単語からそのカテゴリーを予測するRNN
PyTorch公式チュートリアルの人名から国籍を予測するRNN
事前準備
人名と国籍のテキストデータをダウンロードして、任意のフォルダに展開する
https://download.pytorch.org/tutorial/data.zip
ソースコード
処理の流れは以下のよう
- データを読み込む
- 基本的なAsciiコードのみになるよう変換
- Asciiコードの各文字に数字を割り当て、対応する数字で文字列をベクトル化
- RNNモデルを定義
- RNNモデルの学習
- 学習結果を可視化
- 特定の人名で推論
RNNで文字列を時系列で学習し、該当する国籍(数字)の確率をsoftmax関数で出力している。
#### 1. データ読み込みとユニコード正規化
# テキストデータは各国ごとに分かれていて、名前のリストが含まれている
from io import open
import glob
import os
import unicodedata
import string
def findFiles(path):
return glob.glob(path)
print('読み込みデータ\n', findFiles('data/names/*.txt'))
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
# ユニコードを基本的なAsciiコード(128文字)に変換
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn' and c in all_letters
)
# ファイルを受け取り、開いて中の文字列をAsciiコードに変換して、リストに格納
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
# カテゴリー毎にファイルが分かれているため、カテゴリー毎に学習データを辞書に保存
category_lines = {}
all_categories = []
for filename in findFiles('data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
print('\nすべてのカテゴリー : ', all_categories)
print('イタリアンに属する名前の一部 : ', category_lines['Italian'][:5])
#### 2. 単語をベクトル化
# 基本的なASCIIコードのみで、文字表を作成し、それぞれの文字に該当する数字を割り当て、文字列を数字のベクトル表現に変換する
import torch
# 基本的なASCIIコードの何番目にあたるかを返す
def letterToIndex(letter):
return all_letters.find(letter)
# 一文字を一次元のテンソルに変換する
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
# 文字列をN次元のテンソルに変換する
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
print('\n文字「J」のテンソル: ', letterToTensor('J'))
print('文字列「Jones」のテンソルサイズ : ', lineToTensor('Jones').size())
#### 3. RNNモデル定義
# シンプルなRNNを定義する
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.h2o = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.h2o(hidden)
# 最後にsoftmax関数で、カテゴリー(128個)分の確立を出力する
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
n_hidden = 128 # ASCIIコード(128文字)
rnn = RNN(n_letters, n_hidden, n_categories)
def categoryFromOutput(output):
# 上位1個の要素を返す
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i
#### 4. 学習
import random
import time
import math
# 交差エントロピー:Negative Log-Likelihood Loss
criterion = nn.NLLLoss()
# 学習率
learning_rate = 0.005
def train(category_tensor, line_tensor):
# 隠れテンソルを0に初期化
hidden = rnn.initHidden()
# モデル内のパラメータの勾配を初期化
rnn.zero_grad()
# 隠れテンソルを保持して、入力テンソルの一部(一文字分)と前の隠れテンソルを毎回入力する
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
# 損失を計算、ここで計算するのは、最終的に出力されたsoftmax関数の確率と正解の数字
loss = criterion(output, category_tensor)
# 誤差逆伝番
loss.backward()
# Add parameters' gradients to their values, multiplied by learning rate
# パラメータの勾配を値に加算し、学習率を乗算する
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item()
# ランダムにデータを取り出すだけの関数
def randomTrainingExample():
category = all_categories[random.randint(0, len(all_categories) - 1)]
line = category_lines[category][random.randint(0, len(category_lines[category]) - 1)]
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
# 経過時間を測るだけの関数
def timeSince(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
n_iters = 100000
current_loss = 0
all_losses = []
start = time.time()
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
# 定期的に学習モデルによる予測精度の確認
if iter % 5000 == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else '✗ (%s)' % category
print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# 損失関数の値をリストに格納
if iter % 1000 == 0:
all_losses.append(current_loss / 1000)
current_loss = 0
#### 5. 学習結果を可視化
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)
# 混同行列の作成
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000
# Just return an output given a line
def evaluate(line_tensor):
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
for i in range(n_confusion):
category, line, category_tensor, line_tensor = randomTrainingExample()
output = evaluate(line_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
# Normalize by dividing every row by its sum
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()
#### 6. 推論
def predict(input_line, n_predictions=3):
print('\n> %s' % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
# Get top N categories
topv, topi = output.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print('(%.2f) %s' % (value, all_categories[category_index]))
predictions.append([value, all_categories[category_index]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')
実行結果
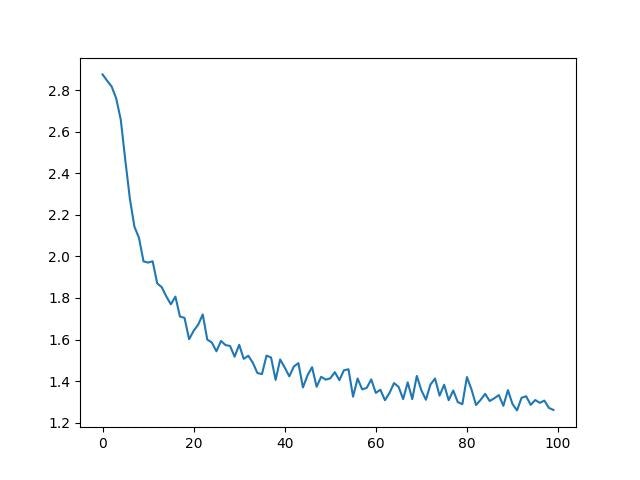
定期的に測定された損失の値を左から順番に描写
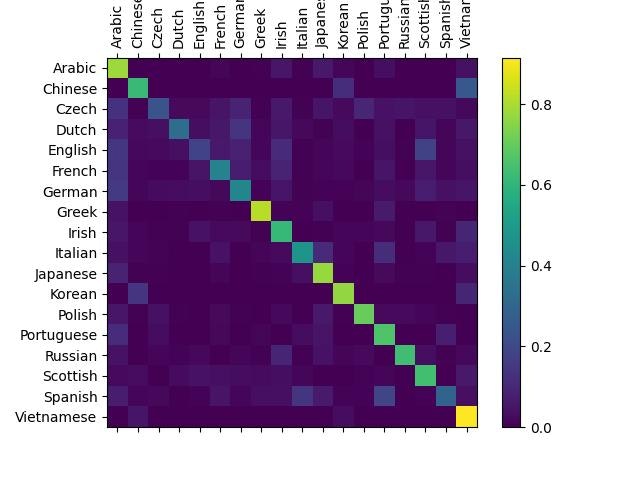
各カテゴリー(国籍)ごとに学習データからランダムに選んだデータで、softmax関数からの確立を計算し、平均をヒートマップで描写
> Dovesky
(-0.64) Czech
(-1.54) Russian
(-2.19) English
> Jackson
(-0.16) Scottish
(-2.68) English
(-3.72) Dutch
> Satoshi
(-0.59) Japanese
(-1.82) Arabic
(-1.85) Italian
単語からその次の文章を予測するRNN
下記サイトを参考に実装してみた。
import torch
from torch import nn
import numpy as np
#### 1. データ準備
text = ['hey how are you','good i am fine','have a nice day']
# 対象テキストをすべてつなげて、重複を削除し、使用されているすべての文字を取得
chars = set(''.join(text))
# それぞれに数字を割り当て、辞書型にする
int2char = dict(enumerate(chars))
char2int = {char: ind for ind, char in int2char.items()}
maxlen = len(max(text, key=len))
# すべての文字列の最後に半角空白を付与
for i in range(len(text)):
while len(text[i])<maxlen:
text[i] += ' '
# 入力データと正解ラベルのリストを作成
input_seq = []
target_seq = []
for i in range(len(text)):
input_seq.append(text[i][:-1])
target_seq.append(text[i][1:])
print("Input Sequence: {}\nTarget Sequence: {}".format(input_seq[i], target_seq[i]))
for i in range(len(text)):
input_seq[i] = [char2int[character] for character in input_seq[i]]
target_seq[i] = [char2int[character] for character in target_seq[i]]
dict_size = len(char2int)
seq_len = maxlen - 1
batch_size = len(text)
#### 2. テキストデータをベクトル化
def one_hot_encode(sequence, dict_size, seq_len, batch_size):
features = np.zeros((batch_size, seq_len, dict_size), dtype=np.float32)
for i in range(batch_size):
for u in range(seq_len):
features[i, u, sequence[i][u]] = 1
return features
input_seq = one_hot_encode(input_seq, dict_size, seq_len, batch_size)
input_seq = torch.from_numpy(input_seq)
target_seq = torch.Tensor(target_seq)
is_cuda = torch.cuda.is_available()
if is_cuda:
device = torch.device("cuda")
input_seq = input_seq.cuda()
else:
device = torch.device("cpu")
#### 3. モデル定義
class Model(nn.Module):
def __init__(self, input_size, output_size, hidden_dim, n_layers):
super(Model, self).__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_size)
def forward(self, x):
batch_size = x.size(0)
hidden = self.init_hidden(batch_size)
out, hidden = self.rnn(x, hidden)
out = out.contiguous().view(-1, self.hidden_dim)
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers, batch_size, self.hidden_dim)
hidden = hidden.to(device)
return hidden
model = Model(input_size=dict_size, output_size=dict_size, hidden_dim=12, n_layers=1)
model.to(device)
#### 4. 学習
n_epochs = 100
lr=0.01
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(1, n_epochs + 1):
optimizer.zero_grad()
output, hidden = model(input_seq)
output = output.to('cpu')
loss = criterion(output, target_seq.view(-1).long())
loss.backward()
optimizer.step()
if epoch%10 == 0:
print('Epoch: {}/{} '.format(epoch, n_epochs), end=' ')
print("Loss: {:.4f}".format(loss.item()))
#### 5. 推論
def predict(model, character):
character = np.array([[char2int[c] for c in character]])
character = one_hot_encode(character, dict_size, character.shape[1], 1)
character = torch.from_numpy(character)
character = character.to(device)
out, hidden = model(character)
prob = nn.functional.softmax(out[-1], dim=0).data
char_ind = torch.max(prob, dim=0)[1].item()
return int2char[char_ind], hidden
def seq_iteration(model, out_len, start='hey'):
model.eval()
start = start.lower()
chars = [ch for ch in start]
size = out_len - len(chars)
for ii in range(size):
char, h = predict(model, chars)
chars.append(char)
return ''.join(chars)
print(seq_iteration(model, 15, 'good'))
print(seq_iteration(model, 15, 'have'))
print(seq_iteration(model, 15, 'hey'))
print(seq_iteration(model, 15, 'hide'))
実行結果
good i am fine
have a nice day
hey how are you
hide aa e am fi
まとめ
今回は、PyTorch公式チュートリアルのRNNを用いた人名から国籍を予測するAIを紹介した。
参考文献