はじめに
Databricks SQL の普及により、DWH 環境におけるクエリチューニングの重要性がこれまで以上に高まっています。中でも、クエリ実行の可視化とボトルネックの特定に有効な「クエリプロファイラ」は、開発者・管理者双方にとって欠かせない分析ツールです。
本記事では、2025年春に刷新された新 UI をベースに、クエリプロファイラの活用方法を実例を交えて紹介し、クエリの健全性評価やパフォーマンス改善の具体的なアプローチを解説していきます。
クエリプロファイル(Query Profile)の特徴
Databricks のクエリプロファイル(Query Profile)は、SQL クエリのパフォーマンス解析や最適化に役立つツールです。クエリの実行後、SQL エディタやノートブック上で表示される実行プランに付属しており、クエリを構成する各ステージやオペレーターの実行状況を視覚的に把握できます。
クエリプロファイルの主な目的
- クエリのパフォーマンスボトルネック特定
- リソース使用状況の可視化(メモリ、CPUなど)
- ジョブの失敗や遅延の原因調査
- 物理実行プランの確認と最適化
Databricksのクエリプロファイルは、SQLの専門知識がないユーザーでも直感的にクエリのパフォーマンスを理解・改善できるように設計されています。
クエリプロファイル(Query Profile)の起動方法
管理者や開発者など、利用するロールに応じて使いやすくなるよう、2通りの起動方法が用意されています。
- 管理者向け
- 左サイドバーの「Query History(クエリ履歴)」をクリック
- 管理者向けのUIでは、過去に実行された重いクエリや失敗クエリの調査、実行パターンの分析が可能です。また、クエリID・実行ユーザー・実行時間などの条件で絞り込み検索を行うこともできます。

- 開発者向け
- ノートブックや SQL エディタでクエリを実行した後に表示される「See Performance(パフォーマンスを表示)」をクリック
- ノートブックや SQL エディタに統合された UI により、実行結果のすぐ下にクエリプロファイルが表示されます。ページ遷移することなく、その場で実行したクエリのパフォーマンスを即座に確認・分析できる、開発者向けの操作画面です。

クエリプロファイル(Query Profile)の読み方
それでは、実際にクエリを実行した際のクエリプロファイラの画面を見ながら、出力される情報の読み解き方について解説していきます。
まずは、クエリプロファイラを起動した際に画面の左側に表示される「クエリの詳細情報」から確認していきましょう。

クエリ詳細
クエリ詳細のセクションでは、クエリの健全性やパフォーマンス上のボトルネックを確認するための、さまざまな情報を取得できます。
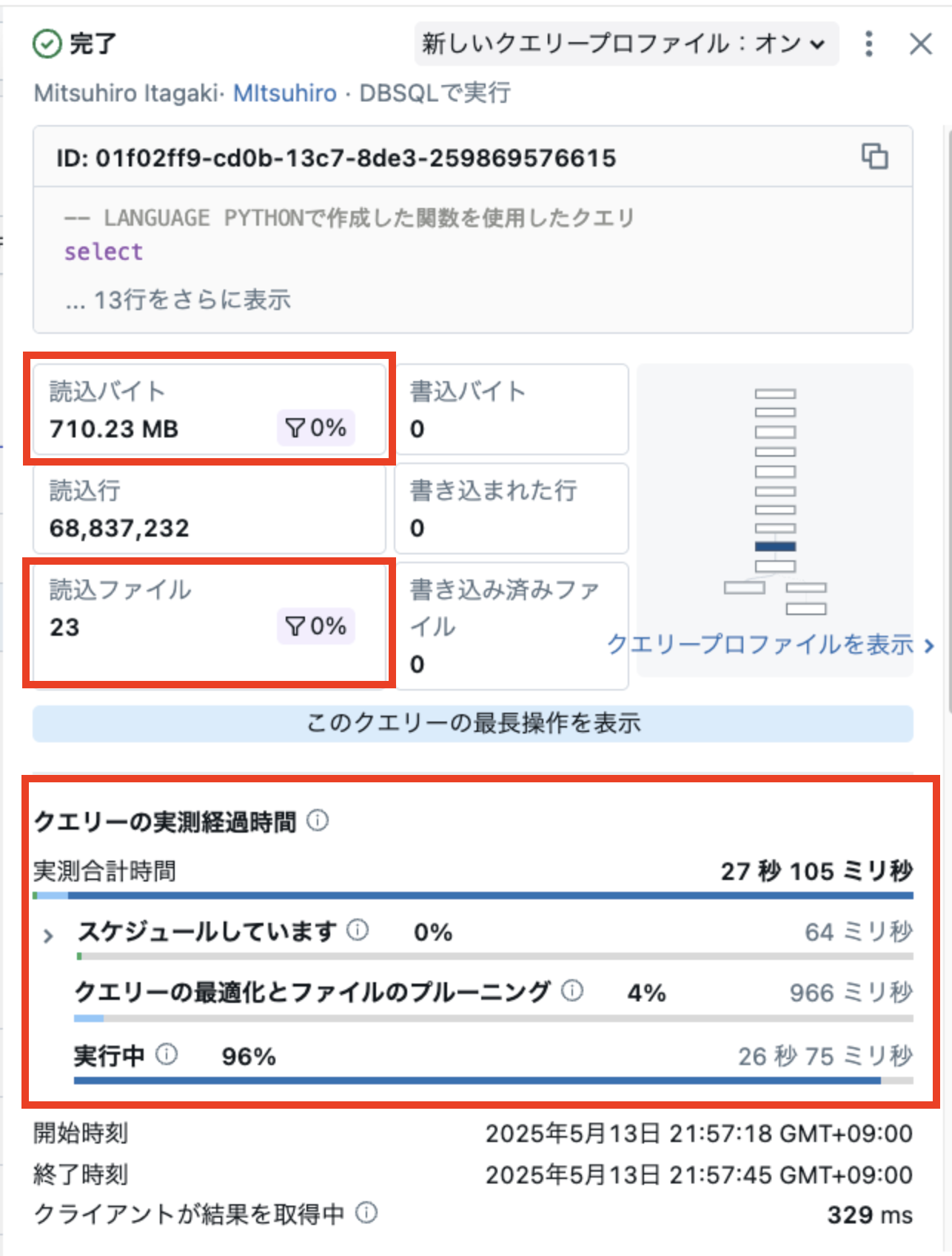
クエリプロファイラでは、直感的に理解しやすい形で、いくつかの重要なメトリクスが表示されます。代表的なものは以下のとおりです。
-
読込バイト
クエリ全体で読み込まれたバイト数と、そのうち実際に処理に使用されたデータの割合(フィルターレート)が表示されます。 -
読込ファイル
クエリ全体で読み込まれたファイル数と、そのうちフィルターを通過したファイル数の割合(フィルターレート)が表示されます。
これらのフィルターレートが低い場合、クエリ条件の見直しや I/O 削減の最適化によって、さらなる改善の余地がある可能性があります。
クエリの実行時間セクションでは、クエリ処理にかかった時間の内訳が表示されます。各項目の意味は以下のとおりです。
-
スケジュール
Warehouse のスケーリングアップや初期化に時間がかかっている場合、あるいは同時実行クエリが多く、リソースの競合が発生している可能性があります -
クエリーの最適化とファイルのプルーニング
この時間は、クエリの解析、実行計画の作成、ファイルの絞り込み(例:パーティションプルーニング)といった前処理にかかるものです。一般的には、この時間がクエリ全体の実行時間の10-30%以下であることが理想ですが値が大きい場合は、以下のような改善策を検討する必要があります:
- 統計情報を取得してクエリプランの精度を高める
- OPTIMIZE コマンドによってファイルの物理配置を最適化する など -
実行(Execution)
実行フェーズに時間がかかっている場合は、クエリの物理処理(ファイルの読み込み、演算、結合、集計など)そのものにボトルネックがあることを意味します。他の詳細情報(ステージ別の実行時間、スキューの有無、シャッフル量など)を確認して原因を特定します。
さらに画面下部にスクロールすると代表的なメトリクスの集約情報が表示されます。
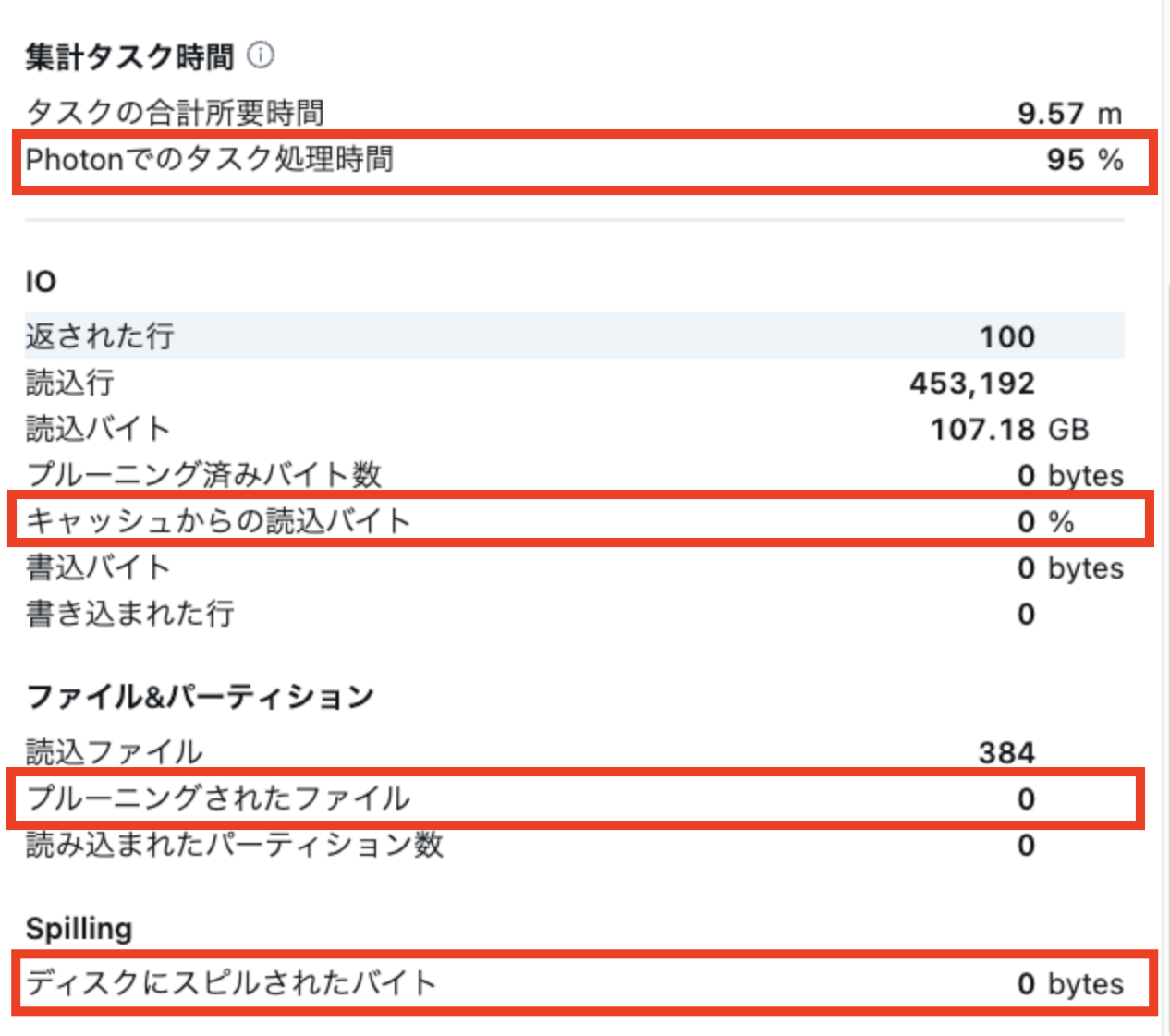
特に以下のメトリクスに注意し、状況に応じたチューニングを実施します。
- Photonでのタスク処理時間
80-100%が理想ですが割合が低い場合にはPhoton未対応の処理がある可能性が高いためクエリの書き換えを検討します - ディスクキャッシュからの読み込みバイト
クラウドストレージにアクセスせずにキャッシュから取得できたデータ量で値が大きいほど、キャッシュが効いており、パフォーマンスとコスト削減に寄与しています - プルーニングされたファイル
フィルター条件によりスキャン対象から除外されたファイル数を示します。値が大きいほどパフォーマンスとコスト削減に寄与しています - ディスクにスピルされたバイト
結合処理などのクエリプランが適切でないか、選択したTシャツサイズがデータ量に対して小さい可能性があります
トップオペレーター
トップオペレーターの表示では、ボトルネックの特定や優先的にチューニングすべき処理を見つけるための、非常に有用な情報を確認できます。
「このクエリの最長操作を表示」をクリックすると、最も時間のかかった処理(トップオペレーター)とその実行プランが表示され、クエリ内で最も負荷の高い処理がどこにあるかを視覚的に把握できます。
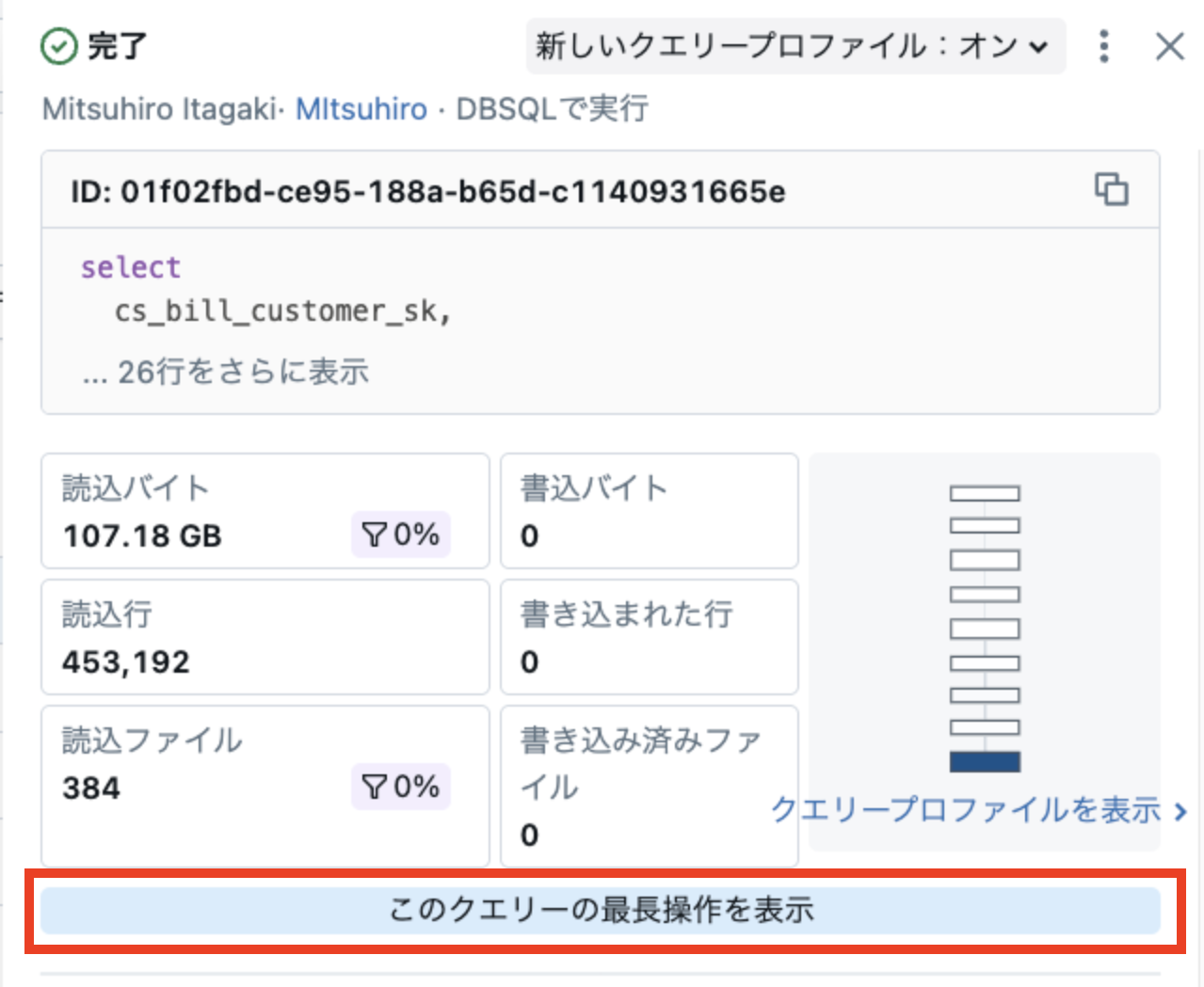
トップオペレーターには以下の3つのタブが表示されます:
- 所要時間
- メモリのピーク使用量
- 処理行数
それぞれの観点から処理を確認することで、最もコストの高い処理を特定することができ、チューニング対象として優先的に検討すべきポイントを見極めることが可能です。
たとえばこの例では、#9 の Scan Table オペレーターが最も時間を要しており、明確なボトルネックであることがわかります。

各オペレーターの詳細表示
時間のかかる処理が特定できたら、各オペレーターのアイコンをクリックすることで、さらに詳細な情報を確認できます。

主な確認ポイントは、以下のとおりです。
Databricks機能の利用有無
テーブルなどのデータソースには Delta が使用されていること、またすべてのオペレーターで Photon エンジン が使用されていることを確認しましょう。
- Delta を使用
- Photon を使用
各オペレーターの詳細情報の上部に表示される以下のようなアイコンにより、これらの機能が使用されているかどうかを判別できます。

メトリクス
オペレーターごとに表示されるメトリクスは異なりますが、たとえば Scan Table オペレーターでは、上記の赤枠内にあるいずれかのアイコンをクリックすると、右側にその処理に関する詳細なメトリクス情報が表示されます。
重要なメトリクスの多くは前述の統計情報にも含まれていますが、Scan Table オペレーターの場合は、以下のようにボトルネックの特定に役立つ追加のメトリクスも確認できます。
たとえば、以下のようなメトリクスは、ボトルネックの発見に役立つ重要な手がかりとなります。
-
Cloud storage retry duration
クラウドストレージからの読み取り時に、何らかの理由でリトライが発生した際の合計リトライ時間を示します。値が大きい場合、ストレージの一時的な遅延やI/Oの非効率が疑われます。 -
Size of row groups before filtering
フィルタリング前にスキャン対象となった行グループの総サイズです。値が大きい場合、クエリの絞り込み条件が効いておらず、無駄なデータの読み取りが発生している可能性があります。
使用カラムに関する情報
スクロールダウンすると、クエリで使用されているカラムに関する情報が出力されます
- クラスタリングキーの情報(Cluster attributes) ※設定されている場合
- カラムの一覧(Output attributes)
- フィルター条件(Filters)
が表示されます。
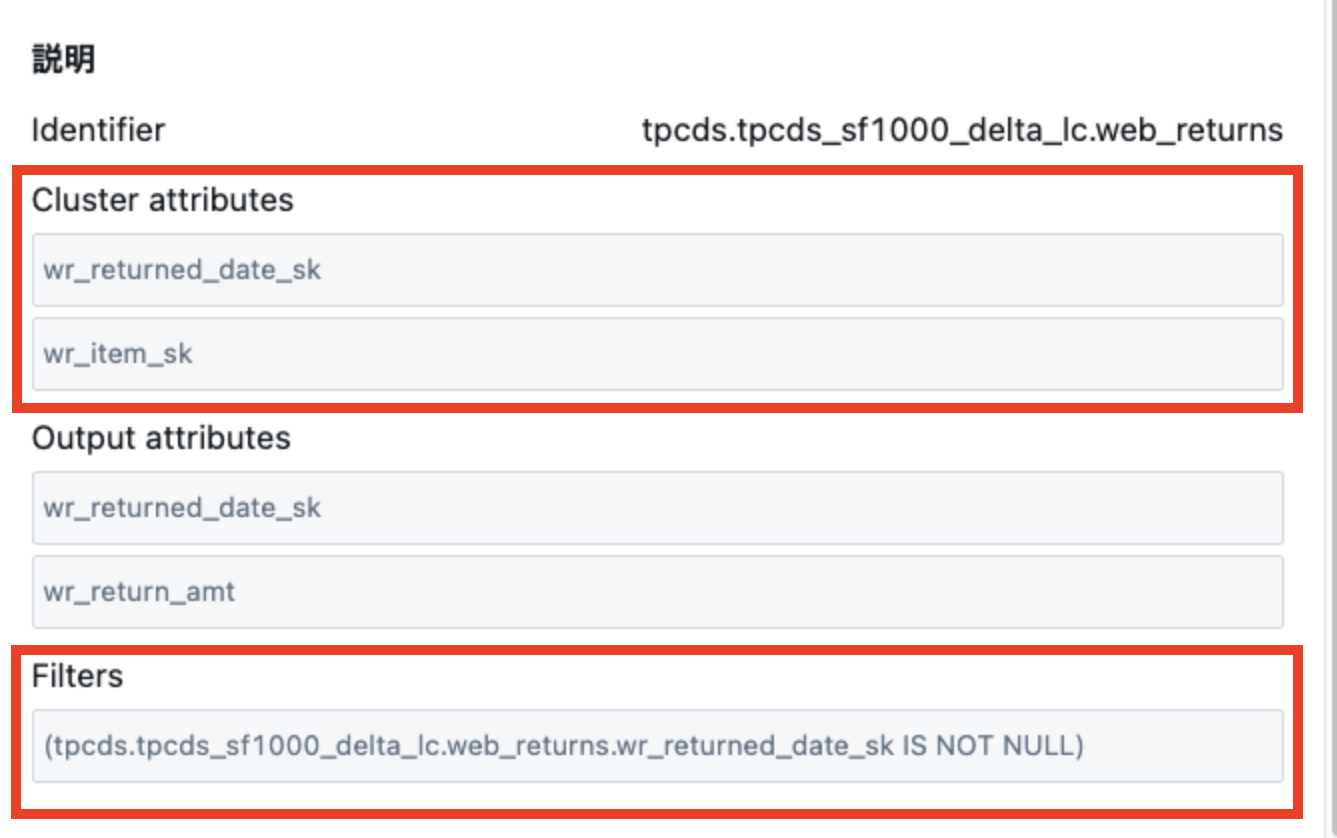
クエリの I/O 削減を検討する際は、Filters(フィルター条件) に特に注目してください。クエリ内で指定されているフィルター対象のカラムに対して、Databricks で利用可能な I/O 削減機能が正しく設定されているかを確認することが重要です。
代表的な機能として、以下のものがあります:
-
Liquid Clustering
特別な理由がない限り、全てのテーブルでこの機能の使用が推奨されます。データスキューや再クラスタリングの課題を自動的に最適化します。 -
Z-Order
複数のフィルター条件がある場合に有効で、効率的なファイルスキップが可能になります。 -
Partitioning
特定のカラムに対するクエリが頻繁に行われる場合、パーティショニングによりファイル読み込みの対象を大幅に絞り込むことができます。
クエリ実行計画
画面左側には、クエリの実行計画が DAG(有向非巡回グラフ)形式で表示されており、前述のトップオペレーターの情報とあわせて、クエリ全体の中でどの処理がボトルネックになっているかを視覚的に把握することができます。
各オペレーターの処理時間やデータ量に応じて、色の濃淡やオペレーター間を結ぶ線の太さが変化し、データ処理の負荷や流れを直感的に理解できるようになっています。
また、トップオペレーターと同様に、このDAGビューでも以下の3つのタブを切り替えて表示することが可能です:
- 所要時間
- メモリのピーク使用量
- 処理行数
それぞれのタブを確認することで、最もコストの高い処理を特定でき、チューニングの優先順位を判断する際の重要な手がかりとなります。
たとえばこの例では、#9のScaler UDFオペレーターが最も時間を要しており、明確なボトルネックであることが分かります。

各オペレーターは、前述のオペレーター詳細情報とリンクしているため、クエリ実行計画(DAG)を見ながら処理時間のかかっているオペレーターを選択し、その詳細を確認することが可能です。
これにより、視覚的かつ直感的な操作でボトルネックを特定でき、効率的なチューニングにつなげることができます。
クエリ実行計画ではボトルネックとなりやすい以下のオペレーターを確認すると良いです
結合方法
Join ノードにおいて、適切な結合戦略(Broadcast Join / Sort Merge Join / Shuffled Hash Join など)が選択されているかどうかの見極めは、パフォーマンスチューニングの観点で非常に重要です。
特に、Sort Merge Join が選ばれている場合はPhotonエンジンが利用できないため改善の余地があることが多く、統計情報を最新化やテーブルサイズに応じたプランの見直しが効果的です。
以下の例では、Broadcast Join が使用されており、Build Side(ブロードキャストされる側)には右側のレコード数が少ないテーブルが選ばれているため、適切で健全な実行計画であることが確認できます。
期待する結合方式が自動で選択されていない場合は、以下の対処をお試しください。
- 統計情報を最新化し、オプティマイザの判断を支援する
- ヒント句を使用して、 結合方式(例:SHUFFLE_HASH、BROADCAST JOINなど)なの結合方式を明示的に指定する

シャッフル
シャッフル操作は Spark 処理の特性上、避けられない工程ですが、適切な並列処理数(パーティション数)で実行されているかを確認することが重要です。
想定よりもシャッフルに時間がかかっている場合は、データの偏り(スキュー)が発生している可能性があり、ボトルネックの原因となることがあります。
データの偏り(スキュー)に対する対応方法はいくつかありますが、まずは SQL レベルで設定可能な REPARTITION/REPARTITION_BY_RANGE/REBALANCEヒントの活用を検討してみてください。
これは、各パーティションが適切なサイズ(小さすぎず大きすぎない)になるようにするためにSpark に明示的に伝えるヒントでありスキューを改善できる可能性があります。

SparkUIを使用したより詳細な調査方法
より詳細な調査が必要な場合には、Spark UI の情報を参照することも有効です。
ここでは、Spark UI を活用したボトルネック調査の具体的な手順と活用例を示しながら、分析方法を解説していきます。
尚、Spark UIにアクセスする場合はユーザがSQLウェアハウスのCanMamage権限を保持している必要があります。
Spark UIの情報は、Databricks SQL(DBSQL)のクエリプロファイルでは見えにくい物理的な実行レベルの詳細を補完できる点で大きなメリットがあります。
- DBSQL クエリプロファイル
- SQLクエリの論理計画・物理計画・ファイルプルーニングなどSQLチューニングの確認に適しています
- Spark UI
- 実際のSparkジョブの並列処理、リソース使用状況、I/O、GC時間などのインフラ視点の詳細なパフォーマンス分析に優れています
ケース1: Photon利用率が低い場合
Photon利用率が低い場合の原因特定には、Spark UI に表示される情報の確認が有効です。
Spark UI は、クエリプロファイラ画面の右上にある ケバブメニュー(縦に並んだ3つの点) をクリックして表示される追加メニューから、Spark UI で開く を選択することでアクセスできます。
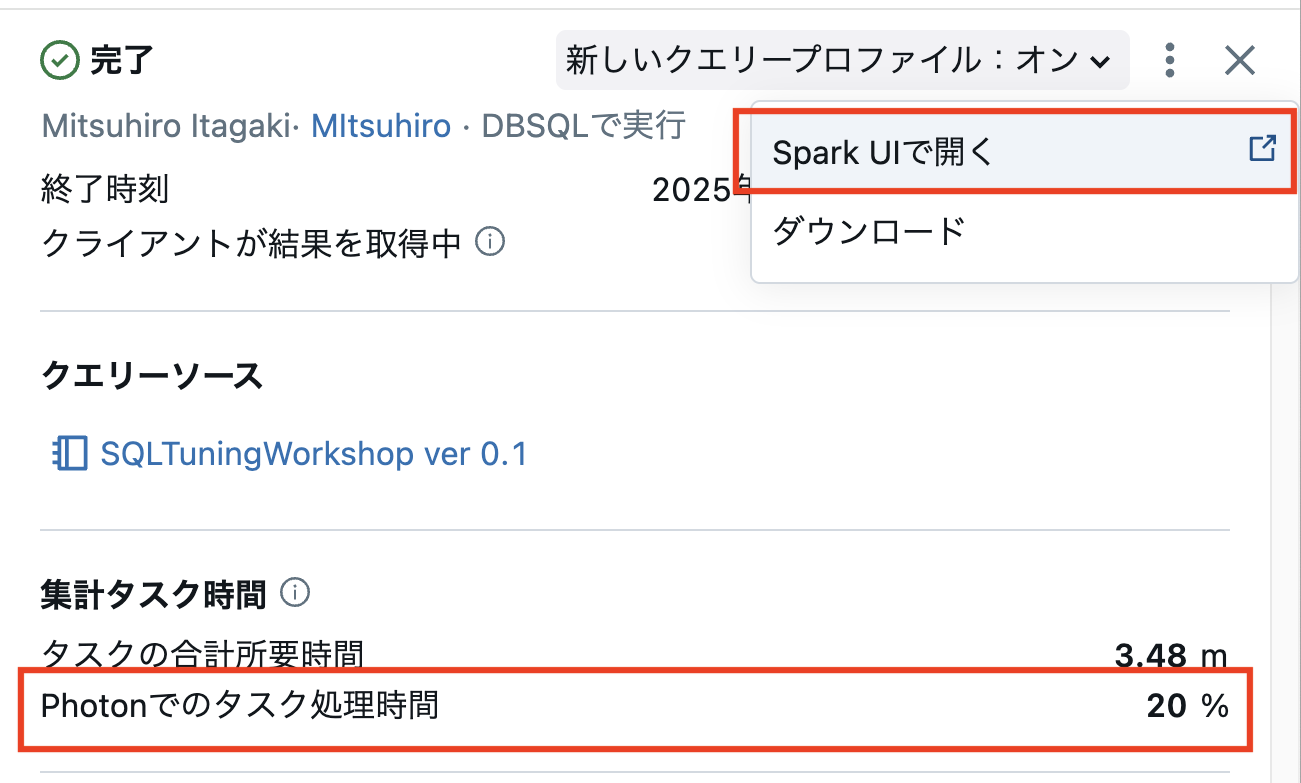
Spark UI がオープンされたら、ページ下部にあるDetailsセクションをクリックし、詳細な実行情報を確認します。
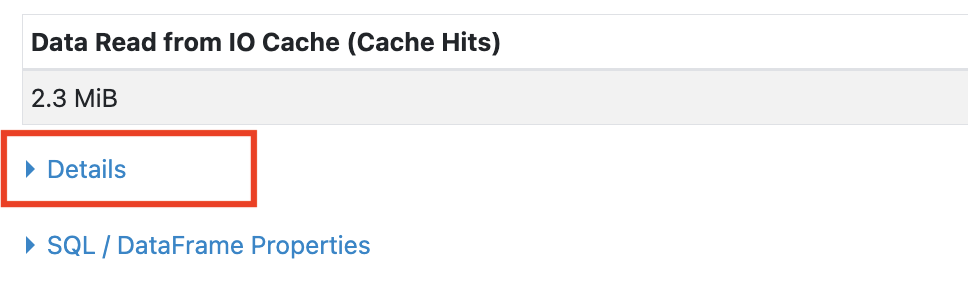
「Details」を展開すると表示される詳細情報の最下部に、Photon Explanation セクションがあります。ここに、各クエリにおける Photon の適用状況が表示されます。
Photon does not fully support the query because で始まるメッセージの下には、Photon エンジンによる実行を妨げた具体的な原因が表示されます。
その内容を確認し、クエリの記述を見直すなどの対応を行うことで、Photon の適用率を改善できます。

すべての処理が Photon エンジンで正常に実行された場合、以下のメッセージが表示されます:

なお、Spark UI 上では、各ステージの実行エンジンに応じて色分けがされています。
- Photon エンジンで処理されたステージは 黄色
- Spark エンジンで処理されたステージは 青色
として表示されます。
クエリ全体のパフォーマンスを最大限に引き出すためには、できるだけ多くのステージが黄色(Photon)になっていることが望ましいです。

ケース2: シャッフル処理で時間がかかっている場合
シャッフル処理に時間がかかっている場合は、**クエリプロファイル右上のケバブメニュー(縦に並んだ3つの点)をクリックして追加メニューを開き、「冗長モードを有効化」**を選択してください。
これにより、通常は表示されない詳細なオペレーター情報が確認でき、ボトルネックの原因調査に役立ちます。
※この操作は、シャッフル処理に限らず、他のすべてのオペレーターについても同様に実施できます。

冗長モードを有効にすると、より詳細なメトリクス情報が表示されます。
その中には、該当のオペレーターが実行された Spark のステージ ID も含まれており、Spark UI 上での詳細なステージ分析に活用することができます。

Spark のステージ ID が確認できたら、クエリプロファイル右上のケバブメニュー(縦に並んだ 3 つの点)をクリックして追加メニューを開き、「Spark UI で開く」を選択します。

今回の例では、ステージ ID は 144 でした。
Spark UI にアクセスしたら、まず上部メニューから 「Stages」タブを選択し、表示されたステージ一覧の中から 該当のステージ(ID: 144) を探します。
対象ステージが見つかったら、「Description」列に表示されているハイライトされたリンクをクリックすることで、さらに詳細な実行情報を確認できます。

ステージの詳細画面では、該当ステージを構成する各タスクの実行情報を確認することができます。
これらの情報をもとに、処理時間のばらつきやデータの偏り(スキュー)の有無などを分析し、ボトルネックとなっている要因を特定する手がかりを得ることが可能です。

さいごに
本稿では、Databricks SQL におけるクエリプロファイルの基本的な見方から、パフォーマンスボトルネックの特定方法、さらには Spark UIを活用した詳細分析の方法を解説しました。
クエリプロファイルは、視覚的で直感的に操作できるだけでなく、Spark の実行基盤とも連携しており、SQL チューニングにおける強力な分析ツールとなります。日々の分析業務やシステム運用において、今回紹介した観点を取り入れることで、クエリパフォーマンスの継続的な最適化につなげることができるでしょう。
今後も Databricks は、パフォーマンス可視化のための機能強化が進むことが期待されます。ユーザー自身がクエリの状態を正しく把握し、主体的に改善できることが、モダンなデータ基盤の運用においてますます重要になっています。ぜひ、本記事の内容を現場での活用に役立てていただければ幸いです。