はじめに
こんにちは。
突然ですが、
VTuber
になりたいんですよね。

VTuberになって、あわよくばにじさんじに入って、YouTube収入とかスパチャとかで稼ぎつつ、承認欲求を満たしたい・・・。
けど、VTuberって
- モデルの用意
- かっこかわいいボイス
- なんかモデル動かす
- カメラキャプチャ??
- 歌が歌える
- 配信とか時間かかる
- etc....
特にめちゃくちゃ調べたわけじゃないですけど、とても大変そうですよね。
ハードやソフトを揃えるだけじゃなくて本人のスキルも磨かなければなりません。
本当にVTuberの皆様ってすごいんだなと痛感します。
そもそも本職をおろそかにできないので、特にスキルを磨く時間がないんですよね。
となると、やはり
全てAIにやらせよう(錯乱)
と思うわけです。
なので、今回は自分がAIになる記事になります。
最後にはVTuber第一歩となる動画も用意しておりますので、よければご覧ください。
共同開発者
@kdr250
@ko27
@39yatabis
@hrkmed
目次
概要
今回も時間がないので、既存のサービスを作っていきます。
使用するサービスは目次にも挙げていますが、下記の通りです。
- UE4
- Azure Text to Speech
- OVR LipSync
- META HUMAN
それぞれ細かい説明は後に記述いたします。
VTuber第一歩として、今回は
自分が3Dモデルになって、言語を発する
ところを目標としております。
では、早速やっていきましょう。
AIになる
構成図
ざっと使用するサービスの構成図は下記の通りです。

ざっくりと流れとしましては下記の通りです
- 適当なテキストを用意
- APIを用意してテキスト・性別をXML形式に変換
- Text to Speechで音声化
- APIでmp3からBase64エンコードしたwav形式に変換
- 音声からOVR Lipsyncを用いて口の動きを再現
- META HUMANで用意した3Dモデル(俺)に読み込ませて、喋らせる
UE4

本企画の要です。
3D制作プラットフォームです。主にゲームエンジンとして利用されますが、最近ではノンゲーム分野でも注目を集めています。
今回はこのエンジン上でテキスト入力を検知して、APIにデータを渡したり、METAHUMANにLipSyncを読み込ませたりすることで、俺モデルを作成していきます。
VaRest
UEでAPIを叩くプラグインです。
今回はバックエンドAPIを叩いて音声を取得するのに使用しています。
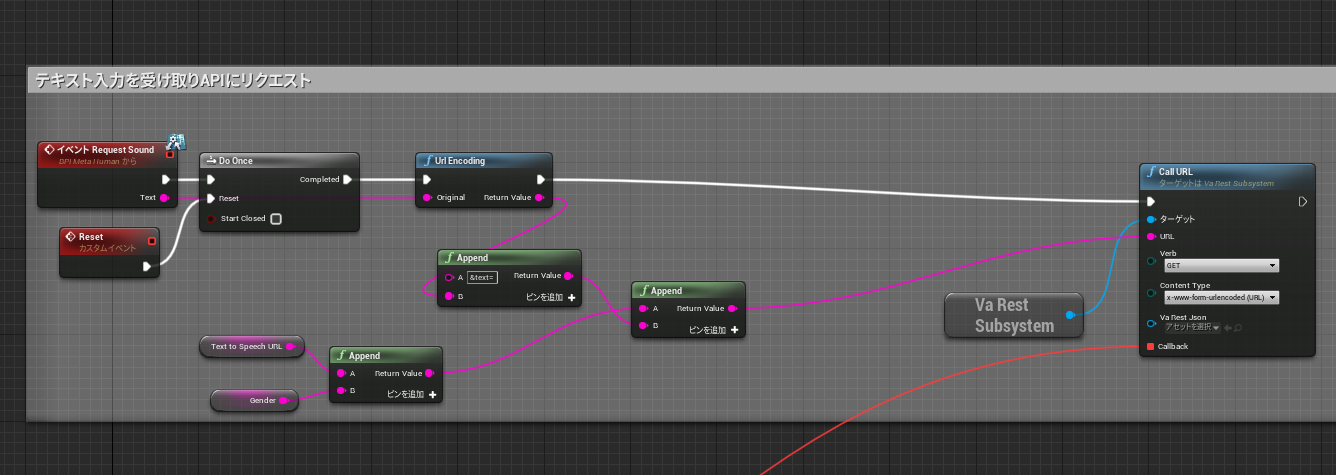
テキスト入力を受け取り、バックエンドAPIにリクエストしています。
実際に動かしているBlue Printが下記の通りです。
※Blue Print・・・UnrealEngine内でプログラムを作るためのツールみたいなもので、ビジュアルスクリプティングシステムと言う仕組みを採用したツールです。ビジュアルスクリプティングシステムとは、その名の通り視覚的にプログラムを作成する仕組みのことです。
https://tech.pjin.jp/blog/2019/10/23/ue4_blueprint_01/
Runtime Audio Importer
アプリ起動中に動的に音声処理するプラグインです。
今回はバックエンドAPIより取得した音声を処理するために使用しています。
実際に動かしている部分のBlue Printが下記の通りです。

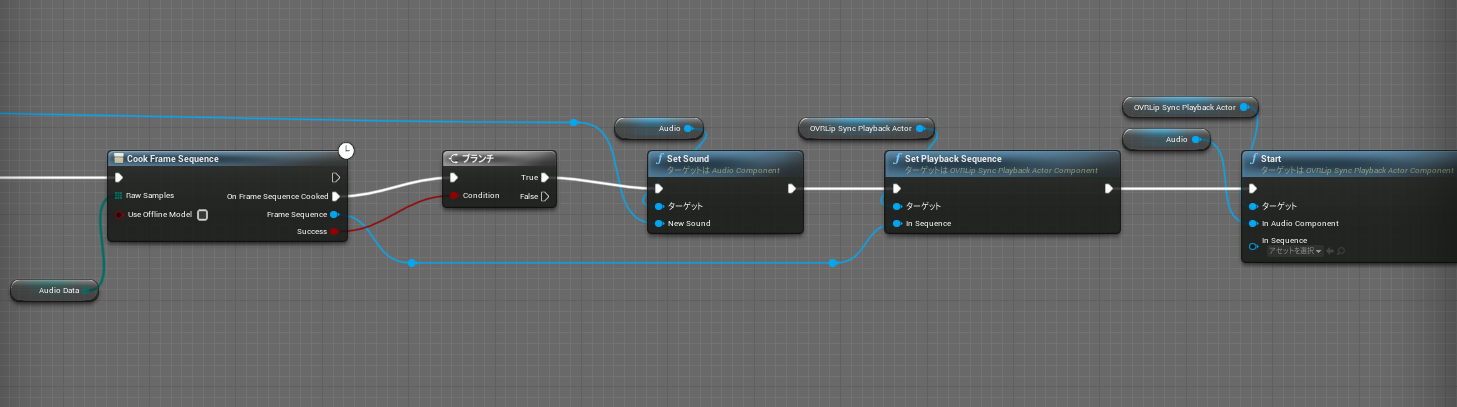
OVR LipSync
Oculusのリップシンク用プラグインです。
今回はMetaHumanをリップシンクさせるために使用しています。
俺モデルの口を動かして、あたかもそこに俺がいるかのような錯覚を生み出します。
プラグイン適用させているBlue Printが下記の通りです。
META HUMAN
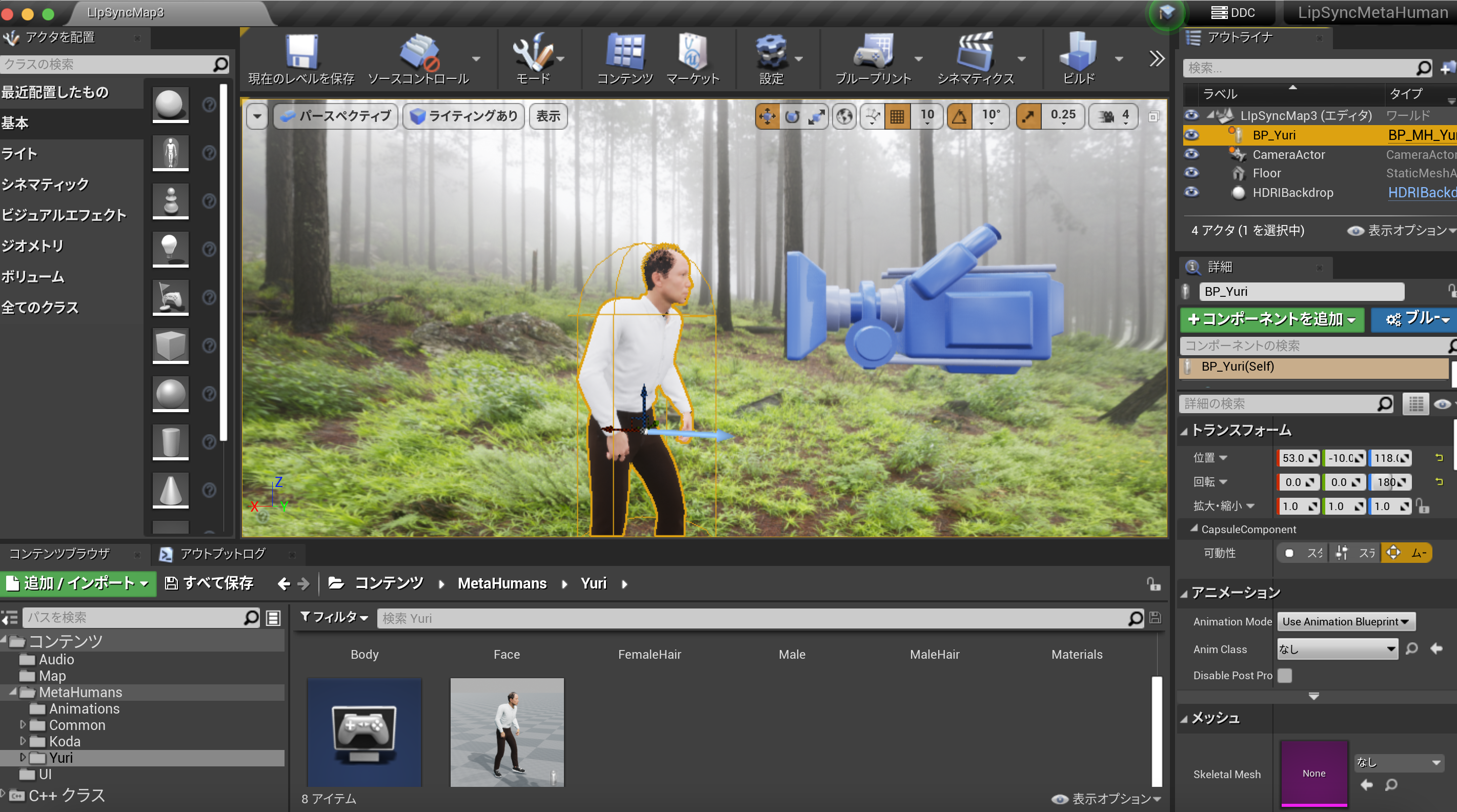
META HUMANはUEのフレームワークで、フォトリアルな人間キャラクターの3Dモデルを作ることができます。
つまり俺の生みの親であるわけです。
生成したモデルをUEにインポートすることも可能です。
MetaHumanにより作られた3Dモデルがこちらです。

のちに掲載する動画にはPCへの負荷の都合上、左下のおじさんを使用しています。
Azure Text to Speech
テキストから音声データへの変換は Microsoft Azure の Text to Speech API を利用しました。
アカウント登録し、トークンを発行して以下のようなリクエストを送ると、レスポンスで音声データを返してくれます。
テキストや声の種類などを独自の SSML という形式で指定することができます。
curl --location --request POST "https://${SPEECH_REGION}.tts.speech.microsoft.com/cognitiveservices/v1" \
--header "Ocp-Apim-Subscription-Key: ${SPEECH_KEY}" \
--header 'Content-Type: application/ssml+xml' \
--header 'X-Microsoft-OutputFormat: audio-16khz-128kbitrate-mono-mp3' \
--header 'User-Agent: curl' \
--data-raw '<speak version='\''1.0'\'' xml:lang='\''ja-JP'\''>
<voice xml:lang='\''ja-JP'\'' xml:gender='\''Female'\'' name='\''ja-JP-NanamiNeural'\''>
日本語の音声を話すテストです。
</voice>
</speak>'
今回はこれを UE から呼び出さないといけなかったため、中継サーバーを立てて UE 側の処理の負担を減らすようにしました。
UE の VaRest は API のレスポンスを String でしか受け取れないため、Text to Speech API のレスポンスを中継サーバーで base64 エンコードして返しています。
中継サーバーは適当に Python で書きました。
参考までに以下
from base64 import b64encode
import os
from fastapi import FastAPI, Response
import requests
URL = os.getenv(“URL”) # Azure のリクエストURL
SPEECH_KEY = os.getenv(“SPEECH_KEY”) # Azure のトークン
app = FastAPI()
@app.get("/tts")
def main(response: Response, gender: str, text: str):
headers = {
"Ocp-Apim-Subscription-Key": SPEECH_KEY,
"Content-Type": "application/ssml+xml",
"X-Microsoft-OutputFormat": "riff-16khz-16bit-mono-pcm"
}
payload = f"<speak version='1.0' xml:lang='ja-JP'>\
<voice xml:lang='ja-JP' xml:gender='{gender}' name='{'ja-JP-KeitaNeural' if gender == 'Male' else 'ja-JP-NanamiNeural'}'>\
{text}\
</voice>\
</speak>"
r = requests.post(URL, headers=headers, data=payload.encode("utf-8"))
response.headers["Content-Type"] = "text/plain"
return b64encode(r.content)
結果
ここまでで、テキストを入力しその言葉を発する俺モデルが完成しました。
実際に動いている動画も作成致しましたのでご覧ください。
おわりに
VTuberへの道は長い
参考文献
-
UEについて
-
Azure Text to Speechについて
-
META HUMANについて
-
OVR Lipsyncについて