はじめに
yolo v3の原著論文を読んでいて、Feature Pyramid Networksを参考にしたよ、と書かれていて気になったので読んでみる。
筆者の理解で書いているので、間違っていたりわからないところあれば突っ込んでください!考えます!
Contents
論文はこちら
1. Introduction
前提:スケールが異なる物体を検出することはCVの中で基本的な課題の1つである
上記課題を解決するために特徴量を抽出する手法が検討されている。
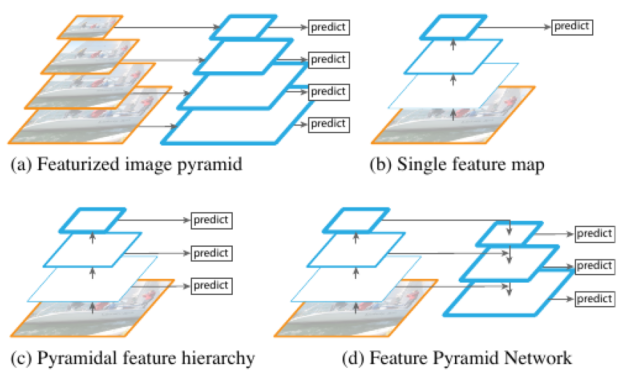
a. Featurized image pyramid
E.H Adelson et al. Pyramid Methods in Image Processing
画像サイズを変換 → サイズそれぞれの特徴マップを作成 → それぞれの特徴マップに対して物体がいるか検出を実施
画像サイズを変えていけば検出したい物体のスケールにいつか近い特徴マップを生成できるはずだから、実質物体のスケール変化はないものとして物体検出が可能という理解
課題:スケールを変えた画像1つ1つで検出を実施するので推論時間がめちゃくちゃかかる
b. Single feature map
これまで:特徴量設計は手作業で実施
この手法:Deep Convolutional Networks (ConvNets)の導入により特徴量が算出されるように

CNNの「FEATURE LEARNING」の部分
情報をどんどん畳み込んで特徴を抽出していくため、スケールのばらつきに対して頑健である。
課題- 推論時間が大幅に増加
- 異なる深さで意味にギャップが生じる
- 高解像度の特徴マップが低次元の特徴を持つため、物体認識の表現力が落ちている
3つ目がどういう意味かわかってない
c. Pyramidal feature hierarchy
ConvNetsの階層構造をあたかもFeaturized image pyramidのような特徴量を増やした階層として扱う手法
→ 初期の構造:Single Shot Detector (SSD)
課題:高解像度の特徴情報の再利用するタイミングを逃してしまう詳しいところわからないので要調査
多分、物体に関する情報量が豊富にあるのに再利用できないともったいない、ってことだと理解
d. Feature Pyramid Networks
本論文で提供する特徴量マップの構造
To achieve this goal, we rely on an architecture that combines low-resolution, semantically strong features with high-resolution, semantically weak features via a top-down pathway and lateral connections
- 意味的に強い特徴を持つ低解像度の階層
- 意味的に弱い特徴を持つ高解像度の階層
の2つをtop-downとlateralな接続で結合することですべての階層で豊富な意味を持って、推論時間が高速な構造となった。
2. Related Work
ここでは3つ紹介
論文の中身に入りたいのでここでは割愛
Hand-engineered feature and early neural networks
Deep ConvNet object detectors
Methods uding multiple layers
3. Feature Pyramid Networks
改めて、本論文の目標は
Our goal is to leverage a ConvNet’s pyramidal feature hierarchy, which has semantics from low to high levels, and build a feature pyramid with high-level semantics throughout.
上記の目標を達成するために構成として①Bottom-up pathway②Top-down pathway and lateral connectionsが含まれており、それぞれがどういったものか説明する。
ちなみに全体像は以下(参照)
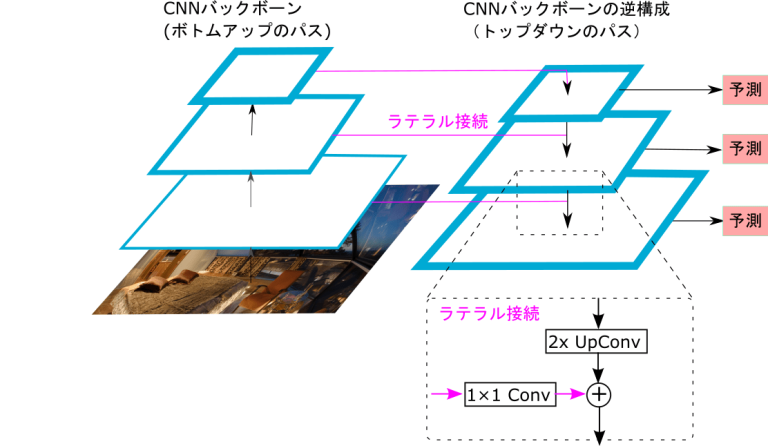
Bottom-up pathway
CNNのベースのパスのこと
畳み込みでサイズを半分にしていく処理
Top-down pathway and lateral connections
CNNのパスの逆を実施して、どんどんup-samplingしていく。
その情報にlateral connectionで対応するbottom-upのlayerを結合する。
4. Applications
deep ConvNetにfeature pyramidを形成する一般的な解だと主張
RPNとFast R-CNNを対象に例を挙げている。
著者の都合で割愛
5. Experiments on Object Detection
COCO datasetで実験:80 class
ここでもRPNとFast R-CNNを対象にしている。
著者の都合で割愛、後日確認して追記予定
6. Extensions: Segmentation Proposals
DeepMaskやSharpMaskといったsegmentationのframeworkを作るのにもこのFPNを用いていると紹介
基本的に導入は変わらないので、segmentationにFPNを適用するのは容易だと主張
7. Conclusion
以下本文内容の抜粋
本論文ではConvNetの中にfeature pyramidを作成する単純明快な手法を提案した。
また、Deep ConvNetは強力な表現力とscale変化に対する頑健性があることは暗黙の了解であるが、pyramid表現を用いて明示的に表現して対処することが重要であるとも主張する。
まとめ
途中から時間がなくて割愛気味になったものの、FPNの構成自体は(雰囲気)理解できた。
時間あるときに実験結果を確認するなどして課題はなんだったのか、などを検討したい。
最後のまとめであったけど、機械学習で暗黙の了解としてブラックボックス化している内容って結構多い印象ある。
どうにか目に見える形にできれば、今は何が課題でどう対処すればいいのかわかると思うんだが...