あらまし
「日本語環境のWindowsでIntelliJのJVM引数で -Dfile.encoding=UTF-8 を設定すると、日本語ファイルパス上のプロジェクトをGradleから実行やテストができない」という問題に遭遇した。
色々調査した結果、根本的な問題はプロジェクト側ではなくJava 17以前のJVM自体に存在し、2022年11月現在、「 -Dfile.encoding=UTF-8 するのをやめる」「日本語ファイルパスに置かない」「ビルドスクリプトで頑張る」「Gradleが対応するのを待つ」といった妥協案しか存在しないという結論となった。
環境
- Windows 10 Pro 21H2 日本語環境
- IntelliJ IDEA 2021.3.3 (Community Edition)
- Gradle 6.5
- Java 主に11
- Kotlin 1.6.0
背景
IntelliJ IDEAの文字化け対策
普通に日本語環境で🍰とかを出すと文字化けする
IntelliJでは、普通に標準出力にユニコード文字を流すと文字化けしてしまう問題がある。
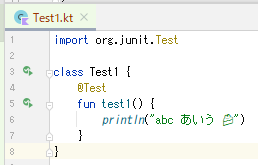
※ println は System.out.println と同じ効果。
「バイト」のストリームである標準出力に「文字」の列を出すには文字列をバイト列に変換しなければならないが、日本語環境ではデフォルトでWindows-31jやMS932と呼ばれるShift-JISの亜種が使われるため、一部の文字がエンコードできないためである。
IntelliJのJVM引数で改善できる
これにはIntelliJの設定で次のように文字コードを指定すればよい。
-Dfile.encoding=UTF-8
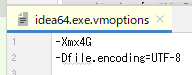
こうすると内部で呼び出されるJavaプロセスのJVM引数にもこれが渡され、IntelliJとのやり取りがUTF-8で行われ、なんだかんだでコンソール画面に絵文字等が出せるという寸法である。
標準出力に出す文字コードの制御はJavaコード上で行われる
上記の動作を実現するためには呼び出されるJavaプロセスが標準出力にUTF-8として文字列を流さなければならないが、そこの部分の制御は実はJVM上ではなくJavaコード上で行われている。
System.out.println の中身を実際に追いかけてみると、内部でJavaのUTF-8のエンコーダーを呼び出していることが分かる。
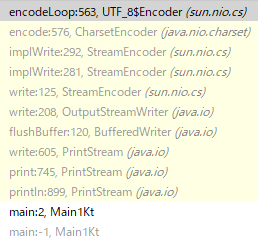
その文字コードの選択は OutputStreamWriter#se というprivate変数で行われている。
main開始前のコードはIntelliJがブレークできないっぽいので se にエンコーダーが代入される瞬間を見ることは適わなかったが、 file.encoding に UTF-8 が指定されているのを見ることができた。
恐らく、JVM引数で file.encoding を指定する(か、自前でエンコードしたバイト列を出力する)しか標準出力の文字コードを弄る方法はないのだろう。
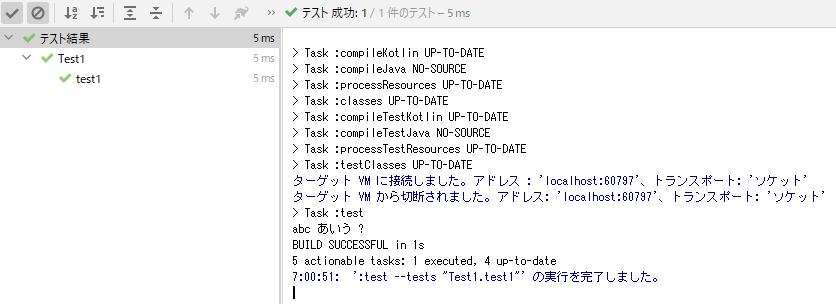
IntelliJ上でGradleのテストが起動できない
Test1というテストクラスを実行しようとしたら、テストが起動すらせず例外になってしまった。
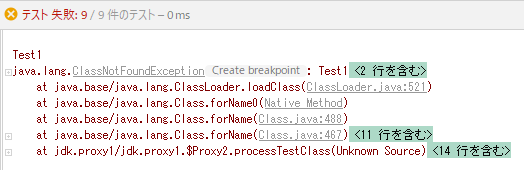
調査
まずはどうしてこうなるかを調べよう。
classpathが文字化けしている
とりあえず現状唯一の資料である例外文からデバッグしてみる。
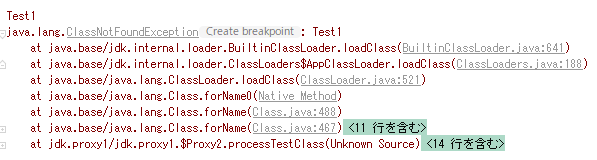
jdk.internal.loader.BuiltinClassLoader.loadClass という部分で例外が出ている。
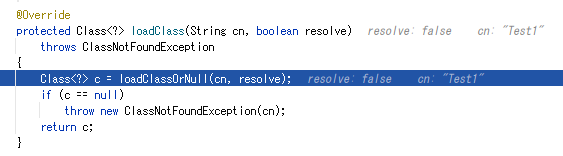
辿っていくと、 URLClassPath#path というフィールドに文字化けしたファイルURLが格納されていることが判明。
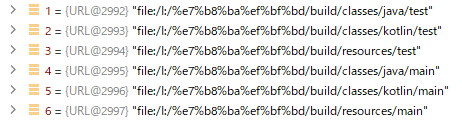
プロジェクトが置かれている本来のパスは I:\あ である。
あ
↓
%e7%b8%ba%ef%bf%bd
「あ」が6バイトの何かにエンコードされている。
調べたところ、UTF-8としてエンコードした「あ」をShift-JISでデコードするとこのようになるようだ。
あ(UTF-8) E3 81 82
縺(Shift-JIS) E3 81
縺(UTF-8) E7 B8 BA
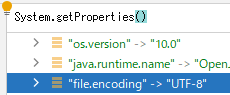
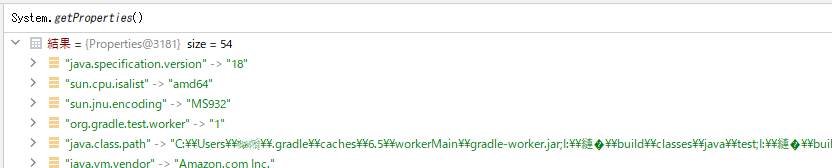
System.getProperties() を探ったところ、実は文字化けの起源はかなり低レイヤーの部分にあることが分かった。
GradleのログからJavaの起動コマンドを取得できた。
2022-11-25T10:40:59.781+0900 [INFO]
[org.gradle.process.internal.DefaultExecHandle]
Starting process 'Gradle Test Executor 1'.
Working directory: I:\あ
Command:
C:\Users\user1\.jdks\corretto-18.0.2\bin\java.exe
≪中略≫
@C:\Users\user1\AppData\Local\Temp\gradle-worker-classpath6767662860216726579txt
-Xmx512m
-Dfile.encoding=UTF-8
-Duser.country=JP
-Duser.language=ja
-Duser.variant
-ea
worker.org.gradle.process.internal.worker.GradleWorkerMain 'Gradle Test Executor 1'
何やら C:\Users\user1\AppData\Local\Temp\gradle-worker-classpath6767662860216726579txt という場所に置かれている、拡張子の設定をミスったファイルを参照しているようだ。
その中には100個を超える項目の-cpオプションが書かれていた。
そして、 I:\\あ\\build\\classes\\kotlin\\main と、しっかりとUTF-8で記述されていた。
このファイルをShift-JISで読み取るとああなるようだ。
解決手段の探索
どうしてこうなるかが分かったので、どうすれば防げるかを考えよう。
argfileの文字コードを指定する大作戦
argfileの文字コードが書き込み側と読み込み側で違うなら、設定すればいいじゃない。
読み取り側は「システムのデフォルト・エンコーディング」で固定
公式のドキュメントを見ると、argfileの文字コードは「ASCII文字またはASCIIと親和性の高いUTF-8などのシステムのデフォルト・エンコーディング」とある。
@argfileオプションにより、シェル拡張の後かつ引数処理の前にランチャで引数ファイルの内容を展開できるようになる
引数ファイルでは、ASCII文字またはASCIIと親和性の高いUTF-8などのシステムのデフォルト・エンコーディングの文字のみを使用する必要があります。
しかし「システムのデフォルト・エンコーディング」固定ということが分かっただけで、エンコーディングを指定する方法は書いていなかった。
また、関連してargfileの文字コードを読み取り側で解決するにはWindows側の設定を地域化するのがベストという情報が出て来てしまった。
Based on my experience, if you want to use Chinese file path or input/output Chinese characters in Java, the best way is to change your current system locale to Chinese.
書き込み側でargfileの正しいエンコーディングを取得する方法は無い
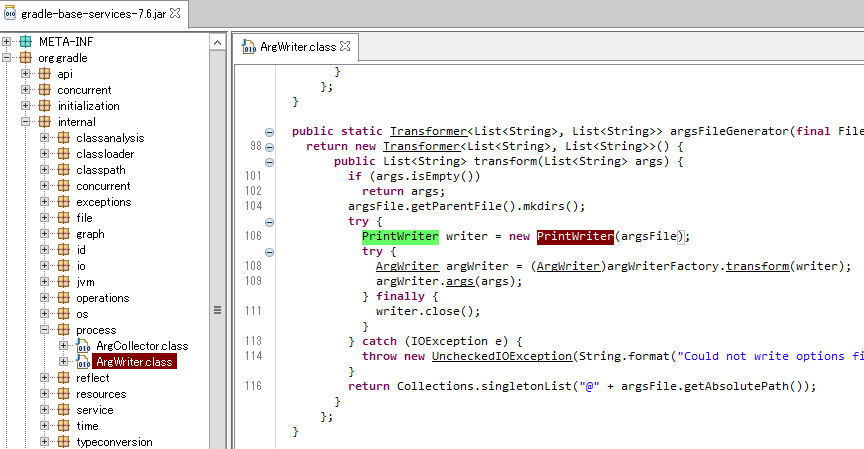
Gradle内では ArgWriter で書き込まれていたものの、オプションで指定するようなコードは書かれていなかった。
PrintWriter writer = new PrintWriter(argsFile);
これを使う限り、真っ当な手段ではホストJVMで指定された file.encoding がゲストJVMのコマンドライン引数のargfileに現れることになる。
Testタスクのこの挙動を切り替えることは理論上可能だが、少なくともこのメソッドの実装を記述しないといけないので簡単な記述にはならなそうだ。
また、「そもそもプラットフォーム固有のエンコーディングを無視して file.encoding を使うGradleのコードの方がバグってるんじゃないの?」という疑問が生じたが、JVM側にそんな機能無くて無理なようだ。
JavaにOSのデフォルトエンコーディングを知る方法が無い
いったんfile.encodingが変えられてしまうと、もはやOSのエンコーディングがわからなくなる。
file.encoding はそもそも書き換えてよいものではないというのが真理なようだ。
そうであれば、本来file.encodingの設定は絶対に行ってはならないはずなのだが。。。
file.encoding でプラットフォーム固有の文字コード以外を上書きされたJavaプロセスは、Javaの子プロセスを自由に呼び出せなくなってしまう。
同様のことはEclipseのGitHubでも5月に言及されている。
So far no reliably method to get the system Charset needed to start another JVM.
結局この問題は後述のJava 17まで残ったままだった。
sun.jnu.encoding 大作戦
ドキュメント化されていないプロパティ sun.jnu.encoding でコマンドライン引数をデコードするための文字コードを指定できるらしい。
しかし、これは結局うまく動かなかった。
そもそも -Dsun.jnu.encoding=UTF-8 自体がJVM引数なのに、どうやってJVM引数のエンコーディングを指定するんだ?
もし指定されたのがUTF-16だった場合自己言及のパラドックスになってしまう。
HTMLみたいに先頭から逐次的に解析して文字コードの指定が出て来た段階で設定し直すような仕組みがあるなら別だけど…
JVM引数のパースが逐次的に行われている事実は確認できず
argfileの内容は、バイト列のままコマンドライン引数の列に結合されるのが、↓の周囲で判明した。
ということは、「argfileの文字コード」を指定する方法は存在せず、コマンドライン引数の文字コードを設定すればよい。
しかし、逐次的にコマンドライン引数をパースして文字コードをその場で設定するようなコードをすぐには発見することはできなかった。
JVMに日本語環境であることを見失わせる大作戦
JVMが日本語環境のWindowsで動いていることを検出できなければ何とかなるのでは?
LinuxならLANG環境変数の上書きでいけるらしい
Linuxだと sun.jnu.encoding と環境変数 LANG の上書きとの併用で通るようだが、どっちにしろWindowsでは使えない。
JVMはWindowsの設定言語の取得にWin32 APIを使っている
Windowsで起こっているのでLANG環境変数は使えない。
cmdにおける環境変数では「実行中の端末の表示言語」を特定できる情報は無かったが、パワーシェルでは取得できた。
> Get-WinSystemLocale
LCID Name DisplayName
---- ---- -----------
1041 ja-JP 日本語 (日本)
そして、コード上からJVMではそのLCIDをGetUserDefaultLCIDというWin32 APIで取得していることが判明。
プラットフォーム固有の文字コードをUTF-8として認識する条件
プラットフォーム固有の文字コードをUTF-8と判定させるには、どうやらソースコード上で codepage という変数が途中で0か65001になればよいようだ。
そのためには、Win32 APIから返って来た値である lcid が0であり、かつコンソールのエンコーディングがUTF-8になっているか、 GetLocaleInfo(lcid, ...) がUTF-8になっている必要がある。
どちらにしろ実行環境依存で呼び出し側プログラムで設定する余地がない。
JVMは基本的にchcpの設定を無視する
そういえば chcp 65001 でコマンドプロンプトの文字コードがUTF-8になるらしい。
もしかしたらその状態でIntelliJを起動すれば、LCID=0な環境下であればうまくいくかもしれない。
しかし日本語環境では無理。
JVMはLCID=0であるような超特殊な環境でもない限りコマンドプロンプトの文字コード設定を無視するように見える。
実際、以下のような事例がある。
コマンドプロンプトのコードページを UTF-8 (65001) に変更してみましょう。
コマンドプロンプトのコードページを UTF-8 (65001) に変更したら文字化けがひどくなってしまいました😭
また、その記事では「Windows の文字コードを UTF-8 に変更するベータ機能」じゃ無理ということが検証されており、exewrapを使えば行けるという解決策が提示されていた。
しかしIntelliJでテストする際に文字化けで正しく動かない問題の解決には使えない。
「システムの文字コードが適切なら文字化けしないんじゃないの?」 というのが修正しない理由の 1 つになっているようです。
つまり、 日本語 Windows の文字コードが MS932 (≒Shift_JIS) になっているのが悪いと?
😭
また、こちらの記事でも残念な結論に落ち着いていた。
JAVAのデフォルトの文字コードは可変である
なので、(たとえ同一バージョンのJAVAであっても)デフォルトの文字コードが特定の何かであるかを期待することはできない。
環境変数の設定でUTF-8にする的な手段は無い
ビルドスクリプトから上書きしてOSの設定言語を見失わせることは無理そうだ。
そもそも特定のOSでのみ動作するコードをビルドスクリプトに含めること自体があまりエレガントではない。
Java 18大作戦
Java 18以降では native.encoding が追加
最近のJavaでは何らかの変更が加えられて良い感じになっているらしい。
デフォルトのcharsetは、UTF-8です。ただし、JDK 17以前のリリースでは、デフォルトの文字セットはJavaランタイムの起動時に決定されます。
Java 18では file.encoding がUTF-8になるらしい。
APIのデフォルトエンコーディングがUTF-8になりました
環境変数では、file.encodingがUTF-8になります。
native.encoding を使うと file.encoding で上書きされる前のプラットフォーム固有の文字コードが得られるようだ。
確かに file.encoding とは別に native.encoding が存在する。


これを使えばJavaプログラム側の努力によって標準出力にUTF-8で投げつつ、子プロセスのコマンドライン引数にはMS932を使うということが可能だ。
実験
Java 18に切り替えてみた。

Gradleも現時点での最新版である7.6を。
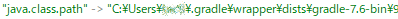
しかし子プロセスから見たときに解決はされなかった。

これが起こっているということは、依然としてGradleはUTF-8でargfileを生成しているということになる。
最新のGradleにおいて、argfileのエンコーディングへの変更は特に見られなかった。
また、Java 18でPrintWriter(File)した場合の文字コードを辿ってみたが、 native.encoding を参照してはいなかった。
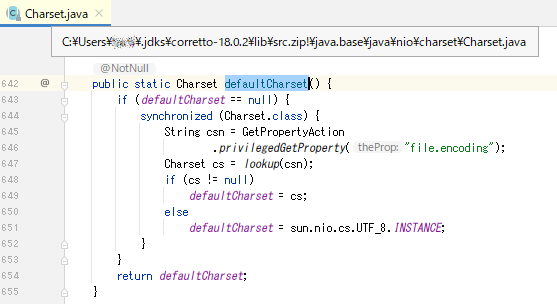
Javaプログラム側の努力で一応解決は可能になっている
Gradleがargfileを書き出す際に native.encoding があればそちらを優先するようになればいいのかもしれない。
理論上はビルドスクリプト上の記述によってテストタスクを改造してここの挙動を変えることで解決が可能だ。
結論
以下の条件が重なると、Java 17以前では解決不可能な文字コードの問題が生じる。
- 固有の文字コードを使う環境のWindows
- 子プロセスのJavaの引数の文字コードがプラットフォーム固有の文字コード固定となるため
- Windowsの日本ユーザーの大半は該当
- JavaからJavaの子プロセスを起動する
- Java内では
file.encodingで上書きされる前のプラットフォーム固有の文字コードを確実に取得する方法がないため - GradleのTestタスクなどが該当
- Java内では
- 引数やargfile内にマルチバイト文字を含めてJavaの子プロセスを起動する
- 日本語ファイルパスをclasspathに含める場合が該当
- プロジェクトを日本語フォルダ内に置いてGradleのTestタスクを普通に起動すると確実に踏む
- IntelliJで出力にUTF-8を使いたい
- テストに限らず、そのIntelliJが扱うプロジェクトのどこかで標準出力に🍰とかを出したい場合に該当
結果として、「日本語環境のWindowsでIntelliJのJVM引数で -Dfile.encoding=UTF-8 を設定すると、日本語ファイルパス上のプロジェクトをGradleから実行やテストができない」という問題が発生する。
場当たり的で現実的な妥協案
- Linuxでやる
- IntelliJのデバッグ機能を諦めて、コンソールからWSLを起動して
gradlew testする場合は発生しない
- IntelliJのデバッグ機能を諦めて、コンソールからWSLを起動して
- ファイルパスや引数にマルチバイト文字を含めない
- GradleのTestが実行できないだけの問題はプロジェクトを日本語パスに置かないだけで解決可能
- 令和の時代に日本語ファイルパスだと狂うプログラミング言語に遭遇するとは思わなかった
file.encodingを頑なにUTF-8にする場合、こちらを採用すれば一応表面上問題が解決する
- 標準出力にマルチバイト文字を使わず、
file.encodingを指定しない- IntelliJ側でこれを指定するとGradleのTestタスクが生成するargfileの文字コードも連動してそれになってしまい、日本語パスでバグってしまう
- 指定しなければargfileはMS932で出力されるので文字コードが一致するのでセーフ
- IntelliJの設定を弄ることになるので、当然影響範囲が広く無関係なプロジェクトの開発にも影響が出る
- 非常に不満だけど現状これが最も正しそう
- exewrapを使うと行けるらしい
- リリースする場合は使えるけど、テスト時の文字化けの解決にはならない
- 時間が解決するのを待つ
- 時代の流れは着実に改善に向かって進んでいるので、多分放っておけばそのうち解決する
どちらにしても、プロジェクト本体の問題ではなく開発環境を構築する側で何とかすべき問題なので、妥協の選択肢は多いと思う。
根本的な解決策
親JVMをJava 18以降にして、ビルドスクリプト上でGradleを native.encoding に従って子プロセスの引数をエンコードするように改造する。
現実的でない案
- Windowsの設定でロケールID(LCID)を0にしたうえで端末の文字コードをUTF-8にする
- そもそもそのような状況が起こりうるのかすら謎
- Windowsをマルチバイト文字のエンコーディングにUTF-8を使う言語に設定する
- 日本語環境では使えない
- 引数をURLエンコードしてしまう
- アプリケーションのコマンドライン引数であればこれで確実に渡せる
- JVMを改造しない限り結局classpath部分の挙動は変えられない
- Javaのラッパーである別のバッチファイルを指定してそこで引数を加工してJavaに渡す
- Windowsでこれが可能かは知らない
- JVMを改造してUTF-8で読むようにする
- JVMが引数のデコードに使う文字コードを環境変数で受け取れるようになってればいいのに(願望)
- Windowsのシステム設定に依存し、子プロセスを起動する際に一切上書きする手段がない
- 引数ではなく環境に依存するくせにchcpで変えた文字コードも無視してしまう
- Windowsの設定でUTF-8にしても無視するっぽいのも勿体無い