前回の記事では、データ基盤とAWS Glueの概要について説明しました。
今回はAWS Glueが提供する主要な機能の1つであるGlueジョブについてより詳しく説明したいと思います。
Glueジョブの概要
Glueジョブは、Pythonでプログラムを組むことでサーバレスでETL処理を実装できる機能です。
Lambdaと似たような機能ですが、ETLに特化したビルドイン機能やデータ処理に適したリソースの提供もしてくれる、データ処理に特化した機能になります。
時間ベースのスケジュールやイベントをトリガーにしてジョブを実行することも可能です。
4つのタイプのGlueジョブ
Glueジョブには以下4つのタイプの実行環境が用意されています。
・Spark
・Spark Streaming
・Ray
・Python Shell
Spark
PySparkを軸としたSparkシステム上で処理を行うジョブです。
PySparkおよびその拡張版であるglueのライブラリを使用することで、Spark分散処理の機能を利用できます。そのため必要となるような複数のインスタンス展開やdriverとexecutorの構成などはGlueがすべて提供してくれます。
ログやSpark Web UIなど、モニタリングや問題原因調査を行うための仕組みも併せて提供を受けられます。
なお、Sparkはscala(Java VM上で稼働する、オブジェクト指向と関数型の双方に親和性がある言語)用のSDKも提供しているため、scalaでの実装も可能になっています。
以下の資料が分かりやすくまとまっていると思います。合わせてご確認ください。
Sparkタイプで処理を実装する場合は、Apache Sparkの理解も必要になります。
Apache Sparkについても次回以降のセクションで説明したいと思います。
Spark Streaming
基本的な説明は上記のSparkタイプと同じです。
Spark Streamingでは連続的に実行されるストリーミングETLジョブを作成し、Amazon Kinesis Data Streams、Apache Kafka、 Amazon Managed Streaming for Apache Kafka (Amazon MSK) などのストリーミングソースからのデータを使用できます。
処理結果のデータを Amazon S3または JDBC データストアにロードすることが可能です。
また、Amazon Kinesis Data Streams ストリーム用のデータを生成することも可能です。
詳細については以下公式ドキュメントをご覧ください。
Ray
RayはPythonにおける分散並列処理を高速かつシンプルに書けるフレームワークで、既存のコードを並列化することも容易な設計となっています。
Sparkと比較して学習コストが低く、Pandasなど分析でよく使われているライブラリをそのまま並列処理化できる、ということで徐々に利用が進んでいるようです。
詳細については以下公式ドキュメントをご覧ください。
Python Shell
単純にPythonのスクリプトを実行するだけのジョブです。並列実行はできないため小規模な処理は可能ですが、大量のデータを処理する場合には不向きです。
詳細については以下公式ドキュメントをご覧ください。
ランタイム環境のバージョン
2024年8月現在、Glue4.0が最新バージョンとなっています。Glue4.0では以下のランタイム環境のバージョンが提供されています。
Spark環境の場合
・Spark3.3.0
・Python3.10
・Java8
Ray環境の場合
Ray2.4.0
Python3.9
Spark Shellの場合
Python3.9
詳細については以下公式ドキュメントをご覧ください。
Glueジョブのリソース
Glueジョブのリソースについては、DPUとワーカーという概念を抑えておく必要があります。
DPU
Glueジョブでは、DPU (Data Processing Unit)という単位でリソースが提供されます。
1DPUにつき4vCPUと16GBのメモリが提供されます。
また、ハイメモリDPU(M-DPU)というものもあり、4つのvCPUと32GBのメモリを提供します。M-DPUはRayタイプのジョブでのみ使用されます。
ワーカータイプとワーカー数
Glueジョブではリソースの設定として、ワーカータイプとワーカー数を指定します。
Sparkタイプで選択可能なワーカータイプ
G.025X:0.25DPU(64GBのディスク)※Spark Streamingでのみ選択可能
G.1X:1DPU(64GBのディスク)
G.2X:2DPU(128GBのディスク)
G.4X:4DPU(256GBのディスク)
G.8X:8DPU(512GBのディスク)
Rayタイプで選択可能なワーカータイプ
Z.2X:2M-DPU(128GBのディスク)
※Python Shellタイプではワーカータイプとワーカー数の選択はありません。1DPUまたは0.0625DPUのいずれかのDPU数を選択します。
Executorについて
Executorという概念も抑えておく必要があります。
1つのワーカーに、1つのExecutorが割り当てられます。
Executorというのは処理するマシンに相当するため、ワーカー数が10なら10個のマシンで並列処理するイメージです。
これはワーカータイプが大きくても小さくても1ワーカーにつき1Executorです。
以下のようなイメージです。
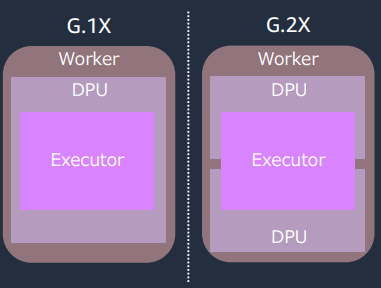
(引用元:https://d1.awsstatic.com/webinars/jp/pdf/services/202108_Blackbelt_glue_etl_performance2.pdf )
つまり同じDPU数(例えば1つのG.2Xワーカーと2つのG.1Xワーカー)であってもリソースの内部的な構成は変わることを留意しておく必要があります。
これはリソースのスケーリングをする際のパフォーマンスに影響します。
水平スケーリングと垂直スケーリング
高いデータ並列性が求められる処理の場合、水平スケーリング(より多くのワーカー数)の方がパフォーマンスが上がります。
また、多くのメモリを必要とする、多くのディスク領域を必要とする処理の場合、垂直スケーリング(より大きいワーカータイプ)の方がパフォーマンスが上がります。
同じプログラムでも、どのようなリソース設定をするかで性能とコストが大きく変わることがあるので、チューニング等の検証をすることはとても大事な作業です。
Glueジョブの料金
Glueジョブは従量課金制で、ジョブの実行時間に対してのみ料金が発生します。
リソース管理や初期費用は不要で、スタートアップ時間やシャットダウン時間も課金されません。
GlueジョブはDPUというデータ処理ユニットに基づいて、時間あたりの料金が発生します。
DPU数×処理時間(秒)= 料金
2024年8月現在、東京リーションでは以下のような料金になっています。
1DPU/秒 = 0.44USD
1M-DPU/秒 = 0.44USD
また、ジョブのタイプによって最低のDPU数があります。
・Apache Spark : 最低2DPU
・Apache Spark Streaming:最低2DPU
・Ray:最低2M-DPU
・Python Shell:1DPUまたは0.0625DPUのいずれかを選択(Python ShellはDPU数を自由に引き上げることができず、どちらかを選択する)
料金の詳細については以下公式ドキュメントをご覧ください。
さいごに
今回はGlueジョブの概要や種類、リソースについて説明しました。
次回では実際にETL処理をプログラムする際に必要な知識であるApache Sparkなどについて説明したいと思います。
参考記事