PythonでSUUMOデータ分析し、”データで「お買い得」物件”を見つける
理想は「相場より割安な、良い中古戸建」を見つけること。誰もが割安物件には関心があるはずです!!
しかし、毎日大量の物件情報を追い、本当に「相場より安いか」を見抜くのは至難の業。
時間がかかり、見落としたり、「なんとなくお得かも」という曖昧な判断に頼ってしまったりしていませんか?
- その価格、本当に物件の条件に見合っている?
- 見た目の安さの裏に、再建築不可のような致命的リスクはないか?
- データで客観的に「割安度」を判断する方法はないのか?
これらの課題を解決するため、
今回は Pythonを使ってSUUMOの物件データを分析し、「割安度を判定する仕組み」 を構築した過程を紹介していきたいと思います。
この記事を読めば、あなたの物件探しは「勘」から「データ」へ、きっと変わるはずです。
この分析で目指したもの:「データが示す割安物件」の発掘
目的は
「データに基づき、相場と比較して割安な中古戸建を効率的に見つけ出す」 こと。
具体的には、以下のステップをおこないました。
- SUUMOから中古戸建ての情報を自動収集
- 駅の利用者数のデータを収集
- 駅距離、面積、築年数、周辺相場など、価格に影響する要因を数値化
- 機械学習(重回帰分析)で、物件ごとの 「データが予測する適正価格」 を算出
- その予測価格と実際の販売価格を比較し、 「割安度・割安率」 を算出
「なんとなく安い」ではなく、「データ分析の結果、〇〇%割安と判定された」物件をリストアップできるようにしていきたいと思います。
データ分析から得た重要な気づき
今回の分析をおこなった結果、
「割安率」の高い物件を見つけることができました!!
しかし、その物件を確認してみると、多くには明確な「安い理由」が潜んでいました。
残念ながら、データ上の「割安物件」の多くは、価格が低いなりの構造的・法的要因を抱えていました。
例えば、以下のようなケースです。
- 再建築不可物件: 現行法では同じ場所に再建築できない土地。
- 接道義務未達の土地: 再建築が難しい場合が多い。
- 旗竿地: 日照やプライバシー面で敬遠されがちな土地。
今回の分析モデルでは、
物件詳細のテキスト情報(「再建築不可」等の記述)までは特徴量として組み込めていなかったため
これらがデータ上は「単に価格が安い物件」として現れてしまいました。
この経験から得られた教訓は以下の2点になります。
-
データ分析は、「相場とのズレ」を表す強力なツールである
経験や勘(なんとなく)に頼りがちだった「相場観」をデータにし、効率的に候補物件をスクリーニングできます。 -
データが示す「割安」が、即「投資に適したお買い得物件」とは繋がらなかった
価格が安い背景には法的制限や物理的リスクが隠れている。
物件ごとに調査が必要。
データ分析は絶対ではない!!
あくまで物件を効率的に見つけ出すための「第一歩の発見ツール」。
発見ツールとしては申し分ない。そして出た割安物件から得られる洞察と、現実の物件に対する理解(目利き力)は必要だと感じました。
分析の全体フローと使用したPythonコード
ここからは、実際にどのような手順でデータ分析を行い、上記の結論までに至ったのかを説明していきます。
不動産投資に興味があるけれどPythonはこれから、という方にも分かりやすいように、そして不動産投資の視点も交えながら書いていきたいと思います。
今回の分析対象は愛知県内の中古戸建てデータです。
分析の大きな流れ
- データの準備: 分析に必要な情報を集め、Pythonで扱える形にします。
- データの前処理・加工: 物件価格に影響を与えそうな情報(特徴量)を抽出し、機械が理解しやすい数値データに変換します。
- モデルの構築と学習: 物件データを使って、価格を予測するAIモデル(機械学習モデル)を作ります。
- モデルの評価: 作成したモデルがどの程度正確に価格を予測できるかを確認します。
- 割安物件の判定: モデルの予測価格と実際の価格を比較し、割安な物件をランキング化します。
1. データ読み込みとその背景
今回は、主に2つのCSVファイルを用意しました。
-
suumo_results.csv:
SUUMOから収集した愛知県中古戸建ての生データです。
価格、所在地、面積、築年数、交通といった価格に影響する基本情報を抽出しています。
データの抽出の流れは前回記事にしていますので下記をご覧ください。
https://qiita.com/Mitz_AI/items/f03d185bb16de1b9ebc2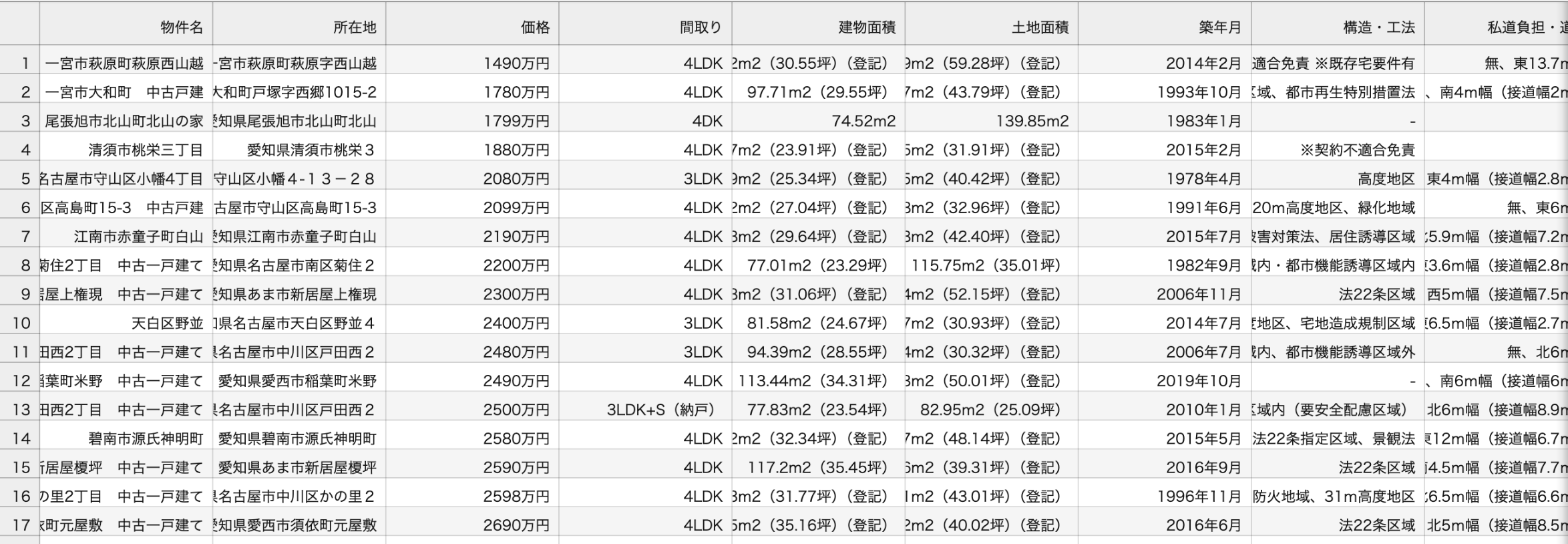
-
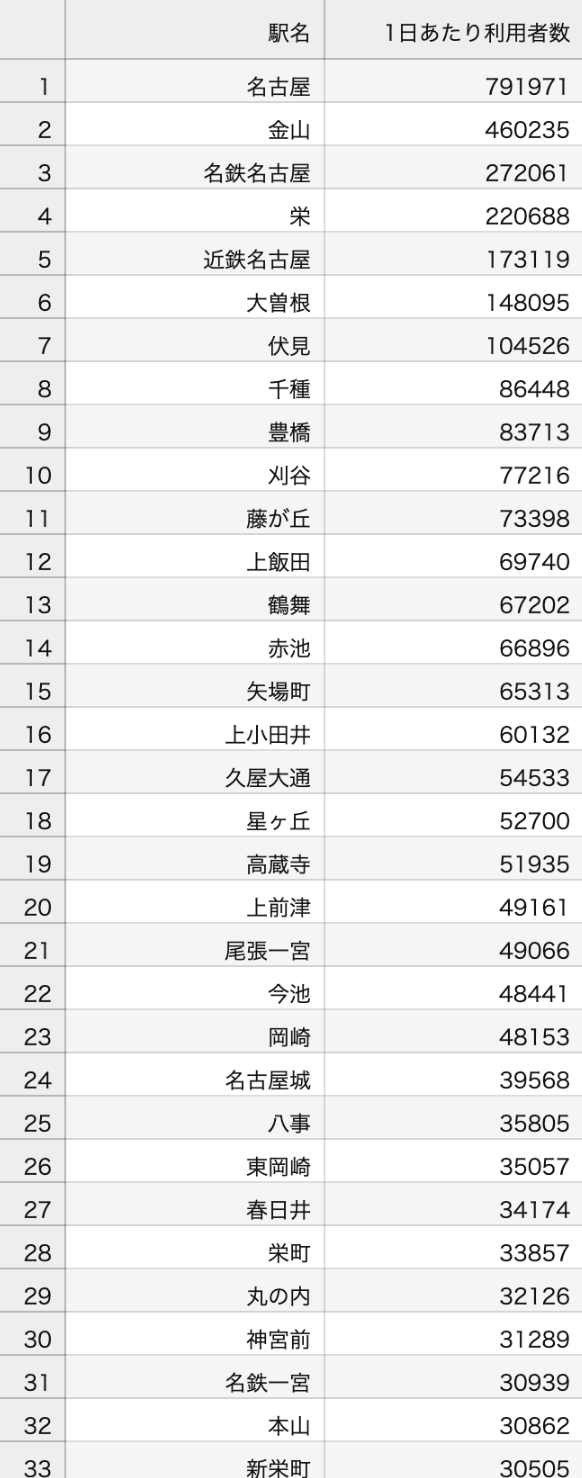
station_score_top100.csv:
愛知県内の1日の利用者数のデータを抽出したものです。
利用者数の多い駅・人気の駅は駅自体が価格に影響すると考え、後ほどこのデータを「駅スコア」のような独自の指標を作成していきます。
公開されている情報だけでは見えてこない物件の価値を評価軸に加えることでより現実に近い評価できると考えています。
SUUMOから収集した物件データ(CSVファイル)を読み込みます
df = pd.read_csv("suumo_results.csv")
駅のスコアデータ
df_score = pd.read_csv("station_score_top100_only_cleaned_final.csv")
import pandas as pd
import numpy as np
import re
df = pd.read_csv("suumo_results.csv")
df_score = pd.read_csv("station_score_top100.csv")
データ分析の第一歩は、信頼できるデータを できるだけ多く 集め、プログラムで扱える形にすること

2. 交通情報から「駅名」「徒歩分数」を抽出
物件の価格を左右する最重要要素の一つが「立地」
特に「最寄り駅」と「駅からの距離」です。
SUUMOのデータから「駅名」と「徒歩分数」を個別のデータとして抽出していきます。
def extract_eki_toho(text):
match = re.search(r'「(.+?)」歩(\d+)分', str(text))
if match:
eki = match.group(1)
toho = int(match.group(2))
return pd.Series([eki, toho])
else:
return pd.Series([None, None])
df[["駅名だけ", "徒歩分"]] = df["交通"].apply(extract_eki_toho)
df["駅名だけ"] = df["駅名だけ"].astype(str) + "駅"

3. 駅スコアをマッピング
単に最寄り駅からの距離だけでなく、駅のブランドや人気駅・人気路線なども物件価格に影響すると考えました。
用意しておいた「駅のランキング」を、各物件の最寄り駅に紐付けます。
これにより、「主要駅に近い物件は価値が高い」といった傾向をモデルに学習させることができます。
score_col = '駅スコア(1〜10点)'
df_score_top = df_score[df_score[score_col] >= 1]
if df_score_top.empty:
print(f"スコア1以上の駅がない")
score_map = {}
else:
score_map = df_score_top.set_index("駅名")[score_col].to_dict()
print("\n")
temp_eki_names = df['駅名だけ'].str.rstrip('駅')
mapped_scores = temp_eki_names.map(score_map)
df["駅スコア"] = mapped_scores.fillna(0.5)
データだけでは表現できない「駅のブランド力」を複数の情報を組み込むことで、より現実な価格予測が期待できます。
物件そのもののスペックだけでなく、周辺環境の質も重要な評価ポイントです。

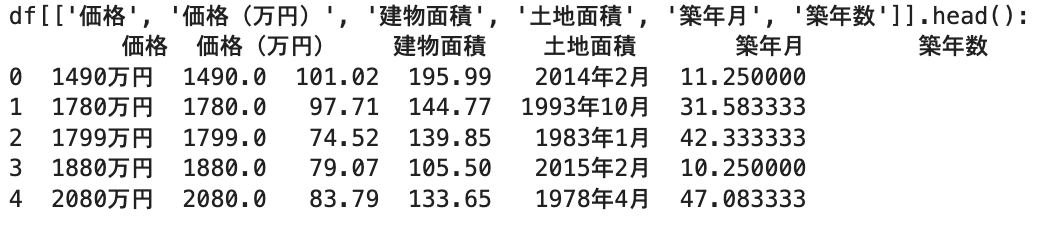
4. 価格・面積・築年数の数値化
物件価格、建物面積、土地面積、築年数は、不動産価格を決定づける最も基本的な要素です。
SUUMOのデータでは、価格が「〇〇万円」や「〇億円〇〇万円」、面積が「〇〇m2」、築年月が「〇〇年〇月」といった形式で記載されているため、これらを計算に使える数値に変換する必要があります。
def parse_price(price_str):
price_str = str(price_str)
if "億" in price_str:
match = re.match(r"(\d+)億(\d*)万円?", price_str)
if match:
oku = int(match.group(1)) * 10000
man = int(match.group(2)) if match.group(2) else 0
return oku + man
else:
match = re.match(r"(\d+)万円?", price_str)
if match:
return int(match.group(1))
df["価格(万円)"] = df["価格"].apply(parse_price)
def parse_area(text):
match = re.match(r"([\d.]+)m2", str(text))
if match:
return float(match.group(1))
df["建物面積"] = df["建物面積"].apply(parse_area)
df["土地面積"] = df["土地面積"].apply(parse_area)
def calc_age(text):
match = re.match(r"(\d{4})年(\d{1,2})月", str(text))
if match:
year, month = int(match.group(1)), int(match.group(2))
current_year = 2025
current_month = 5 #
return (current_year - year) + (current_month - month) / 12
df["築年数"] = df["築年月"].apply(calc_age)
ポータルサイトの情報は、人間には分かりやすくても形式が統一されていないことが多々ありました。
例えば価格表記一つとっても「万円」だけの場合と「億」が入る場合があるなど、、、
初めは万円の前の数字を抽出していましたが『億』が入っているのは抽出できない。
『億』だけを取り除くようにしたら、キリのいい1億の物件はエラーが出てしまいこの方法に行きつきました。
5. エリアごとで平均価格を作る
物件が「どのエリアにあるか」が価格に大きく影響します。
例えば、同じ広さ・築年数の物件でも、都心の一等地と郊外では価格が全く異なります。
名古屋市内は区ごとに、それ以外は市の平均物件価格を算出し、それを各物件の特徴量として加えます。
初めは市ごとで平均していたんですが、中区と港区では坪単価が大きく違うので名古屋市のみは区ごとに分けることにしました。
これによってモデルは物件が所在するエリアの一般的な価格水準を考慮できるようになります。
def extract_city(text):
text = str(text)
if "名古屋市" in text:
match = re.search(r"名古屋市(.+?区)", text)
if match:
return "名古屋市" + match.group(1)
else:
match = re.search(r"愛知県(.+?[市区町村])", text)
if match:
return match.group(1)
df["市区町村_詳細"] = df["所在地"].apply(extract_city)
df["市区町村平均価格"] = df.groupby("市区町村_詳細")["価格(万円)"].transform("mean")
「この物件は、このエリアの平均と比べてどうなのか?」という視点をモデルに持たせることができます。

エリアの坪単価・平米単価から平均を出したほうが良かったと後から気づいています。
次回、『エリア別平米単価』を加えてみたいと思います。
6. 立地スコアと価格の対数変換
より精度の高い価格予測を目指し、既存の情報を組み合わせて新しい特徴量を作成したりデータ調整を行います。
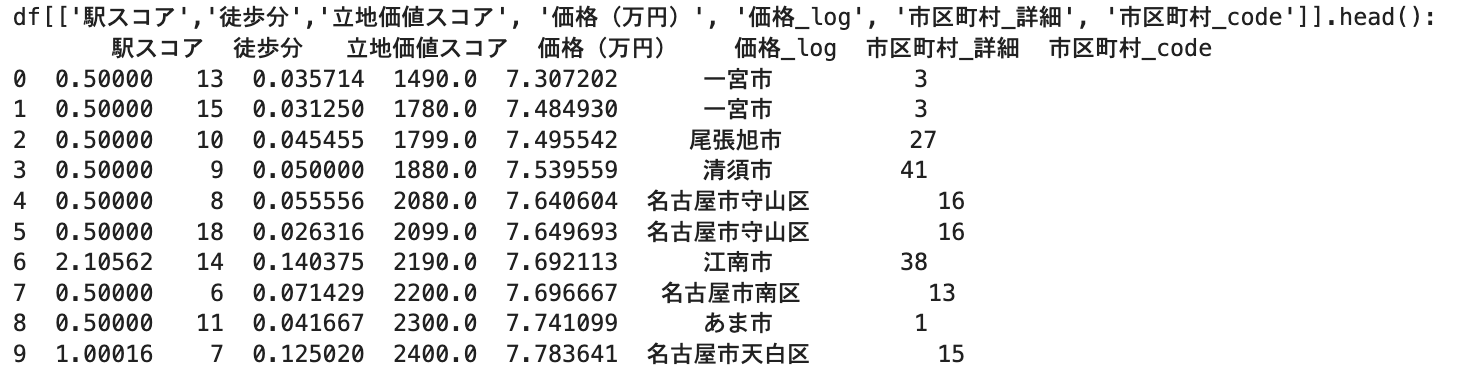
-
立地価値スコアの作成: 駅の魅力(駅スコア)と駅からの距離(徒歩分)を総合的に評価するため、「
駅スコア / (徒歩分数 + 1)」という計算式で新たな指標を作成。
駅スコアが高く、かつ徒歩分数が短いほど高価値となります
(分母に+1しているのは、徒歩分数が0の場合に計算エラーになるのを防ぐため)。 -
市区町村コードの作成:
「市区町村_詳細」のような地名(例:「名古屋市中区」「豊田市」)は文字列データのため、そのままでは機械学習モデルが計算処理に利用できません。そこでLabelEncoderという機能を使って、各市区町村名をそれぞれ異なる数値ID(例:「名古屋市中区」を0、「豊田市」を1など)に変換します。
このように数値に置き換えることで、モデルはそれぞれのエリアを区別し、地域ごとの価格傾向を特徴量として学習できるようになります。
df["立地価値スコア"] = df["駅スコア"] / (df["徒歩分"].fillna(df["徒歩分"].mean()) + 1)
df["価格_log"] = np.log(df["価格(万円)"] + 1)
le_city = LabelEncoder()
df["市区町村_code"] = le_city.fit_transform(df["市区町村_詳細"])
7. 説明変数と目的変数の準備
機械学習モデルに「何を材料(説明変数)にして、何を予測させるか(目的変数)」を教える準備をしていきます。
-
説明変数 (X): 物件価格を説明・予測するために使う情報。
今回は、これまで加工・作成してきた「建物面積」「土地面積」「築年数」「徒歩分」「駅スコア」「立地価値スコア」「市区町村平均価格」「市区町村_code」を選びました。
これらが物件の価格を左右する要因(特徴量)であるという仮説に基づいています。 - 目的変数 (y): モデルに予測させたい対象、今回は「価格_log」になります。
features = [
"建物面積", "土地面積", "築年数", "徒歩分", "駅スコア",
"立地価値スコア", "市区町村平均価格", "市区町村_code"
]
target = "価格_log"
cols_to_fill_mean = ['建物面積', '土地面積', '築年数', '徒歩分', '駅スコア', '市区町村平均価格', '立地価値スコア']
for col in cols_to_fill_mean:
if col in df.columns and df[col].isnull().any():
df[col].fillna(df[col].mean(), inplace=True)
df_model = df[features + [target]].dropna()
X = df_model[features]
y = df_model[target]
どの情報を説明変数として使うか
どの情報が目的変数に影響を与えるのかは、分析の良し悪しを分ける重要なポイントです。
不動産の知識を活かし、「価格に影響を与えそうな要因は何か?」を考えることが必要となります。
8. 外れ値除去(3σ法)
物件データには、事故物件や特別な豪邸など、相場から極端にかけ離れた「外れ値」が時折含まれます。これらはモデルの学習に過度な影響を与え、一般的な物件への予測精度を低下させる恐れがあるため、統計的手法「3σ(さんシグマ)法」で対処します。
この手法では、各説明変数の値がその平均から標準偏差の約3倍以上離れているデータを外れ値とみなし、分析対象から除去します。
mean = X.mean()
std = X.std()
X_filtered = X.copy()
for col in X.columns:
low = mean[col] - 3 * std[col]
high = mean[col] + 3 * std[col]
X_filtered = X_filtered[(X_filtered[col] > low) & (X_filtered[col] < high)]
y_filtered = y[X_filtered.index]

9. モデル構築(線形回帰)と学習
ここからは
準備したデータを使って、物件価格を予測するAIモデル(機械学習モデル)を構築し、学習させていきます。
モデル学習の主なステップ:
-
データの分割 (Train-Test Split):
モデルの本当の性能を評価するため、手持ちのデータを「訓練用データ(モデルの学習用)」と「テスト用データ(学習済みモデルの性能評価用)」に分割します。 -
データの標準化 (Standardization):
建物面積(m²単位)、築年数(年単位)、駅スコア(点数)など、各説明変数は単位や数値の範囲が異なります。
このままでは学習が不安定になるため、各特徴量を平均0、標準偏差1に揃える「標準化」を行います。
これにより、モデルが安定して効率的に学習できるようになります。 -
モデルの学習:
LinearRegressionモデルを用意し、標準化済みの訓練用データを使って学習させます。
このプロセスで、モデルは価格を予測するための内部的な計算式(パラメータ)を調整していきます。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X_filtered, y_filtered, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model = LinearRegression()
model.fit(X_train_scaled, y_train)
モデル評価
ついに、学習させたモデルが、どの程度「使える」ものなのかを評価していきます。
-
決定係数 ($R^2$スコア): モデルが目的変数(価格の対数値)のばらつきを、どれだけ説明できているかを示す指標です。
0から1の値をとり、1に近いほど予測精度が高いことを意味します。 -
MAE (Mean Absolute Error): 平均絶対誤差。
予測価格と実際の価格の差を取り、その平均を計算したものです。
MAEが0.1なら、実際の価格と予測価格が平均して0.1程度ずれている、という意味になります。
元の価格スケールに戻して解釈すると、より具体的に「平均して〇〇万円くらい予測がズレる」かが掴めます。
from sklearn.metrics import mean_absolute_error
train_score = model.score(X_train_scaled, y_train)
test_score = model.score(X_test_scaled, y_test)
print(f"訓練スコア(R^2): {train_score:.4f}")
print(f"テストスコア(R^2): {test_score:.4f}")
y_pred_test = model.predict(X_test_scaled)
mae_test = mean_absolute_error(y_test, y_pred_test)
print(f"テストデータのMAE(対数価格ベース): {mae_test:.4f}")
モデルの評価は非常に重要です。
訓練スコアだけが高くてもダメで、
テストスコアが低い場合は「過学習」を起こしている状態、物件に対しては使えないモデルという可能性が高くなります。
今回の結果では、訓練スコアとテストスコアがある程度近い値になっているため、極端な過学習は起きていないと判断しました。
MAEは、モデルの予測誤差が具体的にどの程度なのかを把握できます。
「予測のズレ幅」が許容範囲内かどうかが、このモデルを実務で活用できるかの判断材料の一つとなります。
決定係数とMAEの両方を見ることで、モデルの性能を多角的に評価できます。

重み(係数)の確認
学習済み線形回帰モデルの「係数(model.coef_)」は、各説明変数が物件価格にどの程度、プラスかマイナスかに影響を与えるかを出してくれます。。
coefs = pd.DataFrame({
"特徴量": features,
"係数": model.coef_
})
print(coefs.sort_values("係数", key=abs, ascending=False))
係数を見ることで、「価格形成のメカニズム」の一端を垣間見ることができます!
例えば、
「建物面積」や「土地面積」の係数が正の値なので、やはり広さが価格に強く影響していることがデータからもわか流と思います。
「築年数」の係数が負の値なので、古いほど価格が下がる傾向を示します。
今までの経験が実際にどの要素が価格に関係するかを、データで客観的に確認したり、あるいは新たな発見に繋げたりするヒントが得られます。

割安ランキング出力
いよいよ最終目的である「割安物件ランキング」の作成になります。
学習させたモデルを使って、全物件データに対して「予測価格」を算出します。
その予測価格と実際の「販売価格」を比較、予測価格よりも実際の価格が安い物件=割安物件としてリストアップします。
X_all_scaled = scaler.transform(X)
df.loc[X.index, "予測価格_log"] = model.predict(X_all_scaled)
df["予測価格(万円)"] = np.expm1(df["予測価格_log"])
df["割安度"] = df["予測価格(万円)"] - df["価格(万円)"]
df["割安率(%)"] = df["割安度"] / df["予測価格(万円)"] * 100
cheap_df = df.loc[X.index].sort_values("割安率(%)", ascending=False).head(5)
cheap_df.to_csv("割安物件ランキング.csv", index=False)
この「割安物件ランキング」が今回の成果物になります。
このリストを元に、実際に物件の詳細情報を確認したり、現地調査を行ったりすることで、本当に「お買い得」な物件に出会える可能性が高まると思います!
効率的な物件探しの第一歩のスクリーニングツールとしては良い出来になったのではないかと考えています。

💡 今回の価格予測に使用した特徴量まとめ
| 特徴量 | 内容 | 不動産投資における意味 |
|---|---|---|
| 建物面積 | m²単位に変換済。 | 広さは価格に直結する基本的な要素。 |
| 土地面積 | m²単位に変換済。 | 特に戸建ての場合、土地の広さも価格に大きく影響。 |
| 築年数 | 記事執筆時点(2025年5月)から逆算した経過年数。 | 一般的に古いほど価格は下落する傾向。 |
| 徒歩分 | 数値化した最寄り駅からの徒歩時間。 | 駅からの距離は利便性に直結し、価格への影響大。 |
| 駅スコア | 駅の利用者数などを基にした独自の利便性スコア(1~10点)。 | 駅自体の持つポテンシャル、ブランド力を反映。 |
| 立地価値スコア | 駅スコアと徒歩分を組み合わせた複合的な立地指標(駅スコア / (徒歩分+1))。 | 駅の質と距離の両方を考慮した、より実践的な立地評価。 |
| 市区町村平均価格 | 物件が所在する市区町村(名古屋市は区単位)の平均物件価格。 | エリアの相場観をモデルに伝える。同じスペックでもエリアによって価格は大きく異なるため重要。 |
| 市区町村_code | 市区町村名を数値IDに変換したもの。 | 機械学習モデルがエリア情報を扱えるようにするための処理。 |
この分析の改善点と次のステップ
今回の分析は、データで「割安ではある物件」を発見することができました。
しかし、安いのには理由がある。
その物件を自動で判別するためにはさらに改善が必要だと強く感じました。
単に安いだけでなく
リスクが低く、本当に投資したくなる・購入したくなる物件を見つけ出して行けるようにしていきたいと思います。
検討中の改善アイデアは以下の通りです。
| 改善アイデア | 内容 | 不動産投資家にとってのメリット |
|---|---|---|
| 備考欄や物件詳細のテキスト解析 | 「再建築不可」「建築条件付き」「私道負担」「心理的瑕疵」などのリスクキーワードを自然言語処理で検出。 | これにより、データ上は割安に見えても実際には手が出せない物件を自動的にフィルタリングし、より質の高い割安物件リストを作成できる。 |
| 接道情報の数値化 | 前面道路の幅員や接道長、道路種別(公道・私道など)をデータとして取得・加工し、モデルに加える。 | 再建築の可否や建てられる建物の大きさに直結する重要な情報。これが分かれば、より正確な物件評価とリスク判断が可能になる。 |
| ハザードマップとの連携 | 浸水区域、土砂災害警戒区域などのリスク情報を物件所在地と紐付けて特徴量にする。 | 自然災害リスクを事前に評価し、長期的な資産価値維持の観点から安全な物件を選びやすくなる。 |
| 他のデータソースの活用 | 土地の公示価格・基準地価、周辺施設の情報(スーパー、学校、病院までの距離など)、都市計画情報(用途地域など)を組み合わせる。 | より多角的な情報から物件価値を評価し、将来性や生活利便性なども考慮した投資判断が可能になる。 |
これらの要素を取り込むことで、 単に「相場より安い」だけでなく、「リスクが少なく、投資対象として検討に値する割安物件」 を絞り込める可能性が高まります。
まとめ:データ分析で不動産投資と今後の展望
今回のPythonを使ったSUUMOデータ分析から大きな成果と学びが得られました。
✔︎ なんとなくや感覚に頼らず、データで「相場からの乖離」を客観視できるようになったこと。
Pythonで物件の適正価格を予測し「割安度」を算出を構築。
これにより、経験や勘に頼りがちだった「相場観」をデータ化し、客観的な物件評価の第一歩となりました。
データ分析の限界(今回の)と、不動産投資における「目利き力」の重要性を再認識したこと。
データが出した「割安」が、必ずしも「お買い得」ではない現実を痛感。
安さの裏に隠されたリスク(例:再建築不可など、今回のモデルでは捉えきれなかった情報)を見抜く専門知識と、詳細な物件調査の必要性を改めて感じました。
データ分析は万能ではない。
しかし確実に不動産投資を効率化し、客観的な視点をもたらす強力な武器となる。
今回の分析はまだまだ個人的なプロジェクトの途中です。
改善の余地も多く残されています。
しかし、自分の手でデータを集め、分析し、仮説検証を繰り返す中で、「なぜこの物件がその価格なのか?」という不動産の本質に、データを通して少しでも迫ることができたような気がしています。
もし、いまあなたが「なんとなく」の物件探しに限界を感じているなら、データ分析という新たな視点を取り入れてみませんか?
プログラミング経験がなくても、今回紹介したようなPythonのライブラリを使えば、意外と手軽に第一歩を踏み出すことができます。
この試みが、あなたの不動産投資のとなれば幸いです。
「いいね!」やコメントで、あなたの感想やアイデアをぜひお聞かせください!
今後の改善プロセスや、他の分析結果についても記事にしていきますので、フォローもお待ちしています!
最後に今回使った条件の相関を色で表したヒートマップです。
このように可視化して何がどのように影響を与えているかを見て取れるのも良いですよね!!
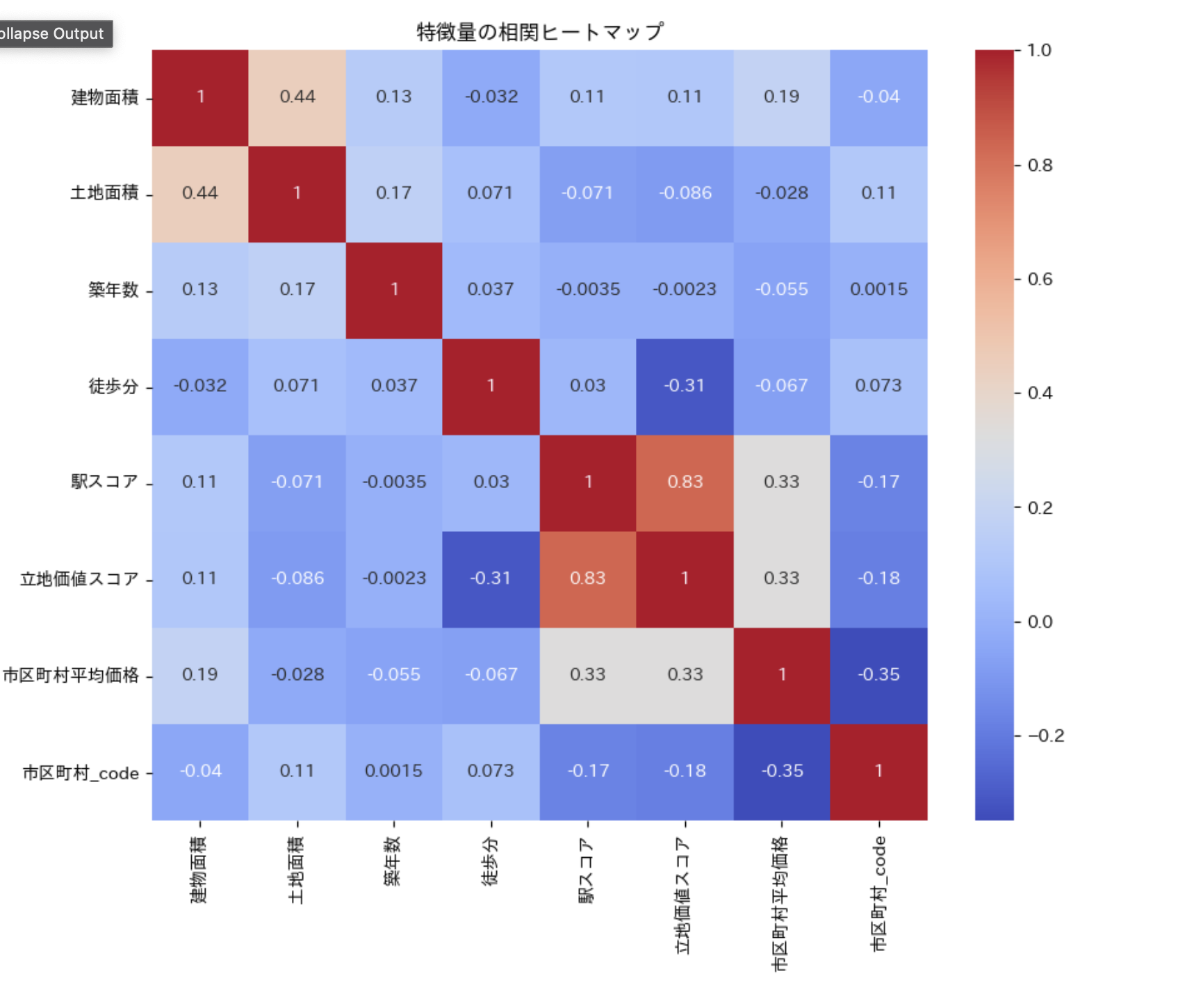
立地価値スコアと駅スコアの相関関係が高いので、次回取り扱う際はどちらかを無くしてもいいのかなと思いました。
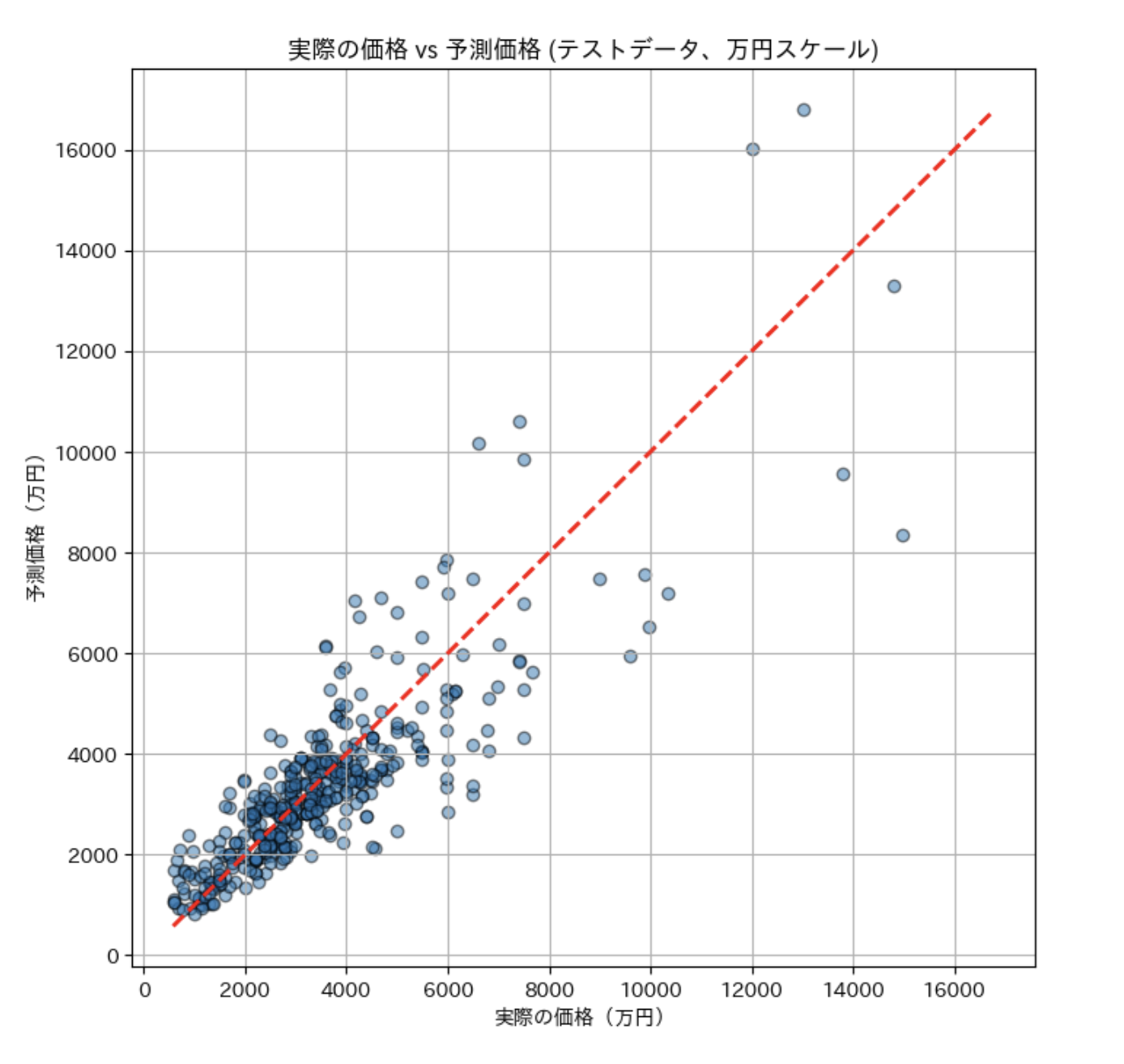
実際の価格と予測価格では4000万円くらいまでは予測価格周辺に集まっているのでうまくいっていると言ってもいいと思っています。
(甘いよ、というお声もお待ちしてます)しかし、4000万円以上の高価格帯になるとばらつきが大きくなってしまているので、これは今後の課題とさせていただきたいです!!
おそらく高価格帯はまた別の条件などが必要になるのかと想像しています!!