こんにちは、この記事はAltplus Advent Calnendar 2017の17日目のエントリです。
仕事ではAkka Streamの綺麗さに感動しつつ、プライベートのプロジェクトではC++17でコーディング中の竹田です。
Polymorphic Allocator
先日発行されたC++17ではPolymorphic Allocatorと呼ばれるAllocatorが導入されました。この導入を受けてか、Cppcon 2017ではAllocator関連の発表が多くありました。
Allocatorの問題点
そこにあるのに誰も気付かず、ないと生きていられない、まるで空気のような存在のAllocatorですが、みんな大好きstd::vectorテンプレートの第2型パラメータの彼です。
template<
class T,
class Allocator = std::allocator<T> // 今回の主役。
> class vector;
Allocatorは型に対してメモリを提供することが役割で、STL(Standard Template Library)をコンピュータのメモリ・モデルから切り離すことを目的として導入されました。Allocator (C++)@Wikipedia従来のAllocatorは幾つかの問題点を抱えており、C++11以降、少しづつ改良されてきました。
問題点の1つは実装の詳細であるはずのAllocatorが型の一部としてあることです。STLではテンプレートのパラメータとしてAllocatorが渡されています。これはAllocatorが型の一部になるということです。STLのコンテナはValue Semanticsを念頭に設計されており、数学のコンセプトを表現していますが、Allocatorという実装の詳細が型に表われると、この対応がくずれてしまいます。例えば、std::vectorは、列(sequence)を表現しており、数列{1, 2, 3}は、std::vector<int>{1, 2, 3}で表現できます。Allocatorの異なる、std::vector<int, MyAllocator>{1, 2, 3}も、std::vector<int, YourAllocator>{1, 2, 3}も同じ数列{1, 2, 3}の表現ですが、型が違うため比較することはできません。
その他にもAllocatorが型の一部であるためカスタムAllocatorを使用したいクライアントのコードまでテンプレート化する必要があるなどの問題もあります。
これらの問題点を解決するために導入されたのがstd::pmr::polymorphic_allocatorとstd::pmr名前空間したにあるコンテナです。
std::pmr
まずはstd::pmr::vectorテンプレートの定義を見てみます。std::vector@cppreference単純に、std::vectorのAllocatorにstd::prm::polymporphic_alloctorを指定したalias templateです。
namespace pmr {
template <class T>
using vector = std::vector<T, std::pmr::polymorphic_allocator<T>>;
}
std::pmr::polymorphic_allocatorはコンストラクタでstd::pmr::memory_resourceオブジェクトへのポインタを受け取ります。std::pmr::polymorphic_allocatorの振舞いstd::pmr::memory_resourceの振舞いで定義されます。ラムダがstd::functionで型消去されるのと同様に、Allocatorはstd::pmr::polymorphic_allocatorによって型を消去されます。異なるAllocatorを型消去で単一の型として扱うことで前述のAllocatorが型に表われる問題を解決します。
カスタムAllocator
std::prm::memory_resourceから派生したクラスを実装することでカスタムAllocatorを定義することができます。Howard HinnantのStack Allocatorを、std::memory_resourceを使用して実装してみます。Stack Allocatorは、要素数の少いコンテナ用のAllocatorで、ヒープではなくスタックにメモリを確保することで動的メモリ確保のコストを避けるAllocatorです。以下のコードではSTLのC++17対応状況の関係、std::experimental名前空間を使用していますが、C++17では、experimentalは不要です。
カスタムAllocatorを実装するには、std::pmr::memory_resourceから派生し、以下の3つのメソッドをオーバーライドする必要があります。
- do_allocate
- do_deallocate
- do_is_equal
# include <experimental/memory_resource>
# include <array>
# include <vector>
# include <cassert>
template<std::size_t N>
class stack_memory_resource : public std::experimental::pmr::memory_resource {
std::array<std::byte, N> buf;
std::byte* pos;
public:
stack_memory_resource() noexcept : pos(buf.begin()){}
stack_memory_resource(stack_memory_resource const&) = delete;
stack_memory_resource& operator=(stack_memory_resource const&) = delete;
protected:
// メモリの確保。実装の簡素化の為、alignmentは無視。
void* do_allocate(std::size_t bytes, std::size_t /*alignment*/) override {
if(bytes > remaining()){
throw std::bad_alloc();
}
auto memory = pos;
pos += bytes;
return memory;
}
// メモリの解放。実装の簡素化の為、alignmentは無視。
void do_deallocate(void* p, std::size_t bytes, std::size_t /*alignment*/) override {
if(pointer_in_buffer(p)){
if(auto pb = static_cast<std::byte*>(p); (pb + bytes) == pos){
pos = pb;
}
}
}
// オブジェクトの比較。
bool do_is_equal(std::experimental::pmr::memory_resource const & other) const noexcept override {
return this == &other;
}
private:
std::size_t remaining() const {
return buf.end() - pos;
}
bool pointer_in_buffer(void* p) const {
return buf.begin() <= p && p < buf.end();
}
};
// 標準ライブラリが対応していないため自分でalias templateを定義。
namespace std::pmr {
template <typename T>
using vector = std::vector<T, std::experimental::pmr::polymorphic_allocator<T>>;
}
int main(){
stack_memory_resource<32> resourceA;
stack_memory_resource<64> resourceB;
// vectorのコンストラクタはpolymorphic_allocatorを期待しているが、
// *memory_resourceからpolymorphic_allocatorへは暗黙の変換
std::pmr::vector<int32_t> vecA({1, 2, 3, 4}, &resourceA);
std::pmr::vector<int32_t> vecB({1, 2, 3, 4}, &resourceB);
assert(vecA == vecB);// 異なるリソースからメモリを確保しても比較可能。
return 0;
}
main関数で実装したカスタムAllocatorを使用しています。std::pmr::vectorに定義したstack_memory_resourceへのポインタを渡しています。異るリソース上に構築したvector同士の比較も可能で、値のセマンティックスに従った動作をします。
ベンチマーク
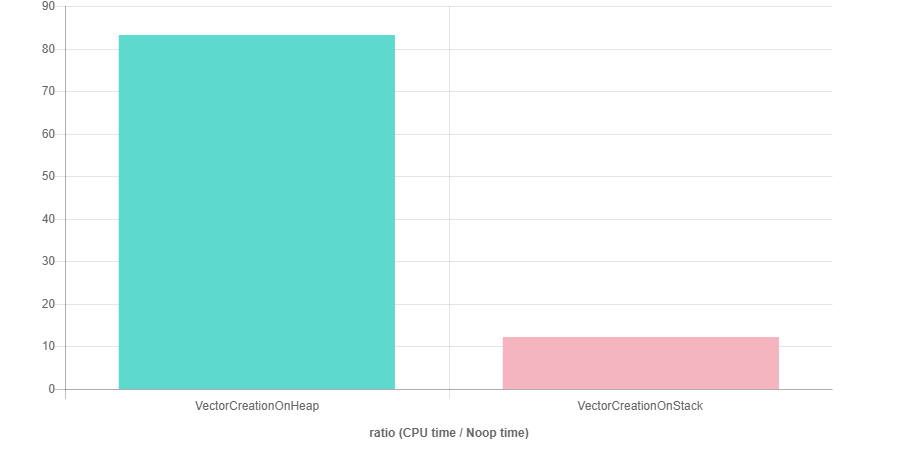
実装したstack_memory_resourceが、どれくらいの効果があるかquick-bench.comで計測した結果が以下の通りです。ループ中で要素数4のvectorの生成と破棄を繰り返した性能の比較です(gcc-7.2 & c++17 & -O3)。結果を見ると、stack_memory_resourceの方が約7倍ほど速いようです。
static void VectorCreationOnHeap(benchmark::State& state) {
// Code inside this loop is measured repeatedly
for (auto _ : state) {
std::vector<int32_t> v{1,2,3,4};
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(v);
}
}
// Register the function as a benchmark
BENCHMARK(VectorCreationOnHeap);
static void VectorCreationOnStack(benchmark::State& state) {
// Code before the loop is not measured
for (auto _ : state) {
stack_memory_resource<64> resource;
std::pmr::vector<int32_t> v({1, 2, 3, 4}, &resource);
benchmark::DoNotOptimize(v);
}
}
BENCHMARK(VectorCreationOnStack);
STLでは、スレッド・アンセーフでグローバル・ロックをとらないリソース(unsynchronized_pool_resource)や、今回のstack_memory_resourceのようにリソースの破棄のタイミングでのみメモリを解放するmonotonic_buffer_resourceなどいくつかのmemory_resourceを提供しています。
最後に
今回はC++17で導入されたpolymporhic_allocatorの仕組みを使ってカスタムAllocatorを実装する方法を見てきました。
Allocatorは様々な用途で広く利用されています。
- GPUなどCPU以外のデバイスのメモリを使用する。Boost.Compute pinned_allocator
- BitCoinソフトウェアのセキュリティ向上。破棄後にメモリをゼロ・クリア。メモリのスワップによるハード・ディスク上への情報の残りを防ぐ。Bitcoin Core allocators
Allocatorを使用することで、STLのコンテナという高い抽象度のIFを使用しつつ、さまざまな機能を追加することが可能です。皆さんも目的にそったAllocatorが無いか探してみるのはいかがでしょうか。From Security to performance to GPU programmingの、スライドに多くのAllocatorが紹介されています。