前回、オブジェクト検出で追加学習を行い、ゴルファーとゴルフボールだけを追い掛けるモデルを作成しました。
しかし、ゴルフのフォームのチェックをAIを使って実施するには、画像からゴルフスイングの動きを捉えることが必要です。
良いスイングとは何か?
誰に聞いても明確な答えが得られませんでした。人それぞれ体格や目標が違うから、見てみないとわからない、と。ではなぜ「レッスンプロ」という人が存在するのか?レッスンプロは人のゴルフスイングを見て、無意識に形を認識・分類し、独自の視点で良い点や矯正方法が思い浮かぶのだと思います。
これと同じことをAIに実行させるには、画像に写っている人物からゴルフのスイングを検出し、特徴点を把握して動きを捉える必要があります。さらに、おおよそこういう動きや角度なら「良いスイング」「ダメなスイング」と定義付ける必要もあります。
特徴点を検出する
TensorflowJSには、Posenetという姿勢推定AIがありますが、ゴルフの場合、どうしてもクラブヘッドの位置を捉えなければならないため、また、特に後方からスイング撮影するとPosenetでは検出出来ない部位があり、Posenetは使えません。
なので、後方からのアドレス画像に限定し、頭、腰、右足、グリップ、クラブヘッド、ボールを認識出来るよう、オブジェクト検出で追加学習を行いました。
学習用アノテーション部位は以下の通りです。いろいろなトッププロ100名の後方からのアドレス画像を使ってアノテーション化し、学習を行いました。
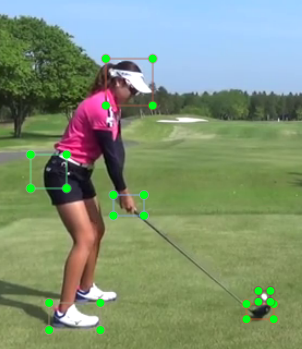
精度が上がらない原因
特徴点が悪いのか、そもそも部位の選択の仕方が悪いのか、精度が50%をなかなか超えません。
いろいろ試行錯誤の結果、オブジェクト検出をやっている人には常識なのかもしれませんが、対象となる人物画像やアノテーション部位の縦横サイズ大きさに大きく影響します。
つまり、人物引き気味の画像とアップ気味の画像が混在するアノテーションでは別のものとして認識するようで、なるべく画像の縦横幅を同じにし、映っている人物の大きさが同じになるよう選別し、学習実行すると90%を超える精度が出始めました。エポック数は14,000でした。学習に使っていない後方画像もしっかり認識しました。
以下の画像は、未学習写真です。
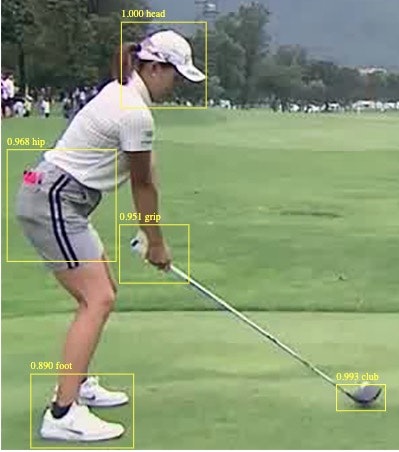
TensorflowJSに変換
ここまで出来上がったところで、モデルをJavascriptに変換します。前回苦慮した部分です。
Pythonよりも慣れていること、即WEBサービスとして使ってもらえること、がJavascriptを利用する理由です。
特徴点
四角形で囲められれば、あとは中心点を求めて点を描画するだけです。線で繋げてみます。
Javascript・Canvasの操作はお手の物です。

さらに100名分の特徴点を取得し、見て取れる角度の平均や標準偏差・相関を算出し、閾を設定すれば、良いアドレスのモデルは出来そうな気がします。
さらにこれら座標から算出出来るバランス感、分類を行い、自分のアドレスと比較、矯正方法を示唆してくれそうです。
今後連続写真を使えば、スイング全体の良し悪し判断出来るかも。