概要
Google翻訳と形態素解析の組み合わせでルー大柴Botを閃いたので作ってみた。
(何番煎じかは知らない…)
個人用Slackで淡々とことわざをルーさん風に翻訳して流してもらっている。
メンションを送ると、その文章を翻訳して返してくれる。
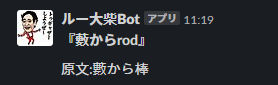
藪からスティックになって欲しかったけど、藪からrod。
たまに翻訳加減が絶妙なものが流れてくると思わず笑ってしまう。
『Fruit reportはsleepwait』
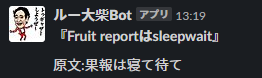
『BenkeiのStuck』
仕組み
当然といえば当然だが、GASではGoogle翻訳がとても簡単にできる。
LanguageApp.translate('文章', 'ja', 'en');
ルーさんの場合は、文章に含まれる特定の一部分だけを英訳する必要がある。
そこで使うのが自然言語解析。WebAPIとしていくつか公開されているが、
その中から「COTOHA API」というものを使用してみた。
リファレンスがとてもわかりやすく、特に迷うことなく使用できた。
COTOHA APIを通して文章の形態素とそれらの品詞情報を受け取る。
ざっくり言ってしまえば、名詞、動詞、形容詞だけを翻訳して再結合するだけでそれっぽくなる。
中身
function roux(text){
var json = getJson(text);
var resultArray = jsonToArray(json);
return convertRoux(resultArray);
}
function getJson(text) {
var properties = PropertiesService.getScriptProperties();
var accessToken = 'Bearer ' + properties.getProperty('access_token');
var url = properties.getProperty('APIBaseURL');
var body = { sentence: text };
var header = { Authorization: accessToken };
var payload = JSON.stringify(body);
var params = {
method: 'post',
contentType: 'application/json;charset=UTF-8',
headers: header,
payload: payload
};
var response = UrlFetchApp.fetch(url, params);
return(response.getContentText());
}
function jsonToArray(json) {
var jsonData = JSON.parse(json);
jsonData = jsonData["result"];
var ary = [];
for (var i in jsonData) {
var sub = jsonData[i]["tokens"];
for (var j in sub) {
ary.push([sub[j]["form"],sub[j]["pos"]])
j++;
}
j==0;
i++;
}
return ary
}
function convertRoux(resultArray){
var resultText = '';
var tmp = '';
resultArray.forEach(function(value){
switch (true) {
case /名詞/.test(value[1]): //名詞系は翻訳する
resultText = resultText + LanguageApp.translate(value[0], 'ja', 'en');
break;
case /形容詞語幹/.test(value[1]): //形容詞語幹はいったん無視し、次に来る形容詞接尾辞と合わせて翻訳する
tmp = value[0];
break;
case /形容詞接尾辞/.test(value[1]): //直前にある形容詞語幹と合わせて翻訳する
resultText = resultText + LanguageApp.translate(tmp + value[0], 'ja', 'en');
break;
case /動詞活用語尾/.test(value[1]): //動詞活用語尾は除外する
break;
case /動詞語幹/.test(value[1]): //動詞語幹はいったん無視し、次に来る動詞接尾辞と合わせて翻訳する
tmp = value[0];
break;
case /動詞接尾辞/.test(value[1]): //直前にある動詞語幹と合わせて翻訳する
resultText = resultText + LanguageApp.translate(tmp + value[0], 'ja', 'en');
break;
case /接尾辞/.test(value[1]): //ほか、接尾辞は除外する
break;
default:
resultText = resultText + value[0];
break;
}
});
return resultText
}
function roux(text)
本体。ここに日本語の文章を渡すと、ルー翻訳した結果を返してくれる。
function getJson(text) ~ function jsonToArray(json)
ここで文章をCOTOHA APIに渡して結果のjsonを取得している。
その後、jsonから各形態素とそれらの品詞情報を2次元配列にまとめている。
function convertRoux(resultArray)
ここで品詞ごとに以下3パターンの処理で仕分けしている。
- 翻訳する単語
- 翻訳しない単語
- 削除する単語
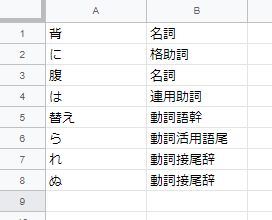
動詞、形容詞はそれぞれに語幹と接尾辞があるため、少し掘り下げて処理している。
突き詰めるともっと細かい法則が出てくると思うけど、ある程度雑さ加減があったほうがルーさんらしさになる。
補足
実際のBot化については割愛するが、Bot化する場合はアクセストークンの更新が必須。
COTOHA APIのトークンは24hの期限付きなので、
下記コードをトリガーで1日1回実行している。
ID系はスクリプトやスプレッドシートのプロパティに書き込むようにすると良い。
function refreshTaken() {
var properties = PropertiesService.getScriptProperties();
var url = properties.getProperty('AccessTokenPublishURL');
var body = { grantType: 'client_credentials', clientId: properties.getProperty('clientId'), clientSecret:properties.getProperty('clientSecret')};
var payload = JSON.stringify(body);
var params = {
method: 'post',
contentType: 'application/json',
payload: payload
};
var response = UrlFetchApp.fetch(url, params);
var jsonData = JSON.parse(response);
properties.setProperty('access_token', jsonData["access_token"]);
}