]
sen1=[]
for sent in doc.sents: #文章群の中から文章を一つずつ抽出
for token in sent: #文章の中から形態素を一つずつ抽出
words.append(token.lemma_) # 原形を保存
# 感情辞書を用いて感情を検索
with open('長岡技術科学大学_被験者1.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\t|\n',lines) # \nと\tで分割
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]: # 感情辞書にその単語があるか検索
sen1.append(dic[4*i+2]) #リストに追加
sen2=[]
with open('長岡技術科学大学_被験者2.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n|\t',lines)
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]:
sen2.append(dic[4*i+2])
sen3=[]
with open('長岡技術科学大学_被験者3.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n|\t',lines)
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]:
sen3.append(dic[4*i+2])
sen4=sen1+sen2+sen3 # リストを結合
if bool(sen4)==False: # もしリストが空の場合
sen5='' # 空を返す
else:
sen5=st.mode(sen4) #一番出現回数の多い感情を返す
global sen # 感情を保持するリスト
sen=0 # エラーが起きないように一応値を代入しておく
with open ('長岡技術科学大学_感情分類.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n',lines) # \nで分割
for p in range(49):
if dic[2*p+1] in sen5:
sen=dic[2*p] # マッチした感情を代入
sss.append(sen) # リストに追加
ff=np.zeros(49) # 感情の出現回数を保持するリスト
for i in range(len(sss)):
if sss[i]=='安らぎ':
ff[0]=ff[0]+1
elif sss[i]=='楽しさ':
ff[1]=ff[1]+1
elif sss[i]=='親しみ':
ff[2]=ff[2]+1
elif sss[i]=='尊敬・尊さ':
ff[3]=ff[3]+1
elif sss[i]=='感謝':
ff[4]=ff[4]+1
elif sss[i]=='気持ちが良い':
ff[5]=ff[5]+1
elif sss[i]=='誇らしい':
ff[6]=ff[6]+1
elif sss[i]=='感動':
ff[7]=ff[7]+1
elif sss[i]=='喜び':
ff[8]=ff[8]+1
elif sss[i]=='悲しさ':
ff[9]=ff[9]+1
elif sss[i]=='寂しさ':
ff[10]=ff[10]+1
elif sss[i]=='不満':
ff[11]=ff[11]+1
elif sss[i]=='切なさ':
ff[12]=ff[12]+1
elif sss[i]=='苦しさ':
ff[13]=ff[13]+1
elif sss[i]=='不安':
ff[14]=ff[14]+1
elif sss[i]=='憂鬱':
ff[15]=ff[15]+1
elif sss[i]=='辛さ':
ff[16]=ff[16]+1
elif sss[i]=='好き':
ff[17]=ff[17]+1
elif sss[i]=='嫌悪':
ff[18]=ff[18]+1
elif sss[i]=='恥ずかしい':
ff[19]=ff[19]+1
elif sss[i]=='焦り':
ff[20]=ff[20]+1
elif sss[i]=='驚き':
ff[21]=ff[21]+1
elif sss[i]=='怒り':
ff[22]=ff[22]+1
elif sss[i]=='幸福感':
ff[23]=ff[23]+1
elif sss[i]=='恨み':
ff[24]=ff[24]+1
elif sss[i]=='恐れ(恐縮等の意味で)':
ff[25]=ff[25]+1
elif sss[i]=='恐怖':
ff[26]=ff[26]+1
elif sss[i]=='悔しさ':
ff[27]=ff[27]+1
elif sss[i]=='祝う気持ち':
ff[28]=ff[28]+1
elif sss[i]=='困惑':
ff[29]=ff[29]+1
elif sss[i]=='きまずさ':
ff[30]=ff[30]+1
elif sss[i]=='興奮':
ff[31]=ff[31]+1
elif sss[i]=='悩み':
ff[32]=ff[32]+1
elif sss[i]=='願望':
ff[33]=ff[33]+1
elif sss[i]=='失望':
ff[34]=ff[34]+1
elif sss[i]=='あわれみ':
ff[35]=ff[35]+1
elif sss[i]=='見下し':
ff[36]=ff[36]+1
elif sss[i]=='謝罪':
ff[37]=ff[37]+1
elif sss[i]=='ためらい':
ff[38]=ff[38]+1
elif sss[i]=='不快':
ff[39]=ff[39]+1
elif sss[i]=='怠さ':
ff[40]=ff[40]+1
elif sss[i]=='あきれ':
ff[41]=ff[41]+1
elif sss[i]=='心配':
ff[42]=ff[42]+1
elif sss[i]=='緊張':
ff[43]=ff[43]+1
elif sss[i]=='妬み':
ff[44]=ff[44]+1
elif sss[i]=='憎い':
ff[45]=ff[45]+1
elif sss[i]=='残念':
ff[46]=ff[46]+1
elif sss[i]=='情けない':
ff[47]=ff[47]+1
elif sss[i]=='穏やか':
ff[48]=ff[48]+1
nff=np.argsort(ff)[::-1] # 出現回数が多い順に並び替え
# 出現した感情、上位12位まで表示
msgs.insert('end','出現した感情1位は'+dic[2*nff[0]]+'です。出現回数'+str(ff[nff[0]])+'回')
for i in range(48):
if nff[1]==ff[i]:
ni=i
msgs.insert('end','出現した感情2位は'+dic[2*nff[1]]+'です。出現回数'+str(ff[nff[1]])+'回')
for i in range(48):
if nff[2]==ff[i]:
ni=i
msgs.insert('end','出現した感情3位は'+dic[2*nff[2]]+'です。出現回数'+str(ff[nff[2]])+'回')
for i in range(48):
if nff[3]==ff[i]:
ni=i
msgs.insert('end','出現した感情4位は'+dic[2*nff[3]]+'です。出現回数'+str(ff[nff[3]])+'回')
for i in range(48):
if nff[4]==ff[i]:
ni=i
msgs.insert('end','出現した感情5位は'+dic[2*nff[4]]+'です。出現回数'+str(ff[nff[4]])+'回')
for i in range(48):
if nff[5]==ff[i]:
ni=i
msgs.insert('end','出現した感情6位は'+dic[2*nff[5]]+'です。出現回数'+str(ff[nff[5]])+'回')
for i in range(48):
if nff[6]==ff[i]:
ni=i
msgs.insert('end','出現した感情7位は'+dic[2*nff[6]]+'です。出現回数'+str(ff[nff[6]])+'回')
for i in range(48):
if nff[7]==ff[i]:
ni=i
msgs.insert('end','出現した感情8位は'+dic[2*nff[7]]+'です。出現回数'+str(ff[nff[7]])+'回')
for i in range(48):
if nff[8]==ff[i]:
ni=i
msgs.insert('end','出現した感情9位は'+dic[2*nff[8]]+'です。出現回数'+str(ff[nff[8]])+'回')
for i in range(48):
if nff[9]==ff[i]:
ni=i
msgs.insert('end','出現した感情10位は'+dic[2*nff[9]]+'です。出現回数'+str(ff[nff[9]])+'回')
for i in range(48):
if nff[10]==ff[i]:
ni=i
msgs.insert('end','出現した感情11位は'+dic[2*nff[10]]+'です。出現回数'+str(ff[nff[10]])+'回')
for i in range(48):
if nff[11]==ff[i]:
ni=i
msgs.insert('end','出現した感情12位は'+dic[2*nff[11]]+'です。出現回数'+str(ff[nff[11]])+'回')
# 棒グラフを生成
left=np.array([1,2,3,4,5,6,7,8,9,10,11,12])
height=np.array([ff[nff[0]],ff[nff[1]],ff[nff[2]],ff[nff[3]],ff[nff[4]],ff[nff[5]],ff[nff[6]],ff[nff[7]],ff[nff[8]],ff[nff[9]],ff[nff[10]],ff[nff[11]]])
label=[dic[2*nff[0]],dic[2*nff[1]],dic[2*nff[2]],dic[2*nff[3]],dic[2*nff[4]],dic[2*nff[5]],dic[2*nff[6]],dic[2*nff[7]],dic[2*nff[8]],dic[2*nff[9]],dic[2*nff[10]],dic[2*nff[11]]]
plt.bar(left,height,tick_label=label,align='center',color='#ADFF2F')
plt.title('図1 出現回数上位12位までの感情')
plt.xlabel('感情名')
plt.ylabel('出現回数')
plt.show()
#ボタンとテキストボックスの定義
btn=tk.Button(root,text='送信',font=('utf-8_sig',10),bg='cyan',command=feel)
btn.pack(side='right')
textF=tk.Entry(root,font=('utf-8_sig',15),width=40)
textF.pack(side='right')
#画面の保持
root.mainloop()
流れは先ほど説明したとおりです。
for j in range(len(g3)):
doc=nlp(g3[j]) #GiNZAによる入力したテキストの解析
words=[]
sen1=[]
for sent in doc.sents: #文章群の中から文章を一つずつ抽出
for token in sent: #文章の中から形態素を一つずつ抽出
words.append(token.lemma_) # 原形を保存
まずGiNZAで文章の解析を行い、
# 感情辞書を用いて感情を検索
with open('長岡技術科学大学_被験者1.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\t|\n',lines) # \nと\tで分割
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]: # 感情辞書にその単語があるか検索
sen1.append(dic[4*i+2]) #リストに追加
sen2=[]
with open('長岡技術科学大学_被験者2.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n|\t',lines)
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]:
sen2.append(dic[4*i+2])
sen3=[]
with open('長岡技術科学大学_被験者3.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n|\t',lines)
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]:
sen3.append(dic[4*i+2])
その文章の持つ感情を辞書から取得します。あとは感情の出現回数を記録してグラフとして表示するだけです。
意外と簡単だと思われたのではないでしょうか?
もしよろしければ皆さんもいろいろな文章の感情分析を行ってみてください。
ではばいにゃん~